Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
Starting with Elasticsearch 8.13, we provide an implementation of Learning To Rank (LTR) natively integrated into Elasticsearch. LTR uses a trained machine learning (ML) model to build a ranking function for your search engine. Typically, the model is used as a second stage re-ranker, to improve the relevance of search results returned by a simpler, first stage retrieval algorithm.
This blog post will explain how this new feature can help in improving your document ranking in text search and how to implement it in Elasticsearch.
Whether you are trying to optimize an eCommerce search, build the best context for a Retrieval Augmented Generation(RAG) application or craft a question answering based search on millions of academic papers, you have probably realized how challenging it can be to accurately optimize document ranking in a search engine. That's where Learning to Rank comes in.
Understanding relevance features and how to build a scoring function
Relevance features are the signals to determine how well a document matches a user's query or interest, all of which impact search relevance. These features can vary significantly depending on the context, but they generally fall into several categories. Let’s take a look at some common relevance features used across different domains:
- Text Relevance Scores (e.g., BM25, TF-IDF): Scores derived from text matching algorithms that measure the similarity of document content to the search query. These scores can be obtained from Elasticsearch.
- Document Properties (e.g., price of a product, publication date): Features that can be extracted directly from the stored document.
- Popularity Metrics (e.g., click-through rate, views): Indicators of how popular or frequently accessed a document is. Popularity metrics can be obtained with Search analytics tools, of which Elasticsearch provides out-of-the-box.
The scoring function combines these features to produce a final relevance score for each document. Documents with higher scores are ranked higher in search results.
When using the Elasticsearch Query DSL, you are implicitly writing a scoring function that weights relevance features and ultimately defines your search relevance
Scoring in the Elasticsearch Query DSL
Consider the following example query:
This query translates into the following scoring function:
While this approach works well, it has a few limitations:
- Weights are estimated: The weights assigned to each feature are often based on heuristics or intuition. These guesses may not accurately reflect the true importance of each feature in determining relevance.
- Uniform Weights Across Documents: Manually assigned weights apply uniformly to all documents, ignoring potential interactions between features and how their importance might vary across different queries or document types. For instance, the relevance of recency might be more significant for news articles but less so for academic papers.
As the number of features and documents increases, these limitations become more pronounced, making it increasingly challenging to determine accurate weights. Ultimately, the chosen weights become a compromise, potentially leading to suboptimal ranking in many scenarios.
A compelling alternative is to replace the scoring function that uses manual weights by a ML-based model that computes the score using relevance features.
Hello Learning To Rank (LTR)!
LambdaMART is a popular and effective LTR technique that uses gradient boosting decision trees (GBDT) to learn the optimal scoring function from a judgment list.
The judgment list is a dataset that contains pairs of queries and documents, along with their corresponding relevance labels or grades. Relevance labels are typically either binary, (e.g. relevant/irrelevant) or graded (e.g between 0 for completely irrelevant and 4 for highly relevant). Judgment lists can be created manually by humans or be generated from user engagement data, such as clicks or conversions.
The example below uses a graded relevance judgment.

LambdaMART treats the ranking problem as a regression task using a decision tree where the inner nodes of the tree are conditions over the relevance features, and the leaves are the predicted scores.

LambdaMART uses a gradient boosted tree approach, and in the training process it builds multiple decision trees where each tree corrects errors of its predecessors. This process aims to optimize a ranking metric like NDCG, based on examples from the judgment list. The final model is a weighted sum of individual trees.
XGBoost is a well known library that provides an implementation of LambdaMART, making it a popular choice to implement ranking based on gradient boosting decision trees.
Getting started with LTR in Elasticsearch
Starting with version 8.13, Learning To Rank is integrated directly into Elasticsearch and associated tooling as a technical preview feature.
Train and deploy an LTR model to Elasticsearch
Eland is our Python client and toolkit for DataFrames and machine learning in Elasticsearch. Eland is compatible with most of the standard Python data science tools like Pandas, scikit-learn and XGBoost.
We highly recommend using it to train and deploy your LTR XGBoost model, as it provides features to simplify this process:
- The first step of the training process is to define the relevant features of the LTR model. Using the Python code below, you can specify the relevant features using the Elasticsearch Query DSL.
- The second step of the process is to build your training dataset. At this step you will compute and add relevance features for each rows of your judgment list:

To help you with this task, Eland provides the FeatureLogger class:
- When the training dataset is built, the model is trained very easily (as also shown in the notebook):
- Deploy your model to Elasticsearch once the training process is complete:
To learn more about how our tooling can help you to train and deploy the model, check out this end-to-end notebook.
Use your LTR model as a rescorer in Elasticsearch
Once you deploy your model in Elasticsearch, you can enhance your search results through a rescorer. The rescorer allows you to refine a first-pass ranking of search results using the more sophisticated scoring provided by your LTR model:
In this example:
- First-pass query:
The multi_matchquery retrieves documents that match the querythe quick brown foxin the title and content fields. This query is designed to be fast and capture a large set of potentially relevant documents. - Rescore phase: The
learning_to_rankrescorer refines the top results from the first-pass query using the LTR model.model_id: Specifies the ID of the deployed LTR model (ltr-model-xgboostin our example).params: Provides any parameters required by the LTR model to extract features relevant to the query. Herequery_textallows you to specify the query issued by the user that some of our features extractors expect.window_size: Defines the number of top documents from the search results issued by the first-pass query to be rescored. In this example, the top 100 documents will be rescored.
By integrating LTR as a two stage retrieval process, you can can optimize both performance and accuracy of your retrieval process by combining:
- Speed of Traditional Search: The first-pass query retrieves a large number of documents with a broad match very quickly, ensuring fast response times.
- Precision of Machine Learning Models: The LTR model is applied only to the top results, refining their ranking to ensure optimal relevance. This targeted application of the model enhances precision without compromising overall performance.
Try LTR yourself!?
Whether you are struggling to configure search relevance for an eCommerce platform, aiming to improve the context relevance of your RAG application, or you are simply curious about enhancing your existing search engine's performance, you should consider LTR seriously.
To start your journey with implementing LTR, make sure to visit our notebook detailing how to train, deploy, and use an LTR model in Elasticsearch and to read our documentation. Let us know if you built anything based on this blog post or if you have questions on our Discuss forums and the community Slack channel.
Frequently Asked Questions
How does Learning To Rank (LTR work?
LTR uses a trained machine learning (ML) model to build a ranking function for your search engine. Typically, the model is used as a second-stage re-ranker, to improve the relevance of search results returned by a simpler, first-stage retrieval algorithm.
Related Content

March 5, 2026
Does MCP make search obsolete? Not even close
Explore why search engines and indexed search remain the foundation for scalable, accurate, enterprise-grade AI, even in the age of MCP, federated search, and large context windows.

February 20, 2026
Ensuring semantic precision with minimum score
Improve semantic precision by employing minimum score thresholds. The article includes concrete examples for semantic and hybrid search.

February 17, 2026
An open‑source Hebrew analyzer for Elasticsearch lemmatization
An open-source Elasticsearch 9.x analyzer plugin that improves Hebrew search by lemmatizing tokens in the analysis chain for better recall across Hebrew morphology.
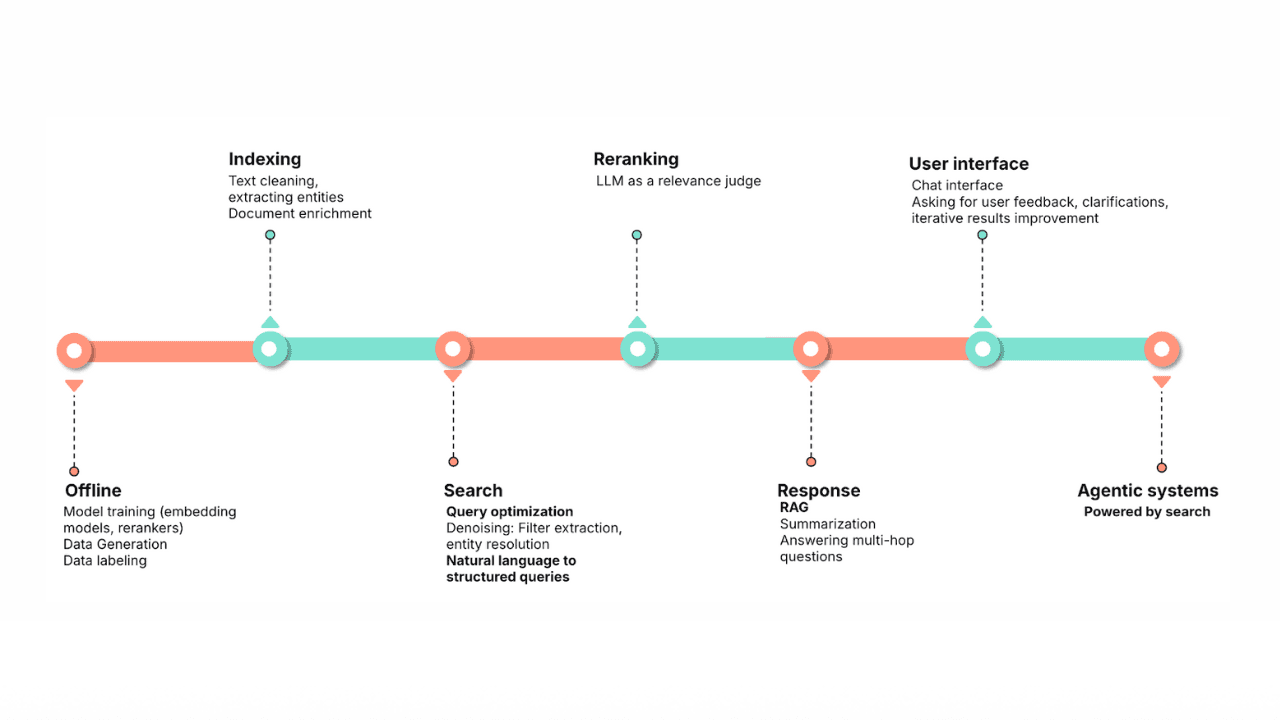
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.