From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
Cohere's Rerank 3 model rerank-english-v3.0 is now available in their Rerank endpoint. As the only vector database included in Cohere’s Rerank 3 launch, Elasticsearch has integrated seamless support for this new model into our open Inference API.
So briefly, what is reranking? Rerankers take the ‘top n’ search results from existing vector search and keyword search systems, and provide a semantic boost to those results. With good reranking in place, you have better ‘top n’ results without requiring you to change your model or your data indexes – ultimately providing better search results you can send to large language models (LLMs) as context.
Recently, we collaborated with the Cohere team to make it easy for Elasticsearch developers to use Cohere’s embeddings (available in Elasticsearch 8.13 and Serverless!). It is a natural evolution to include Cohere’s incredible reranking capabilities to unlock all of the tools necessary for true refinement of results past the first-stage of retrieval.
Cohere’s Rerank 3 model can be added to any existing Elasticsearch retrieval flow without requiring any significant code changes. Given Elastic’s vector database and hybrid search capabilities, users can also bring embeddings from any 3rd party model to Elastic, to use with Rerank 3.
Elastic’s approach to hybrid search
When looking to implement RAG (Retrieval Augmented Generation), the strategy for retrieval and reranking is a key optimization for customers to ground LLMs and achieve accurate results. Customers have trusted Elastic for years with their private data, and are able to leverage several first-stage retrieval algorithms (e.g. for BM25/keyword, dense, and sparse vector retrieval). More importantly, most real-world search use cases benefit from hybrid search which we have supported since Elasticsearch 8.9.
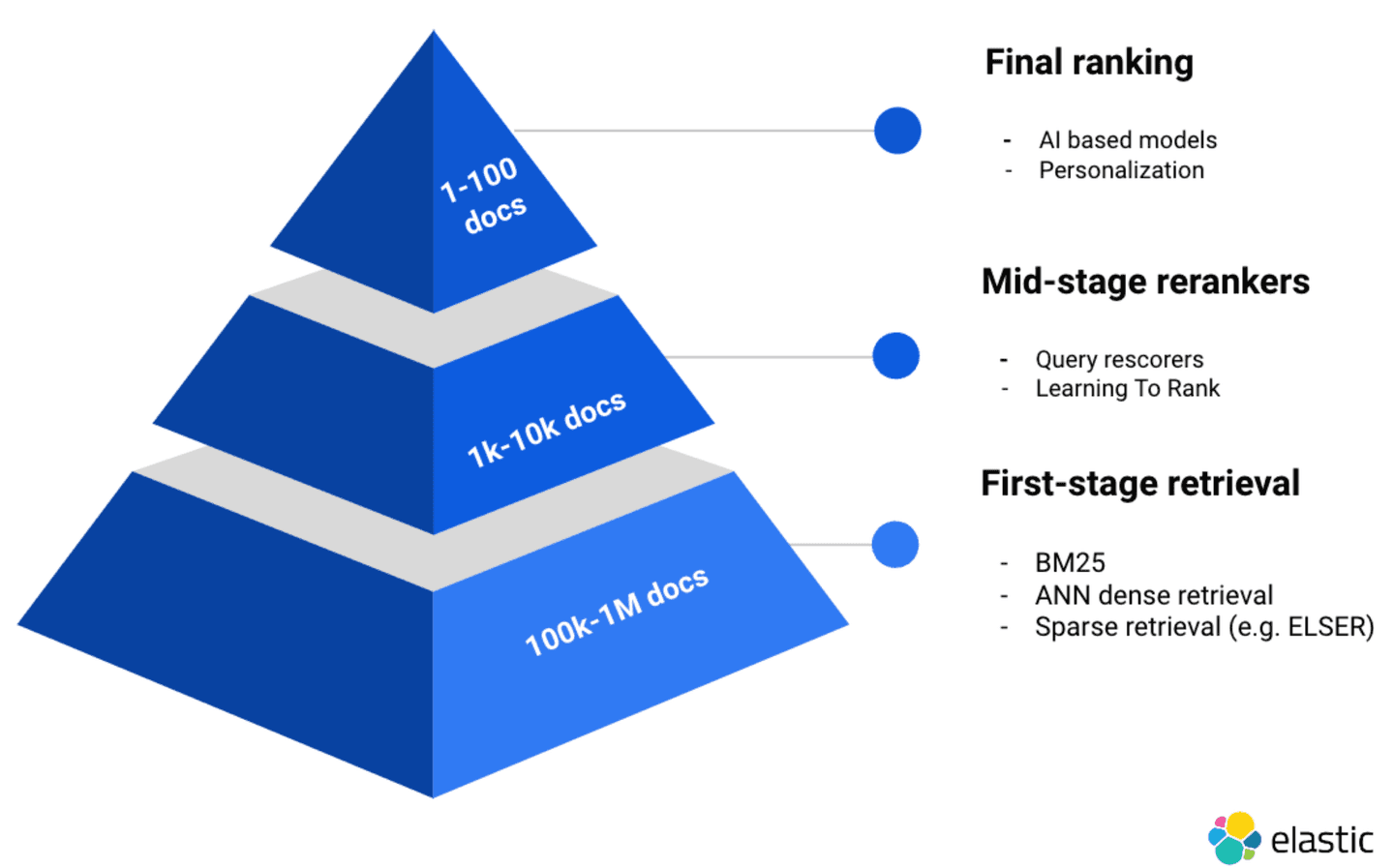
For mid-stage reranking, we also offer native support for Learning To Rank and query rescore. In this walkthrough, we will focus on Cohere’s last stage reranking capabilities, and will cover Elastic’s mid stage reranking capabilities in a subsequent blog post!
Cohere’s approach to reranking
Cohere has seen phenomenal results with their new Rerank model. In the testing, Cohere is reporting that reranking models in particular benefit from long context. Chunking for model token limits is a necessary constraint when preparing your document for dense vector retrieval. But with Cohere’s approach for reranking, a considerable benefit to reranking can be seen based on context contained in the full document, rather than a specific chunk within the document. Rerank has a 4k token limit to enable the input of more context to unlock the full relevance benefits of incorporating this model into your Elasticsearch based search system.
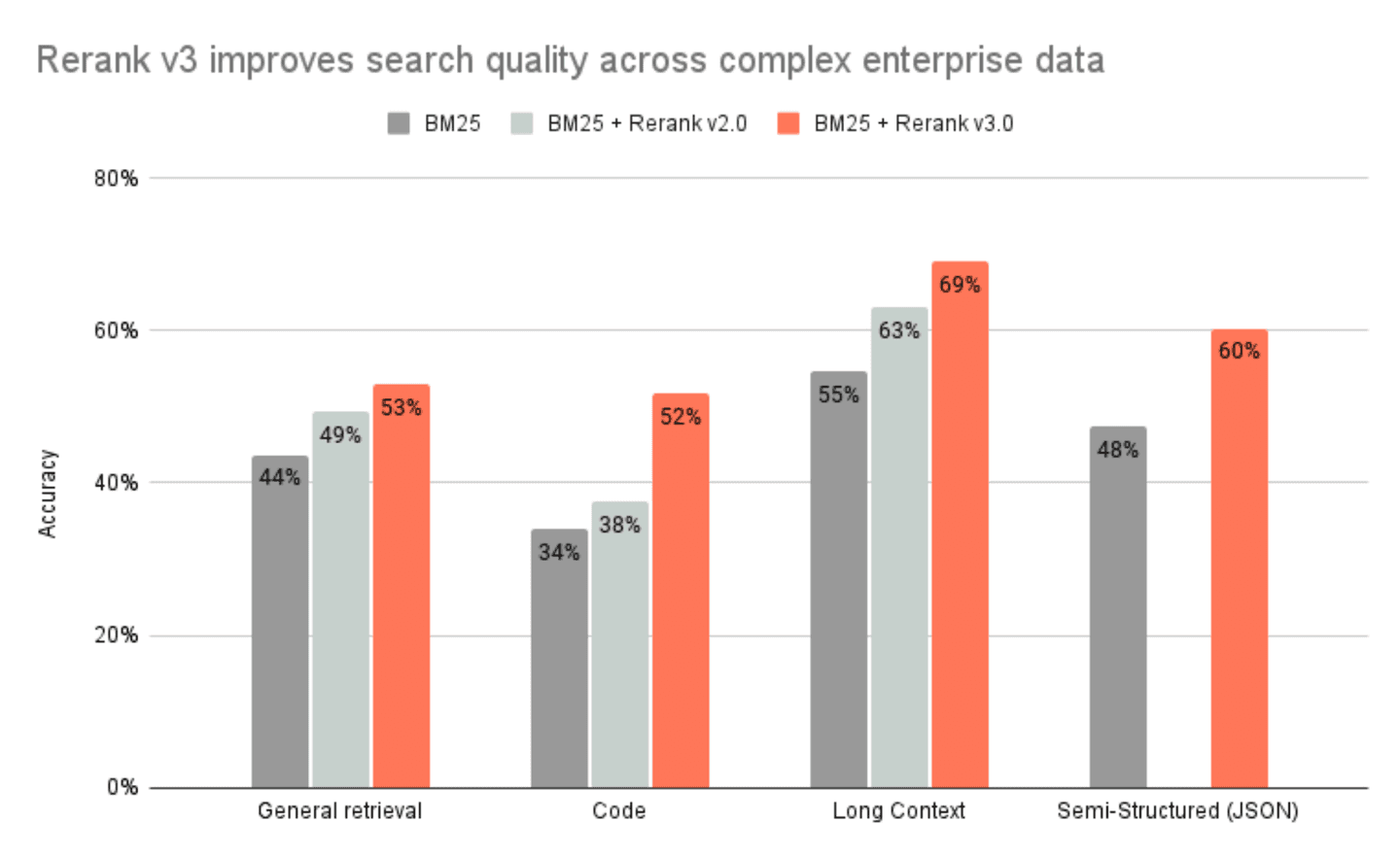
(i) General retrieval based on BEIR benchmark; accuracy measured as nDCG@10
(ii) Code retrieval based on 6 common code benchmarks; accuracy measured as nDCG@10
(iii) Long context retrieval based on 7 common benchmarks; accuracy measured as nDCG@10
(iv) Semi-structured (JSON) retrieval based on 4 common benchmarks; accuracy measured as nDCG@10
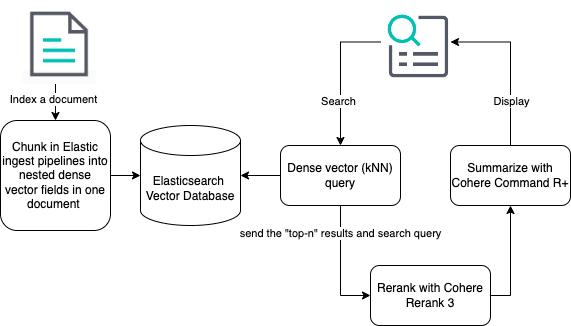
If you’re interested in how to chunk with LangChain and LlamaIndex, we provide chat application reference code, integrations and more in Search Labs and our open source repository. Alternatively, you can leverage Elastic’s passage retrieval capabilities and chunk with ingest pipelines.
Building a RAG implementation with Elasticsearch and Cohere
Now that you have a general understanding of how these capabilities can be leveraged, let’s jump into an example on building a RAG implementation with Elasticsearch and Cohere.
You'll need a Cohere account and some working knowledge of the Cohere Rerank endpoint. If you’re intending to use Cohere’s newest generative model Command R+ familiarize yourself with the Chat endpoint.
In Kibana, you'll have access to a console for you to input these next steps in Elasticsearch even without an IDE set up. If you prefer to use a language client - you can revisit these steps in the provided guide.
Elasticsearch vector database
In an earlier announcement, we had some steps to get you started with the Elasticsearch vector database. You can review the steps to cover ingesting a sample books catalog, and generate embeddings using Cohere’s Embed capabilities by reading the announcement. Alternatively, if you prefer we also provide a tutorial and Jupyter notebook to get you started on this process.
Cohere reranking
The following section assumes that you’ve ingested data and have issued your first search. This will give you a baseline as to how the search results are ranked with your first dense vector retrieval.
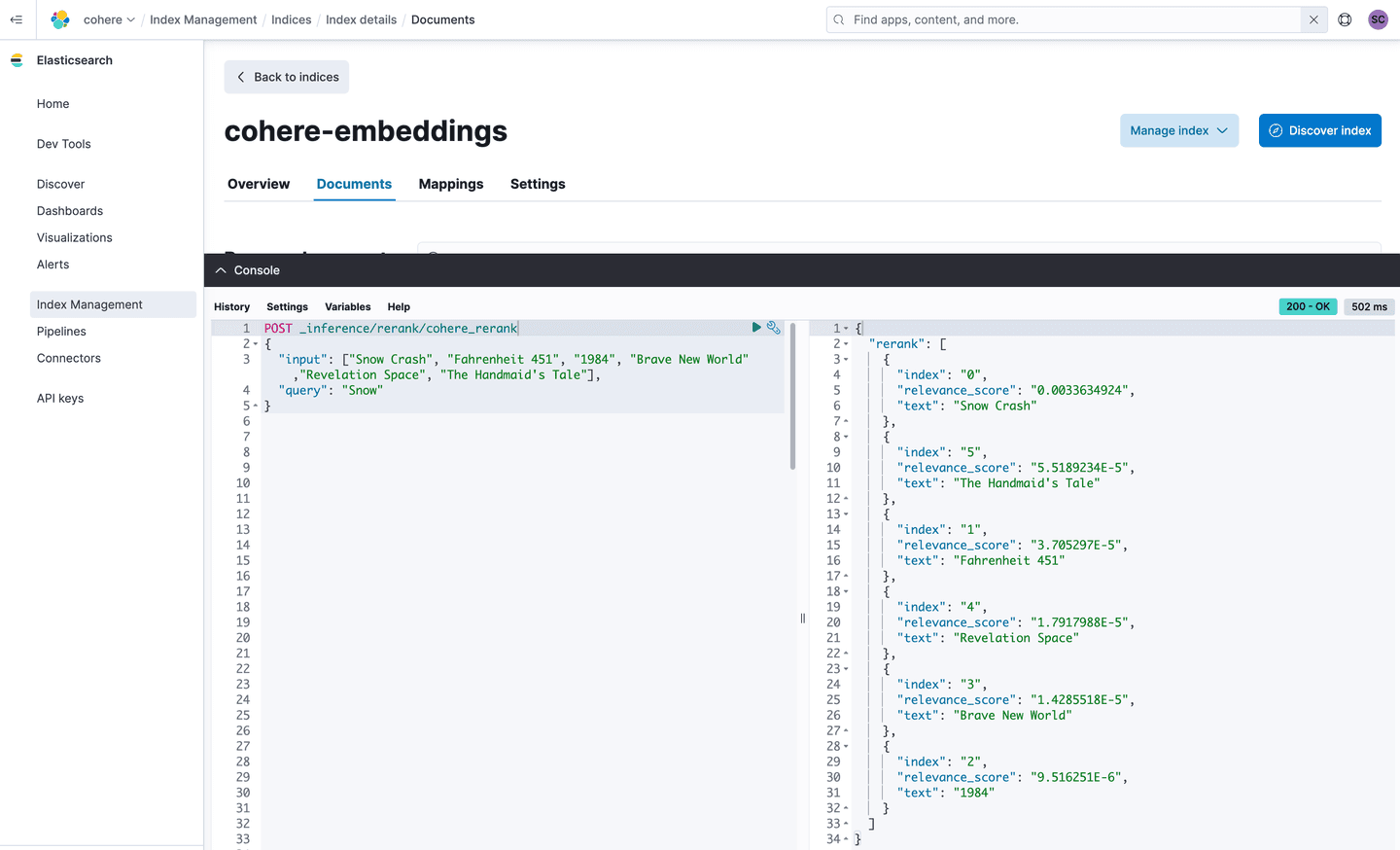
The previous announcement concluded with a query issued against the sample books catalog, and, and generated the following results in response to the query string “Snow”. These results are returned in descending order of relevance.
You’ll next want to configure an inference endpoint for Cohere Rerank by specifying the Rerank 3 model and API key.
Once this inference endpoint is specified, you’ll now be able to rerank your results by passing in the original query used for retrieval, “Snow” along with the documents we just retrieved with the kNN search. Remember, you can repeat this with any hybrid search query as well!
To demonstrate this while still using the dev console, we’ll do a little cleanup on the JSON response above.
Take the hits from the JSON response and form the following JSON for the input, and then POST to the cohere_rerank endpoint we just configured.
And there you have it, your results have been reranked using Cohere's Rerank 3 model.
The books corpus that we used to illustrate these capabilities does not contain large passages, and is a relatively simple example. When instrumenting this for your own search experience, we recommend that you follow Cohere’s approach to populate your input with the context from the full documents returned from the first retrieved result set, not just a retrieved chunk within the documents.
Elasticsearch’s accelerated roadmap to semantic reranking and retrievers
In upcoming versions of Elasticsearch we will continue to build seamless support for mid and final stage rerankers. Our end goal is to enable developers to have the ability to use semantic reranking to improve the results from any search whether it is BM25, dense or sparse vector retrieval, or a combination with hybrid retrieval. To provide this experience, we are building a concept called retrievers into the query DSL. Retrievers will provide an intuitive way to execute semantic reranking, and will also enable direct execution of what you’ve configured in the open inference API in the Elasticsearch stack without relying on you to execute this in your application logic.
When incorporating the use of retrievers in the earlier dense vector example, this is how different the reranking experience can be:
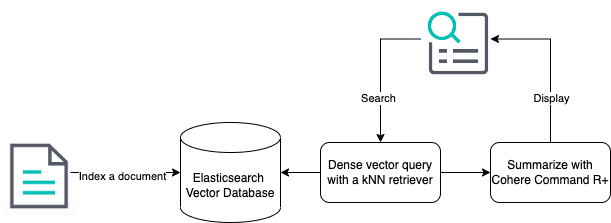
(i) Elastic’s roadmap: The indexing step is simplified with the addition of Elastic’s future capabilities to automatically chunk indexed data
(ii) Elastic’s roadmap: The kNN retriever specifies the model (in this case Cohere’s Rerank 3) that was configured as an inference endpoint
(iii) Cohere’s roadmap: The step between sending the resulting data to Cohere’s Command R+ will benefit from a planned feature named extractive snippets which will enable the user to return a relevant chunk of the reranked document to the Command R+ model
This was our original kNN dense vector search executed on the books corpus to return the first set of results for “Snow”.
As explained in this blog, there are a few steps to retrieve the documents and pass on the correct response to the inference endpoint. At the time of this publication, this logic should be handled in your application code.
In the future, retrievers can be configured to use the Cohere rerank inference endpoint directly within a single API call.
In this case, the kNN query is exactly the same as my original, but the cleansing of the response before input to the rerank endpoint will no longer be a necessary step. A retriever will know that a kNN query has been executed and seamlessly rerank using the Cohere rerank inference endpoint specified in the configuration. This same principle can be applied to any search, BM25, dense, sparse and hybrid.
Retrievers as an enabler of great semantic reranking is on our active and near term roadmap.
Cohere’s generative model capabilities
Now you’re ready with a semantically reranked set of documents that can be used to ground the responses for the large language model of your choice! We recommend Cohere’s newest generative model Command R+. When building the full RAG pipeline, in your application code you can easily issue a command to Cohere’s Chat API with the user query and the reranked documents.
An example of how this might be achieved in your Python application code can be seen below:
This integration with Cohere is offered in Serverless and soon will be available to try in a versioned Elasticsearch release either on Elastic Cloud or on your laptop or self-managed environment. We recommend you use our Elastic Python client v0.2.0 against your Serverless project to get started!
Happy reranking!
Frequently Asked Questions
What are rerankers?
Rerankers take the ‘top n’ search results from existing vector search and keyword search systems, and provide a semantic boost to those results.
Related Content
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.