From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
How to choose the best
Vector search has emerged as a game-changer in the current generative AI/ML world. It allows us to find similar items based on their semantic meaning rather just exact keyword matches.
Elasticsearch's k-Nearest Neighbors (kNN) algorithm is a foundational ML technique for classification and regression tasks. It found a significant place within Elasticsearch's ecosystem with the introduction of vector search capabilities. Introduced in Elasticsearch 8.5, kNN based vector search allows users to perform high-speed similarity searches on dense vector fields.
Users can find documents in the index "closest" to a given vector by leveraging the kNN algorithm using an underlying specified distance metric such as Euclidean or Cosine similarity. This feature marked a pivotal advancement as it is particularly useful in applications requiring semantic search, recommendations and other use cases such as anomaly detection.
The introduction of dense vector fields and k-nearest neighbor (kNN) search functionality in Elasticsearch has opened new horizons for implementing sophisticated search capabilities that go beyond traditional text search.
This article delves into strategies for selecting the optimal values for k and num_candidates parameters, illustrated with practical examples using Kibana.
kNN search query
Elasticsearch provides a kNN search option for nearest-neighbors - something like the following:
As the snippet shows, the knn query fetches the relevant results for the query in question (having a movie title as "Good Ugly") using vector search. The search is conducted in a multi-dimensional space, producing the closest vectors to the given query vector.
From the above query, notice two attributes: num_candidates which is the initial pool of candidates to consider and k, the number of nearest neighbors.
kNN critical parameters - k and num_candidates
To leverage the kNN feature effectively, one requires a nuanced understanding of the two critical parameters: k - the number of global nearest neighbors to retrieve, and num_candidates - the number of candidate neighbors considered for each shard during the search.
Choosing the optimal values for the k and num_candidates involves balancing precision, recall, and performance. These parameters play a crucial role to efficiently handle high-dimensional vector spaces commonly found in machine learning applications.
The optimal value for k largely depends on the specific use case. For example, if you're building a recommendation system, a smaller k (e.g., 10-20) might be sufficient to provide relevant recommendations. In contrast, for a use case where you'd want clustering or outlier detection capabilities, you might need a larger k.
Note that the higher k value can significantly increase both computation and memory usage, especially with large datasets. It's important to test different values of k to find a balance between result relevance and system resource usage.
K: Unveiling the closest neighbors
We have an option of choosing the k value as per our requirements. Sometimes, setting up a lower k value receives more or less exactly what you want with the exception that a few results might not make it to the final output. However, setting up a higher k value might broaden your search results in numbers, with a caveat that you may receive diversified results at times.
Imagine you're searching for a new book in the vast library of recommendations. k, also known as the number of nearest neighbors, determines how many books you'll be presented with. Think of it as the inner circle of your search results. Let's see how setting the lower and higher k values affects the number of books that the query returns.
Setting lower K
The lower K setting prioritizes extreme precision - meaning we will receive a handful of books that are the most similar to our query vector. This ensures a high degree of relevance to our specific interests. This might be ideal if you're searching for a book with a very specific theme or writing style.
Setting higher K
With a larger K value, we will be fetching a broader exploration result set. Note that the results might not be as tightly focused on your exact query. However, you'll encounter a wider range of potentially interesting books. This approach can be valuable for diversifying your reading list and discovering unexpected gems, perhaps.
Whenever we say higer or lower values of k, we mean the actual values depends on multiple factors, such as size of the data sets, available computing power and other factors. In some cases, the k=10 might be a large but in others it might be small too. So, do keep a note of the environmnet that this parateter is expected to operate.The
While k determines the final number of books you see, num_candidates plays a crucial role under the hood. It essentially defines the search space per shard – the initial pool of books in a shard from which the most relevant K neighbors are identified. When we issue the query, we are expected to hint Elasticsearch to run the query amongst top "x" number of candidates on each shard.
For example, say our books index contains 5000 books evenly distributed amongst five primary shards (i.e., ~1000 books per shard). When we are performing a search, obviously choosing all 1000 documents for each shard is neither a viable nor a correct option. Instead, we will be pick up to say 25 documents (which is our num_candidates) from the 1000 documents. That amounts to 125 documents as our total search space (5 shards times 25 documents each).
We will let the kNN query know to choose the 25 documents from each shard and this number is the num_candidates parameter. When the kNN search is executed, the "coordinator" node sends the request query to all of the involved shards. The num_candidates documents from each shard will constitute the search space and the top k documents will be fetched from that space. Say, if k is 3, the top 3 documents out of the 25 candidate documents will be selected in each shard and returned to the coordinator node. That is, the coordinator node will receive 15 documents in total from all the involved nodes. These top 15 documents are then ranked to fetch the global top 3 (k==3) documents.
The process is depicted in the following figure:
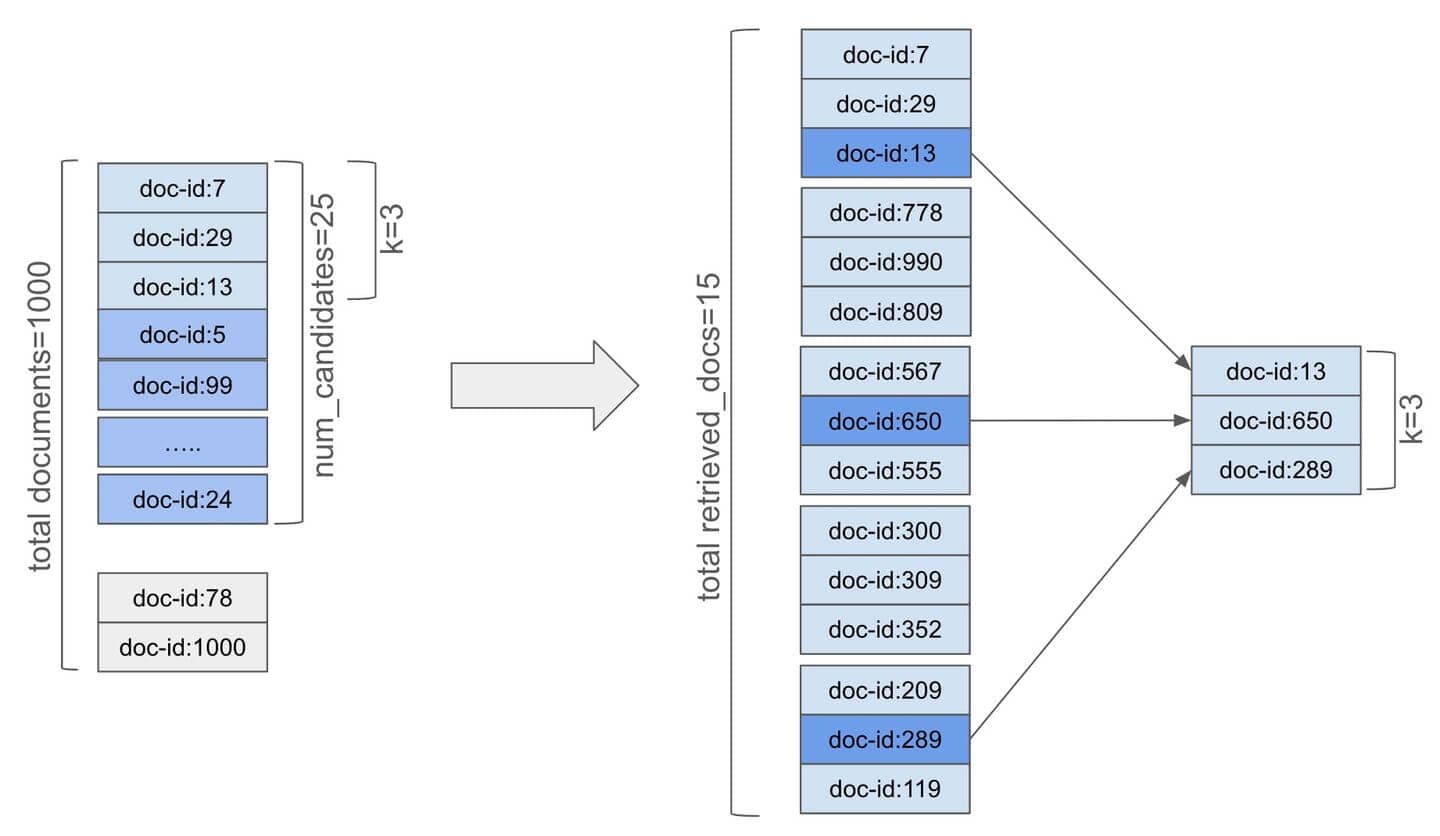
Here's what num_candidates means for your search:
Setting the lower num_candidates
This approach might restrict the search space, potentially missing some relevant books that fall outside the initial exploration set. Think of it as surveying a smaller portion of the library's shelves.
Setting the higher num_candidates
A higher num_candidates value increases the likelihood of finding the true nearest neighbors within our chosen K. It expands the search space - that is - more number of candidates are considered - and hence leads to a slight increase in search time. So, a higher value generally increases accuracy (as the chance of missing relevant vectors decreases) but at the cost of performance.
Balancing precision & performance for kNN parameters
The optimal values for k and num_candidates depend on a few factors and specific needs. If we prioritize extreme precision with a smaller set of highly relevant results, a lower k with a moderate num_candidates might be ideal. Conversely, if exploration and discovering unexpected books are your goals, a higher K with a larger num_candidates could be more suitable.
While there is no hard-and-fast rule to define the "lower" or "higher" number for the num_candidates, you need to decide this number based on your dataset, computing power and the expected precision.
Experimentation to optimize kNN parameters
By experimenting with different K and num_candidates combinations and monitoring search results and performance, you can fine-tune your searches to achieve the perfect balance between precision, exploration, and speed. Remember, there's no one-size-fits-all solution – the best approach depends on your unique goals and data characteristics.
Practical example: Using kNN for movie recommendations
Let's consider an example of movies to create a manual "simple" framework for understanding the effect of k and num_candidates attributes while searching for movies.
Manual framework
Let's understand how we can develop a home grown framework for tweaking the k and num_of_candidates attributes for a kNN search.
The mechanics of the framework is as follows:
- Create a movies index with a couple of
dense_vectorfields in the mapping to hold our vectorised data. - Create an embedding pipeline so each and every movie's title and synopsis fields will be embedded with a
multilingual-e5-smallmodel to store vectors. - Perform the indexing operation,which goes through the above embedding pipeline. The respective fields will be vectorised
- Create a search query using kNN feature
- Tweak the
kandnum_candidatesoptions as you'd want
Let's dig in.
Creating an inference pipeline
We will need to index data via Kibana - far from ideal - but it will do for this manual framework understanding. However, every movie that gets indexed must have the title and synopsis field vectorised to enable semantic search on our data. We can do this by elegantly creating a inference pipeline processor and attaching it to our batch indexing operation.
Let's create an inference pipeline:
The inference pipeline movie_embedding_pipeline, as shown above, creates vector fields text embedding for title and synopsis fields. It uses the inbuilt multilingual-e5-small model to create the text embeddings.
Creating index mappings
We will need to create a mapping with couple of properties as dense_vector fields. The following code snippet does the job:
Once the above command gets executed, we have a new movies index with the appropriate dense vector fields, including title_vector.predicted_value and synopsis_vector.predicted_value fields that hold respective vectors.
The index mapping parameter was set to false by default up to release 8.10. This has been changed in release 8.11, where the parameter is set to true by default, which makes it unnecessary to specify it.Next step is to ingest the data.
Indexing movies
We can use _bulk operation to index a set of movies - I'm reusing a dataset that I had created for my Elasticsearch in Action 2nd edition book - which is available here:
For completeness, a snippet of the ingestion using the _bulk operation is provided here:
Make sure you replace the script with the full dataset.
Note that the_bulkoperation is suffixed with the pipeline (?pipeline=movie_embedding_pipeline) so the every movie gets passed through this pipeline, thus producing the vectors.
As we primed our movies indexed with vector embeddings, it's time to start our experiments on fine tuning k and num_candidates attributes.
kNN search
As we have vector data in our movies index, we will be using approximate k-nearest neighbor (kNN) search. For example, to recommend movies similar that has father-son sentiment ("Father and son" as search query), we'll use a kNN search to find the nearest neighbors:
In the given example, the query leverages the top-level kNN search option parameter that directly focuses on finding documents closest to a given query vector. One key difference between this search with knn query at the top level as opposed to query at the top level is that in the former case, the query vector will be generated on-the-fly by a machine learning model.
The part in bold is not technically correct. On-the-fly vector generation is only achieved by using query_vector_builder instead of query_vector where you pass in the vector (computed outside of ES) but both the top-level knn search option and the knn search query provide this capability.
The script fetches the relevant results based on our search query (which is built using the query_vector_builder block). We are using a random k and num_candidates values set to 5 and 10 respectively.
kNN query attributes
The above query has a set of attributes that would make up the kNN query. The following information about these attributes will help you understand the query better:
The field attribute specifies the field in the index that contains the vector representations of our documents. In this case, title_vector.predicted_value is the field storing the document vectors.
The query_vector_builder attribute is where the example significantly diverges from simpler kNN queries. Instead of providing a static query vector, this configuration dynamically generates a query vector using a text embedding model. The model transforms a piece of text ("Father and son" in the example) into a vector that represents its semantic meaning.
The text_embedding indicates that a text embedding model will be used to generate the query vector.
The model_id is the identifier for the pre-trained machine learning model to use, It is the .multilingual-e5-small model in this example.
The model_text attribute is the text input that will be converted into a vector by the specified model. Here, it's the words "Father and son", which the model will interpret semantically to find similar movie titles.
The k is the number of nearest neighbors to retrieve - that is, it determines how many of the most similar documents to return based on the query vector.
The num_candidates attribute is the broader set of candidate documents per shard as potential matches to ensure the final results are as accurate as possible.
kNN results
Executing the kNN basic search script should get us top 5 results - for brevity, I'm providing just the list of the movies.
As you can expect, Godfather (both parts) are part of the father-and-son bonding while Pulp Fiction shouldn't have been part of the results (though the query is asking about "bonding" - Pulp Fiction is all about the bonding between few people).
Now that we have a basic framework setup, we can tweak the parameters appropriate and deduce the approximate settings. Before we tweak the settings, let's understand the optimal setting of k attribute.
Choosing optimal K value
Choosing the optimal value of k in k-Nearest Neighbors (kNN) algorithms is crucial for attaining the best possible performance on our dataset with minimal errors. However, there isn't a one-size-fits-all answer, as the best k value can depend on a few factors such as specifics of our data and what we are trying to predict.
To choose an optimal k value, one must create a custom framework with several strategies and considerations.
- k = 1: Try running the search query with k=1 as a first step. Make sure you change the input query for each run. The query should give you unreliable results as changing the input query will return incorrect results over time. This leads to a ML pattern called "overfitting" where the model becomes overly reliant on the specific data points in the immediate neighborhood. Model, thus, struggles to generalize to unseen examples.
- k = 5: Run the search query with k=5 and check the predictions. The stability of the search query should ideally improved and you should be getting adequate reliable predictions.
You can either incrementally increase the value of k - may be increase in the steps of 5 or x - until you find that sweet spot where you'd find the results for the input queries are pretty much spot on with less number of errors.
You can go to extreme values of k too, for example, pick a higher value of k=50, as discussed below:
- k = 50: Increase the
kvalue to 50 and check the search results. The errored results most likely outshine the actual/expected predictions. This is when you know that you are hitting the hard boundary of thekvalue. Largerkvalues leads to a ML feature called "underfitting" - a underfitting in KNN happens when the model is too simplistic and fails to capture the underlying patterns in the data.
Choosing the optimal
The num_candidates parameter plays a crucial role in finding the optimal balance between search accuracy and performance. Unlike k, which directly influences the number of search results returned, num_candidates determines the size of the initial candidate set from which the final k nearest neighbors are selected. As discussed earlier, the num_candidates parameter defines how many nearest neighbors will be selected on each shard.
Adjusting this parameter is essential for ensuring that the search process is both efficient and yields high-quality results.
num_candidates= Small Value (e.g., 10): Start with a low value ("low-value-exploration") fornum_candidatesas a preliminary step. The aim is to establish a baseline for performance at this stage. As the candidate bunch is just a handful of candidates, the search will be fast but might miss relevant results - which leads to poor accuracy. This scenario helps us to understand the minimum threshold where the search quality is noticeably compromised.num_candidates= Moderate Value (e.g., 25?): Increase thenum_candidatesto a moderate value ("moderate-value-exploration") and observe the changes in search quality and execution time. A moderate number of candidates is likely to improve the accuracy of the results by considering a wider pool of potential neighbors. As the number of candidates increased, there's going to be cost of resources, be mindful of that. So, keep monitoring the performance metrics closely. However, as the search accuracy increases, perhaps the increase in computational cost could be justifiable.num_candidates= Step Increase: Continue to incrementally increasenum_candidates(incremental-increase-exploration), possibly in steps of 20 or 50 (depending on the size of your dataset). Evaluate whether the additional candidates contribute to a meaningful improvement in search accuracy with each of the increments. There will be a a point of diminishing returns where increasingnum_candidatesfurther yields little to no improvement in result quality. At the same time you may have noticed, this will strain our resources and significantly impacts performance.num_candidates= High Value (say, 1000, 5000): Experiment with a high value fornum_candidatesto understand the upper bounds of the impact of choosing the higher settings. There's a possibility of your search accuracy stabilizing or degrading slightly due to the inclusion of less relevant candidates. This may lead to dilute the precision of the final k results. Do note that, as we've been talking about it, the high values ofnum_candidateswill always increase the computational load - thus longer query times and potential resource constraints.
Finding the optimal balance
We now know how to adjust the k and num_candidates attributes and how our experiments to different settings would change the outcome of search accuracy.
The goal is to find a sweet spot where the search results are consistently accurate with lower performance overhead from processing a large candidate set is manageable.
Of course, the optimal value will vary depending on the specifics of our data, the dimensionality of the vectors, and other performance requirements.
Wrap up
The optimal K value lies in finding the sweet spot by experiment and trials. You want to use enough neighbors (K being lower side) to capture the essential patterns but not so many (k being on the higher side) that the model becomes overly influenced by noise or irrelevant details. You also want to tweak the candidates so that the search results are accurate at a given k value.
Frequently Asked Questions
What do the k and num_candidates parameters represent in kNN search?
k refers to the number of global nearest neighbors to retrieve, and num_candidates to the number of candidate neighbors considered for each shard during the search.
How to choose the optimal value of the K and num_candidates parameters for KNN search?
If you prioritize extreme precision with a smaller set of highly relevant results, a lower k with a moderate num_candidates might be ideal. If exploration and discovery are your goals, a higher K with a larger num_candidates could be more suitable. By experimenting with different combinations and monitoring performance, you can achieve the perfect balance between precision, exploration, and speed.
Related Content
March 20, 2026
Fast vs. accurate: Measuring the recall of quantized vector search
Explaining how to measure recall for vector search in Elasticsearch with minimal setup.
March 2, 2026
Adaptive early termination for HNSW in Elasticsearch
Introducing a new adaptive early termination strategy for HNSW in Elasticsearch.
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.