Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
GraphQL offers an efficient and flexible way to query data. This blog will explain how Hasura DDN works with Elasticsearch to make high performing and metadata-driven access to data.
The code and setup for this example can be found on this GitHub repo - elasticsearch-subgraph-example.
Hasura DDN is a metadata-driven data access layer built for the cloud. It automatically generates APIs that support both transactional and analytical workloads. By leveraging the metadata—such as models, relationships, permissions, and security rules—Hasura creates APIs that are optimized for performance, delivering low-latency responses and handling high-concurrency demands with ease.
Role of metadata-driven APIs in search AI world
Instead of manually coding each endpoint and its associated logic, metadata-driven APIs use a declarative approach. The structure of your data sources (like the Elasticsearch indices) is described in a standardized format. Relationships between different entities are defined. Permissions and security rules are specified at a granular level, all using configuration.
Based on this metadata, the API layer is automatically provisioned and kept in sync with your data sources.
For Elasticsearch, using Hasura DDN’s metadata-driven APIs provide unified and consistent data access. Changes in data are immediately reflected in the API, which is crucial for real-time search and AI applications.
Architecture
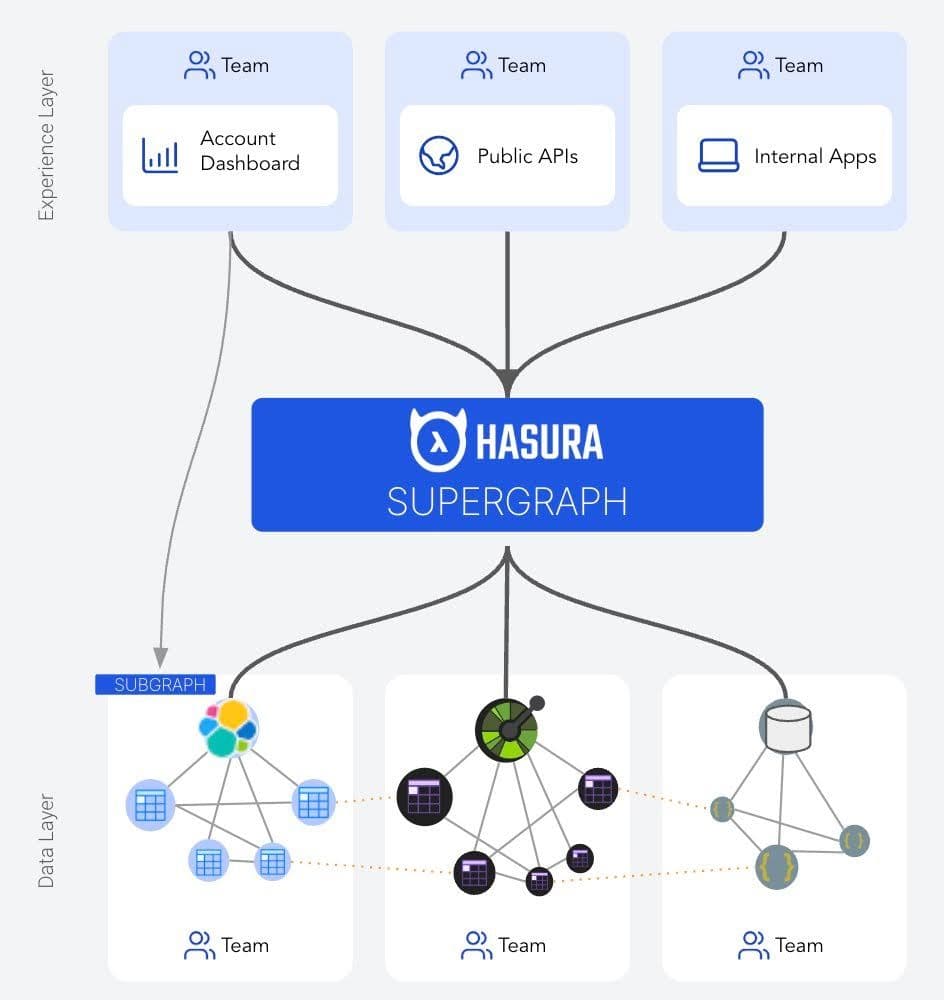
In the architecture above, Hasura is the Supergraph that connects to multiple subgraphs, Elasticsearch being one of the data sources in a subgraph.
Setup a GraphQL API for Elasticsearch
This setup walks you through connecting Hasura DDN to a locally running Elasticsearch instance using Docker. However, you can easily switch to Elastic Cloud by updating the environment variables with the right credentials. Using Elastic Cloud is the recommended way to experience Elasticsearch in production environments, offering a managed, scalable, and secure deployment.
Setup: Loading sample dataset
Copy .env.example to .env and set values for ELASTICSEARCH_PASSWORD
Start elasticsearch locally with sample indices
Visit http://localhost:9200 to verify that Elasticsearch is running with sample data.
GraphQL subgraph for Elasticsearch
In this section, we'll set up a GraphQL subgraph that connects Hasura DDN to your Elasticsearch instance. A subgraph allows you to expose Elasticsearch as a queryable API, providing a flexible and efficient way to perform complex searches, aggregations, and filtering through GraphQL.
Pre-requisites:
- Hasura CLI [Install from here]
- Login and authenticate using
ddn auth login
Initialize a Supergraph
Initialize Elasticsearch Connector
In the quickstart wizard, enter the following values for environment variables:
To use Elastic Cloud instead of a local instance, simply modify the environment variables in your .env file. Replace the ELASTICSEARCH_URL, ELASTICSEARCH_USERNAME, and ELASTICSEARCH_PASSWORD values with the corresponding credentials from your Elastic Cloud deployment.
Hasura DDN connected to Elasticsearch for introspecting and generating GraphQL APIs.
Introspect the Elasticsearch instance and track all indices and collections
Start Supergraph locally:
Build Supergraph locally:
Visit https://console.hasura.io/local/graphql?url=http://localhost:3000 to start exploring the local supergraph.
GraphQL queries for search
Now that we have set up our Hasura DDN and applied the metadata-driven APIs to Elasticsearch, let's craft GraphQL queries to perform search operations.
The following queries highlight how Hasura translates even complex search and aggregation requirements into simple, declarative GraphQL operations. These examples showcase not only the flexibility of GraphQL, but also the standardization Hasura brings, enabling consistent API access across different data sources.
Fetch 5 products (simple query)
Fetch 5 products whose product name matches the term “shoes” (search query with phrase match)
Fetch an aggregate of products matching a filter criteria (aggregate query)
Note: This integration is not limited to search APIs and can be extended to logging and observability data use cases in Elasticsearch.
Hasura's support for composability and standard APIs makes it possible to connect multiple data sources (Postgres, MongoDB, REST, etc.) with Elasticsearch, building a larger Supergraph that serves cross-team needs. This composability reduces technical debt by allowing different teams to access the same API endpoints and data sources in a consistent, standardized way.
Whether you're building search experiences or advanced analytics dashboards, Hasura enables your team to focus on application logic rather than API management, improving speed-to-market and reducing operational complexity.
Hasura & Elasticsearch performance considerations at scale
One of the key benefits of combining Hasura and Elasticsearch is the optimized performance through predicate pushdown. Hasura DDN intelligently compiles and pushes filters, limits, and sorts directly to Elasticsearch, reducing the overhead of N+1 queries and minimizing data over-fetching.
For instance, the following GraphQL query:
Generates an Elasticsearch query similar to:
By requesting only the necessary fields (_source) and limiting the number of documents fetched (size), Hasura ensures that Elasticsearch performs optimally. This is a significant improvement over traditional, manually-coded APIs, where each new requirement demands additional hand-written queries.
Summary
As explored in this post, the Hasura DDN connector for Elasticsearch opens up new possibilities in accelerating the GraphQL APIs for Elasticsearch and building a larger Supergraph in the organization, collaborating with multiple teams.
Hasura's metadata-driven approach simplifies API development, providing a fast, consistent, and secure layer for accessing Elasticsearch data through GraphQL. By leveraging predicate pushdown, Hasura ensures optimal search performance. Learn more about Hasura’s capabilities for Elasticsearch.
We're excited to see what you'll build!
Frequently Asked Questions
What is Hasura DDN?
Hasura DDN is a metadata-driven data access layer built for the cloud. It automatically generates APIs that support both transactional and analytical workloads.
Related Content

March 13, 2026
Entity resolution with Elasticsearch, part 4: The ultimate challenge
Solving and evaluating entity resolution challenges in a highly diverse “ultimate challenge” dataset designed to prevent shortcuts.

March 4, 2026
Entity resolution with Elasticsearch, part 3: Optimizing LLM integration with function calling
Learn how function calling enhances LLM integration, enabling a reliable and cost-efficient entity resolution pipeline in Elasticsearch.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.