애플리케이션에 AI 검색 기능 구축
Elasticsearch Relevance Engine™(ESRE)은 인공지능 기반 검색 애플리케이션을 지원하도록 설계되었습니다. ESRE를 사용하면 즉시 시맨틱 검색을 적용하고, 외부 대규모 언어 모델(LLM)과 통합하고, 하이브리드 검색을 구현하고, 서드파티 또는 나만의 트랜스포머 모델을 사용할 수 있습니다.

Elasticsearch Relevance Engine 설정을 시작하는 것이 얼마나 쉬운지 알아보세요.
빠른 시작 동영상 보기ESRE를 사용하여 고급 RAG 기반 애플리케이션을 구축하세요.
교육 등록하기프라이빗 내부 데이터를 생성형 AI 모델의 기능과 함께 컨텍스트로 사용하여 사용자 쿼리에 대한 신뢰할 수 있는 최신 응답을 제공하세요.
동영상 보기모든 개발자를 위한 AI
AI로 검색 기능 향상
전문 지식 수준에 상관없이 ESRE를 통해 애플리케이션에 고급 AI 정확도 기능을 제공하세요. ESRE에는 AI를 이용한 경험을 바탕으로 시작하거나 구축하는 데 도움이 되는 일체의 기능이 있습니다. 머신 러닝과 생성형 AI 검색 앱을 원하는 대로 배포할 수 있는 유연성과 제어력을 갖추세요.



Elasticsearch Relevance Engine
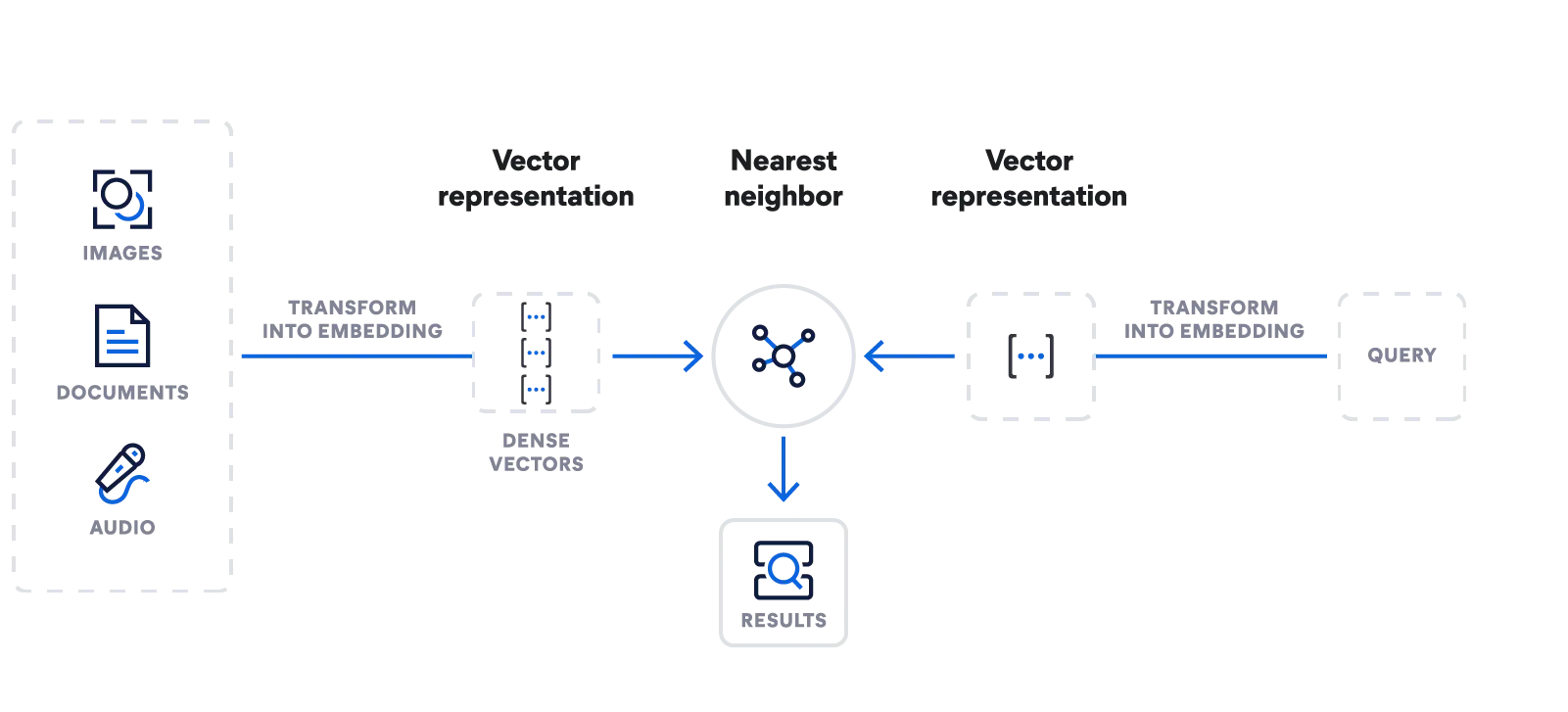
Elasticsearch - 강력한 올인원 벡터 검색 도구
임베딩을 생성하세요. 벡터를 저장, 검색 및 관리하세요. Elastic만의 Learned Sparse Encoder 머신 러닝 모델로 시맨틱 검색을 확보하세요. 모든 데이터 유형을 수집하세요. 빠르게 진화하는 대규모 언어 모델과 통합하세요.
코드 샘플
벡터 검색 빌드 시작
단일 API를 사용하여 임베딩 모델을 가져오고, 임베딩을 생성하며, 최근접 유사 항목(ANN) 검색을 사용하여 검색 쿼리를 작성하세요.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--cloud-id $CLOUD_ID \
-u <username> -p <password> \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--start자주 묻는 질문
Elasticsearch Relevance Engine은 개발자가 AI 검색 애플리케이션을 구축하는 데 도움이 되는 기능 세트이며 다음을 포함합니다.
- 모든 도메인에 대한 정확도가 높은 하이브리드 검색의 기반인 BM25를 사용한 기존 키워드 검색 등 업계를 앞서가는 고급 정확도 순위 지정 기능.
- 벡터의 저장 및 검색뿐만 아니라 임베딩을 만드는 기능을 포함한 전체 벡터 데이터베이스 기능.
- 다양한 도메인에서 시맨틱 검색을 위한 Elastic의 새로운 머신 러닝 모델인 Elastic Learned Sparse Encoder. 다양한 도메인에서 최적의 검색 정확도를 위해 벡터 및 텍스트 검색 기능을 쌍으로 구성하는 하이브리드 순위 지정(RRF).
- API를 통해 OpenAI GPT-3 및 4와 같은 서드파티 트랜스포머 모델 통합 지원.
- 데이터베이스 커넥터, 서드파티 데이터 통합, 웹 크롤러와 같은 데이터 수집 도구 전체 제품군 및 사용자 정의 커넥터를 생성하기 위한 API.
- 텍스트, 이미지, 시계열, 위치 정보, 멀티미디어 등 모든 유형의 데이터에 걸쳐 검색 애플리케이션을 구축하기 위한 개발자 도구.
Elasticsearch는 웹사이트(전자 상거래 제품 및 검색 등)와 내부 정보(고객 성공 지식 기반 시스템 및 엔터프라이즈 검색 등)를 위한 선도적인 검색 기술입니다. ESRE를 통해, Elastic은 AI 지원 검색 경험을 구축할 수 있는 도구 키트를 제공하고 있습니다. 사용자는 자신이 찾는 정보 종류에 대한 설명이나 질문 형식으로 쿼리를 자연어로 표현할 수 있습니다. 이 자연어 기능을 생성형 AI와 결합하여 사용자의 개인 또는 독점 데이터의 컨텍스트를 통해 이러한 모델의 기능을 더욱 향상시키세요.
예, Elasticsearch Relevance Engine에 포함된 기능은 Elasticsearch 내의 _search API에서 설계되고 통합되었습니다. 개발자는 Elastic API 또는 Kibana와 같은 친숙한 도구를 사용하여 원활한 경험을 위해 Elasticsearch와 함께 Elasticsearch Relevance Engine을 구성하는 기능과 상호 작용할 수 있습니다.
Elastic Learned Sparse Encoder는 다양한 도메인에서 높은 정확도의 시맨틱 검색을 위해 Elastic이 구축한 모델입니다. 현재는 영어 전용 머신 러닝 모델로, 정보 검색을 위해 의미와 단어 간의 관계를 캡처합니다. Elastic의 새로운 검색 모델을 사용한 벤치마크 테스트에 관심이 있으신가요? 자세한 내용은 이 블로그를 읽어보세요.
트랜스포머는 LLM의 기초 역할을 하는 심층 신경망 아키텍처입니다. 트랜스포머는 다양한 구성 요소로 이루어지며, 인코더, 디코더 및 수백만(또는 수십억) 개의 매개 변수를 가진 많은 “심층” 신경망 계층으로 구성될 수 있습니다. 일반적으로 인터넷의 데이터와 같은 매우 큰 텍스트 말뭉치에 대해 훈련되며, 다양한 NLP 작업을 수행하도록 미세 조정될 수 있습니다. Elastic의 새로운 검색 모델은 트랜스포머 아키텍처를 사용하지만 광범위한 도메인에서 시맨틱 검색을 위해 특별히 설계된 인코더로만 구성됩니다.
Elasticsearch Relevance Engine의 모든 기능은 8.8 릴리즈의 일부로 Elastic Enterprise Search Platinum 및 Enterprise 플랜과 함께 제공됩니다. 임베딩과 벡터 검색을 쉽게 시작할 수 있고, 검색 모델 모델을 사용해 볼 수 있습니다. Elastic Learned Sparse Encoder의 기능 데모를 확인해 보세요. Elasticsearch 라이선스가 있는 경우, Elasticsearch Relevance Engine이 구매의 일부로 포함되어 있습니다.