From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
Navigating through geographical and rich text data presents significant challenges, especially for a recommendation service for attractions. Handling vast and diverse data such as reviews, ratings, images, locations, tags, and opening hours becomes complex when the data is unstructured and multilingual.
Elasticsearch's hybrid geo-semantic search capabilities offer a practical solution by combining spatial data handling with advanced vector text analysis within a single platform. Whether you're searching for landmarks or family-friendly attractions, Elasticsearch enables precise and efficient data retrieval.
In this blog, we will guide you through leveraging Elasticsearch to search across a dataset of 2 million TripAdvisor reviews. This dataset includes geographical coordinates, unstructured reviews in multiple languages, structured text, and numerical data. We will demonstrate how to integrate geographical and semantic search functions seamlessly for personalized recommendations.
By following our step-by-step approach, you'll learn how to:
- Enrich unstructured, multilingual review data with meaningful labels using machine learning models, including models for multi-language vectorization and review classification to tag POIs (e.g., "family-friendly," "value for money").
- Prepare and map your index for efficient full-text search, accommodating multilingual data.
- Set up custom ingest pipelines to process and transform your data, integrating external inference services if needed.
- Perform advanced location-aware recommendations based on both geographical and textual data.
All these processes—data ingestion, processing, inference, semantic search, geo search, and analysis—are handled within the Elasticsearch ecosystem.
Use cases for geo-semantic search
Location-based search
In this use case, we'll use review data and coordinates to improve our search results.
By focusing on geographic boundaries, we can provide precise results. For example, if you're looking for kid-friendly parks in Chelsea, which could be in Manhattan or London, we can leverage geo filtering that is applied during the Approximate KNN search to ensure you get results from the right Chelsea. This feature prevents confusion and helps avoid irrelevant results. Additionally, by normalizing and using distance as a ranking indicator, we can prioritize parks that are closer to the user. This means that, all other factors being equal, the nearer parks will appear first in the results, catering to the preference for nearby locations and enhancing the relevance of the search. It is also possible to incorporate a boosting mechanism based on more recent reviews to increase the relevance of recent results.
The retrieved review results are then aggregated to highlight the relevant points of interest based on the search results. As part of it, the retrieved median ratings for each point of interest are tailored to match specific user preferences. For instance, a park rated lower by someone without kids might be highly appreciated by those with children. By providing a median review aggregated based on relevant review data, we can generate a rating that is specifically tailored to the user, rather than relying on a generic overall rating from all users.
The aggregated results, showcases that the best place to go 5km around the chelsea area is High Line, with a median of 5 star rating by reviews that matches the KNN query:
Another example is art galleries around "City of London". Without specifying coordinates when searching for "Art galleries in City of London", you could get results from all over London, UK or even London, Canada.
Since the results are in multiple languages, we used a multilingual model to ensure relevant recommendations across different languages. The recommendations, including the National Gallery, the British Museum, and Tate Britain/Tate Modern, are highly relevant.
User review classification for personalized recommendations
The input for the query above can be provided in various ways, for example:
- By the user during a search
- User's direct input on signup ("What are the type of activities you are looking for?")
- Insight extracted from the user's reviews data.
In this case we will explore the third option; classifying the user's interests based on their past reviews. The approach enables the profiling of a user without needing to rely on training models or analyzing user similarities. This insight can then be fed into the query to automatically promote recommendations without having the user search for anything specific.
During ingestion, the multilingual model MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli will classify reviews in multiple languages. The predicted classes will be used to profile users.
In the following example, we're extracting the categories that are most interesting to the user "flyingtolive" based on their previous review, ordering by the probability of the category being correct.

In this user's case, the most relevant categories are "Accessible","Couple-Friendly","Great View" in that order. Knowing that these are the most important factors to the user, it is possible to improve personalized recommendations significantly.
Analysis
As Elastic is bundled with Kibana and can be leveraged for aggregations combined with semantic search, it is possible to analyze the data in multiple ways and generate reports via Kibana Lens. In the review data scenario, this information can be shared with businesses that are looking to understand trend analysis on the perception of their business.
For example, these are the classified reviews for "Central Park" over the years:
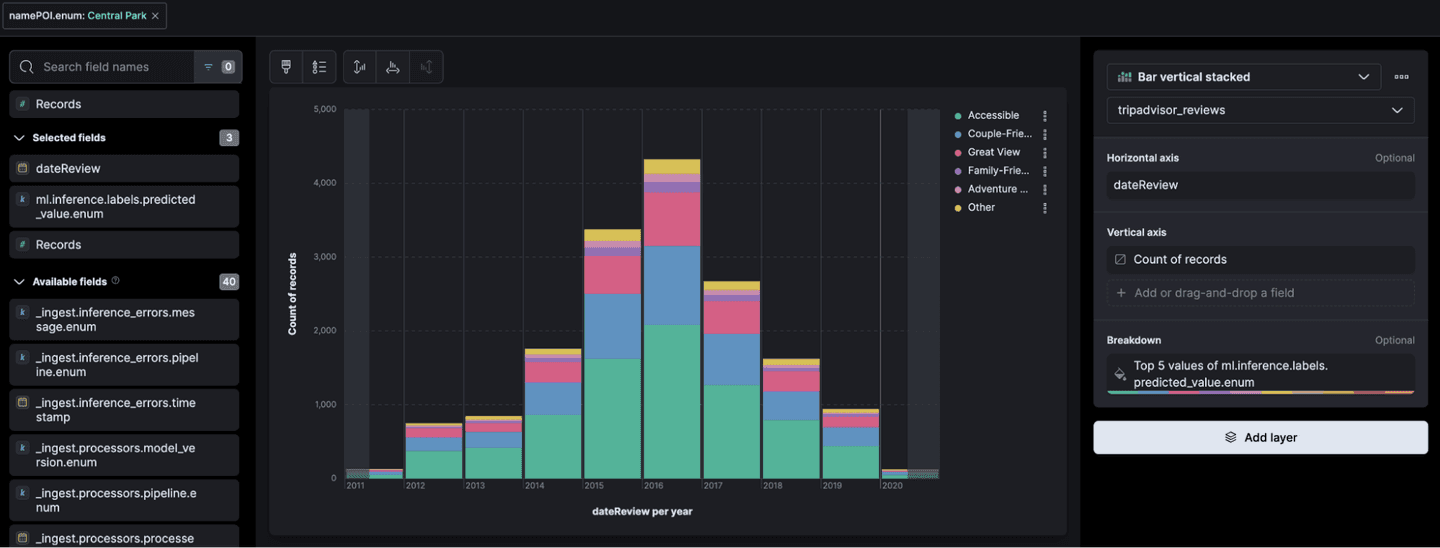
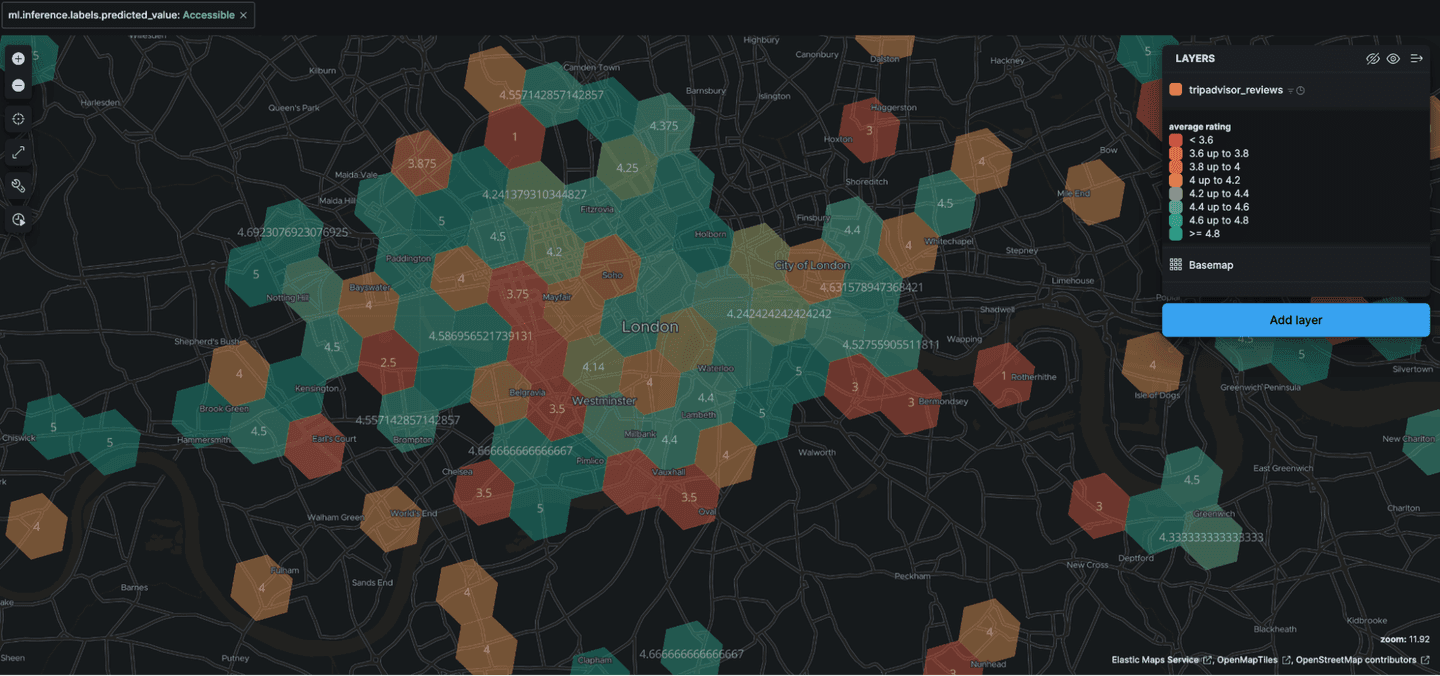
It also provides a map service that can visualize the review data, in this example looking at accessible points of interests in London:
Data preparation for geo-semantic search
Step 1: Importing a zero-shot classification model with eland
To improve the recommendation service for unstructured, multilingual review data, we could enrich reviews with labels such as Educational Value, Local Culture & History, and Value for Money, etc. These labels would help users quickly find highlighted information without searching through all the reviews.
Uploading a classification model to Elastic is possible using eland, a client library that allows the integration of machine learning models into Elasticsearch. For this use case, the multilingual model MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli will classify reviews in multiple languages. labels will be added to each review during the ingestion process. The labeled data can also be used as a form for business intelligence of customer reviews over time.
NOTE: It is recommended fine-tuning a smaller pre-trained model on your specific labels to enhance its relevance and performance for your task. This approach allows the model to adapt more closely to the nuances of your data.
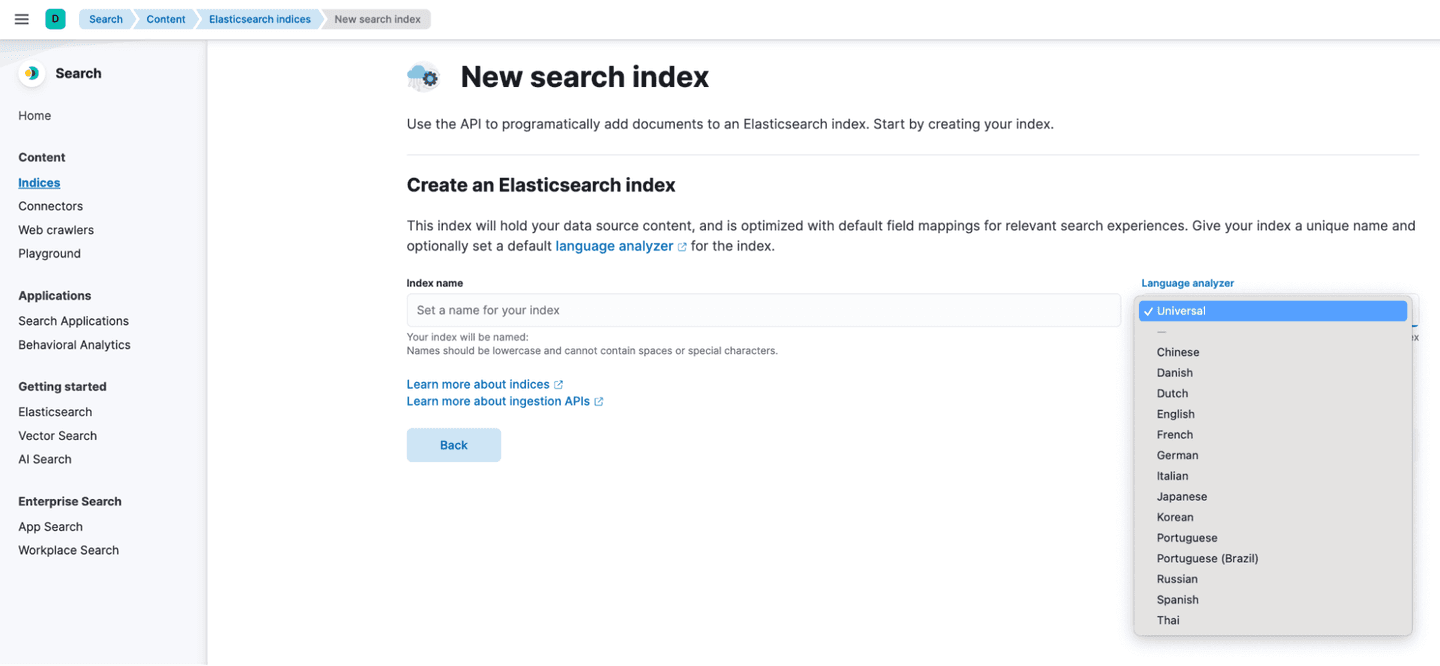
Step 2: Index preparation
In Kibana, create a search index under: Search > Indices.
This index gets key parts ready for full-text search, such as tokenization and analysers. With the reviews being multilingual, the Universal analyser is a great choice to handle different languages. However, if needed, you can choose a specific language analyser.
To appropriately map non-textual fields like the 'Coordinates' field as a geopoint, you'll need to update your index mapping. Here's an example using curl, and the mapping example attached in this blog's github repo:
Step 3: Set up ingest pipeline
The ingest pipeline can execute inference on the data, eliminate fields, parse fields, and even includes a script processor for flexible data manipulation.
For large texts, it is possible to leverage the ingest pipeline for chunking the content to smaller sections and utilize the nested object data type. An example could be found here.
To ingest the reviews data, we will generate a custom and inference pipeline that is automatically linked to the main pipeline, which shares the same name as the index.
The pipelines that will be set up will:
- Run multilingual inference on the fields 'text', 'tagsPOI' and 'namePOI'
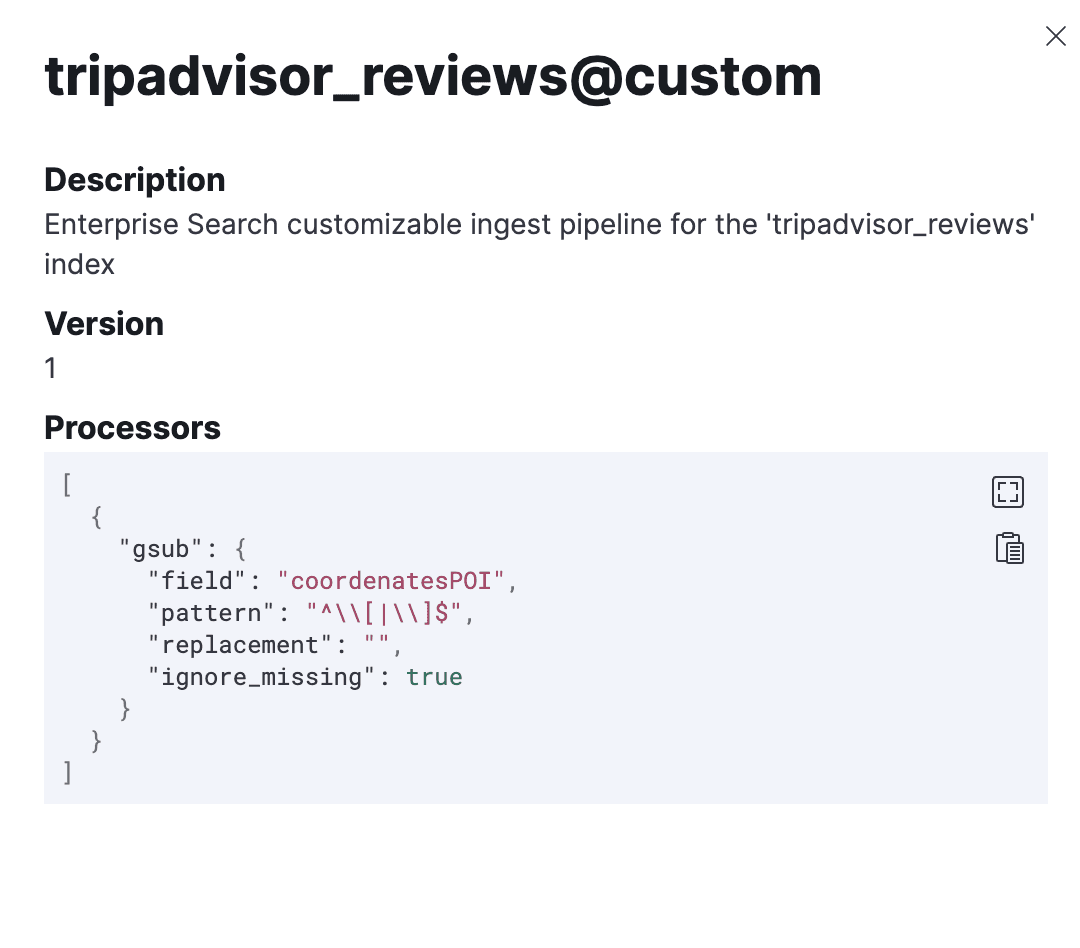
- gsub the "coordinatesPOI" field
- Run multilingual classification of reviews
Tip: By utilizing an inference pipeline, it is also possible to integrate external inference services like Hugging Face or OpenAI directly into your data ingestion process, ensuring efficient and streamlined data processing. This approach eliminates the need for additional tools and is particularly useful for development and testing purposes, as it allows you to test different models within a single platform without the need to re-ingest data or rely on external services.
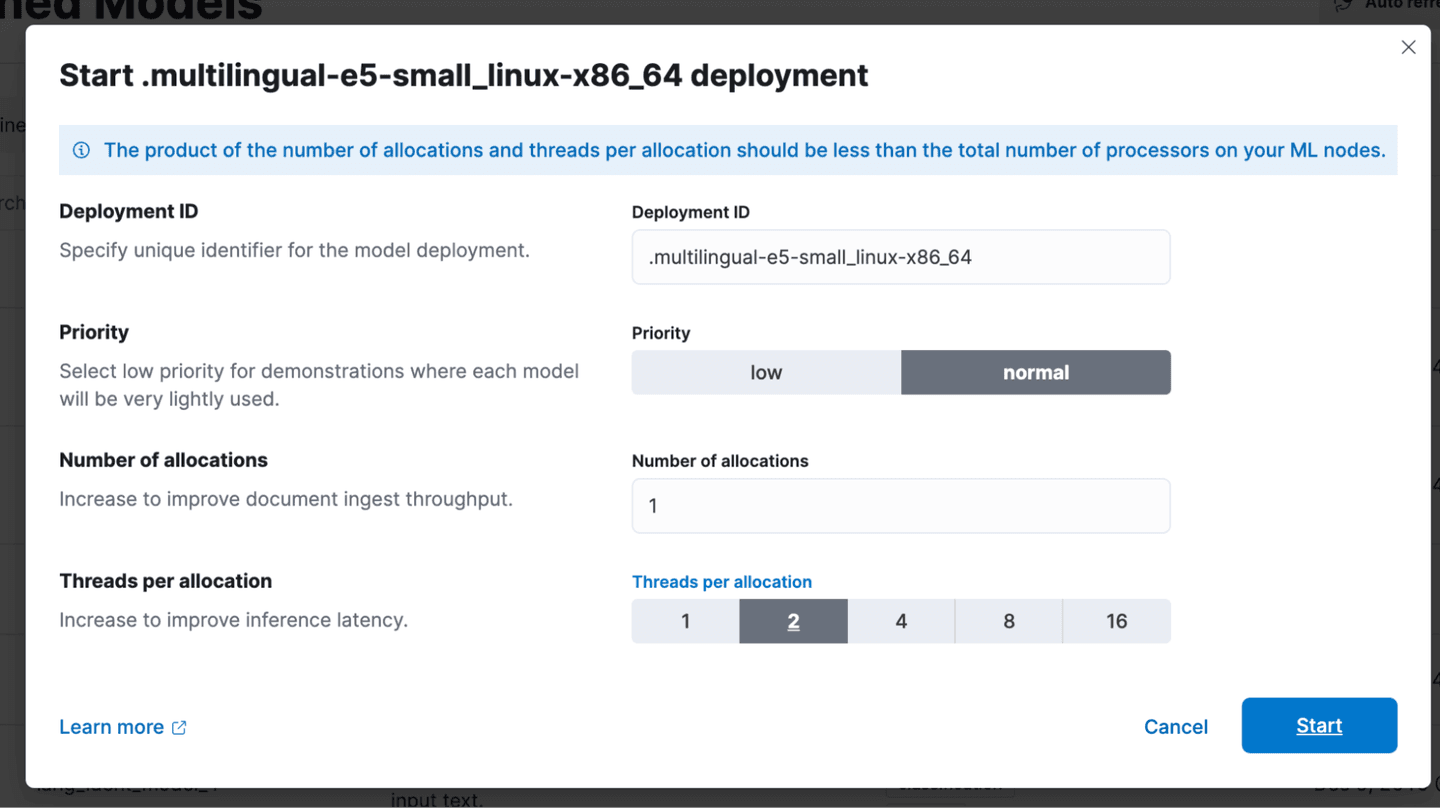
- To integrate the e5 model with the ingest pipeline, navigate to 'Pipelines' in the newly created index, deploy and start the Machine Learning (ML) inference pipeline. The text fields for inference in this case are 'text', 'tagsPOI' and 'namePOI'.
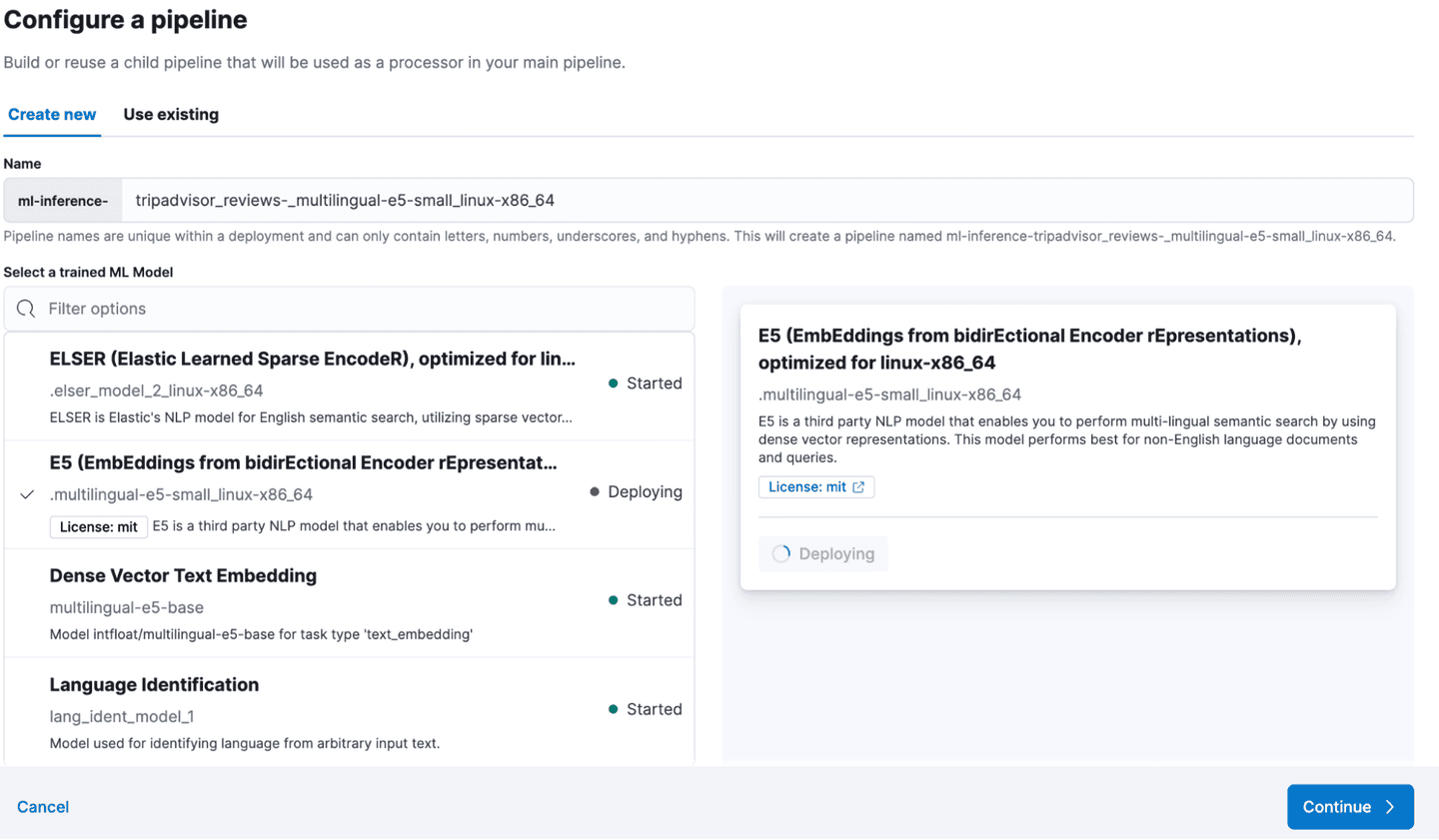
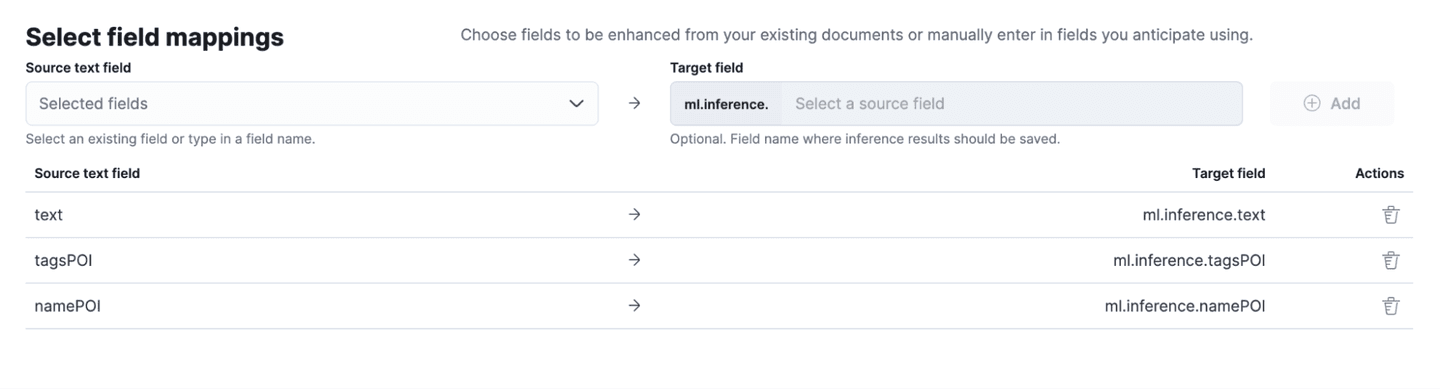
- In this dataset, we need to tweak the "CoordinatesPOI" field so it fits the geopoint mapping formats. To make this happen, we use a custom ingest pipeline with a gsub processor. It changes the coordinates field from a string array format like "[1,2]" to a string format like "1,2".
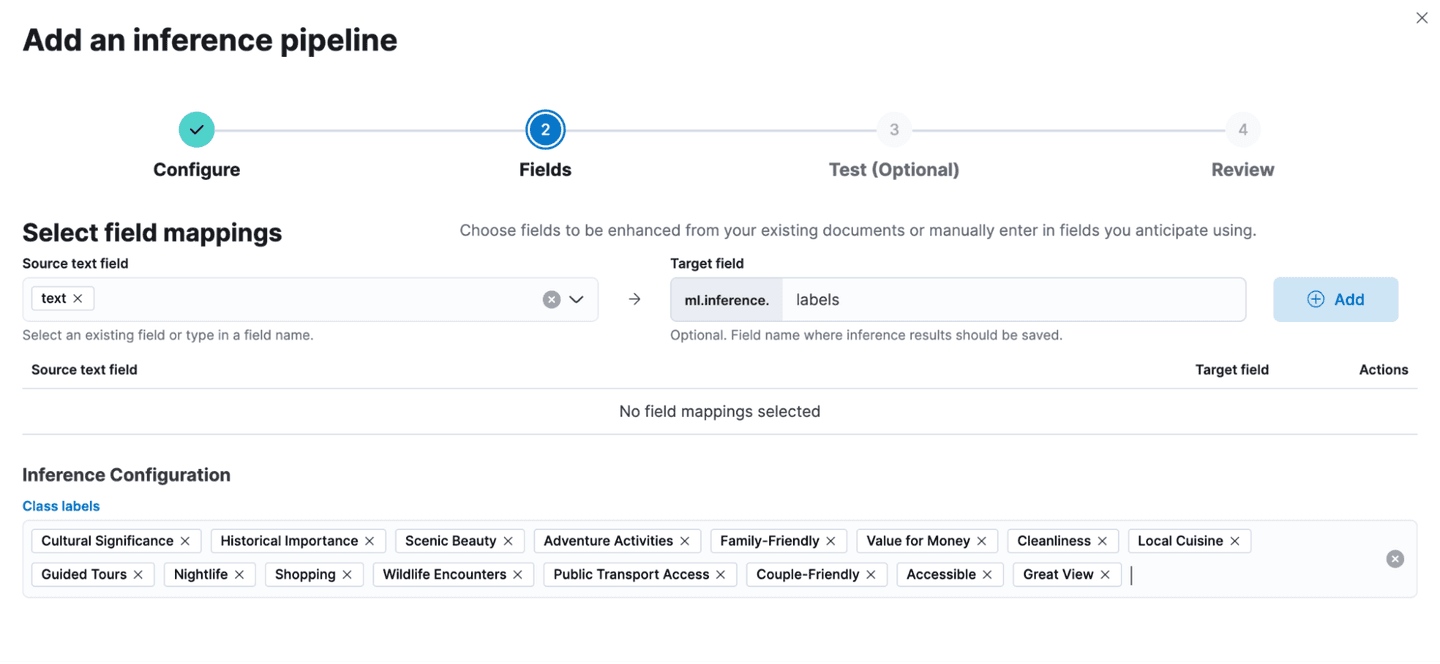
- A secondary inference processor is utilized to label the review text data. To prevent conflicts with the vector field, configure the target field appropriately. The list of labels is referenced below.
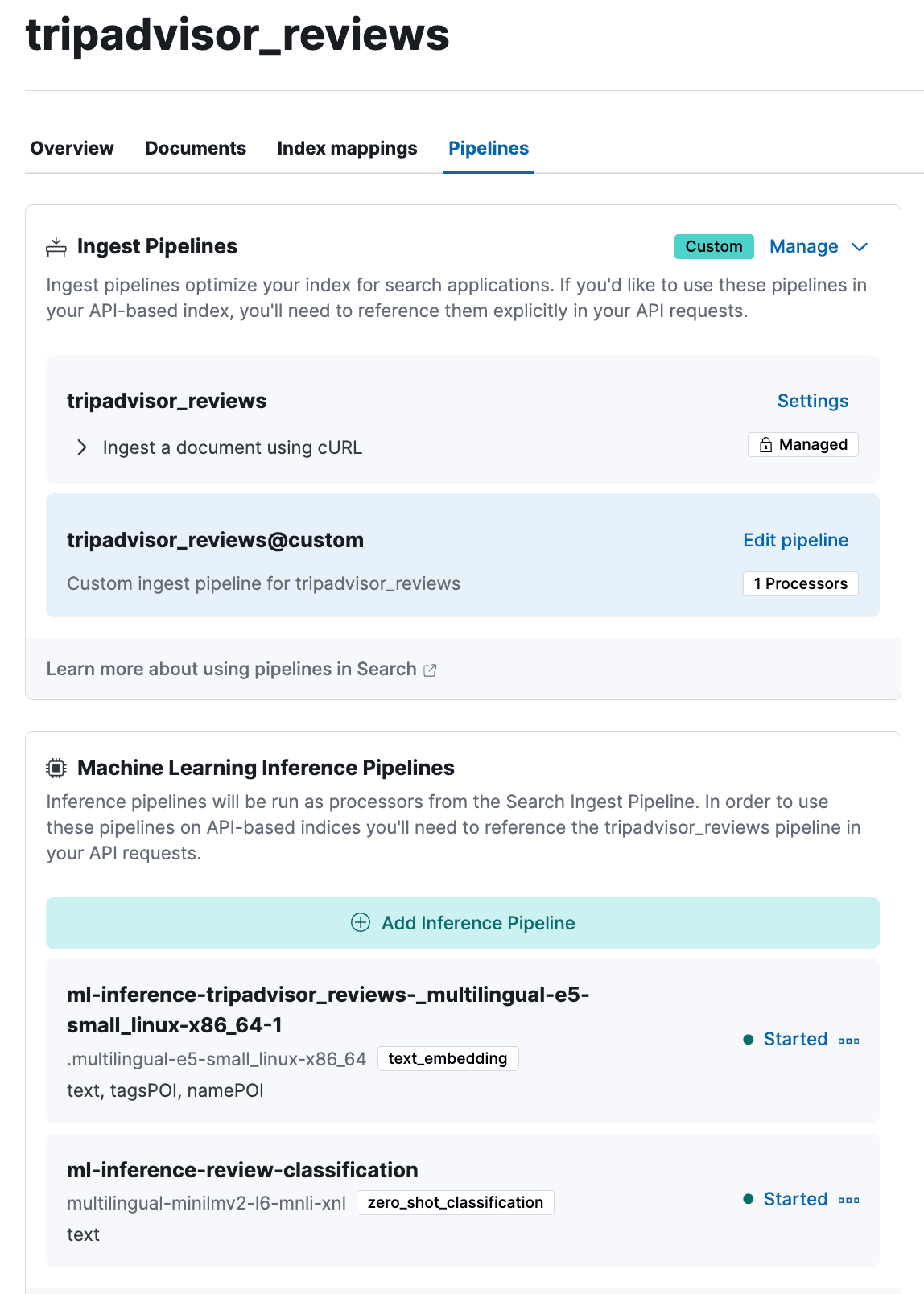
Step 4: Data ingest
Elasticsearch requires data to be in JSON, CSV, or XML formats for interpretation, but the TripAdvisor reviews dataset is initially in pickle format. Thus, some manipulation is required.
This blog's ingest Python script performs several tasks to accomplish this:
- It converts files from pickle to CSV format.
- It adds a "_run_ml_inference": true field to initiate the inference process.
- It efficiently loads the CSV data into Elasticsearch using the bulk API.
- It leverages the ingest pipeline with the same index name for data processing.
To run the Elasticsearch ingest script, an .env file is required that includes the variables of the Elasticsearch hosts, username, password:
Run the script:
Once the script has completed its execution, the structure of the base directory will be as follows:
Conclusion
Leveraging Elasticsearch's hybrid geo-semantic search capabilities offers a robust solution for managing unstructured and multilingual data in a broad range of use cases. By integrating machine learning models, setting up custom ingest pipelines, and utilizing advanced location-aware queries, you can achieve precise, efficient, and personalized data retrieval. This approach enhances search relevance and provides valuable insights for businesses and users alike.
Related Content
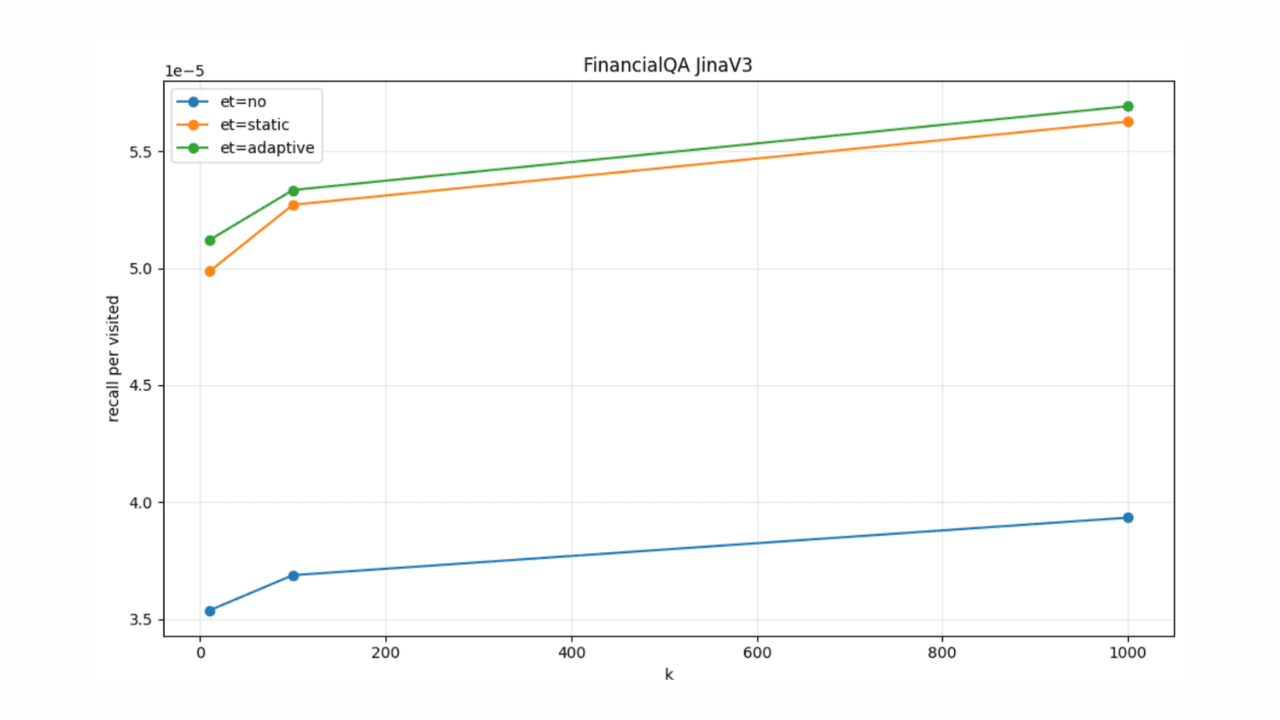
March 2, 2026
Adaptive early termination for HNSW in Elasticsearch
Introducing a new adaptive early termination strategy for HNSW in Elasticsearch.
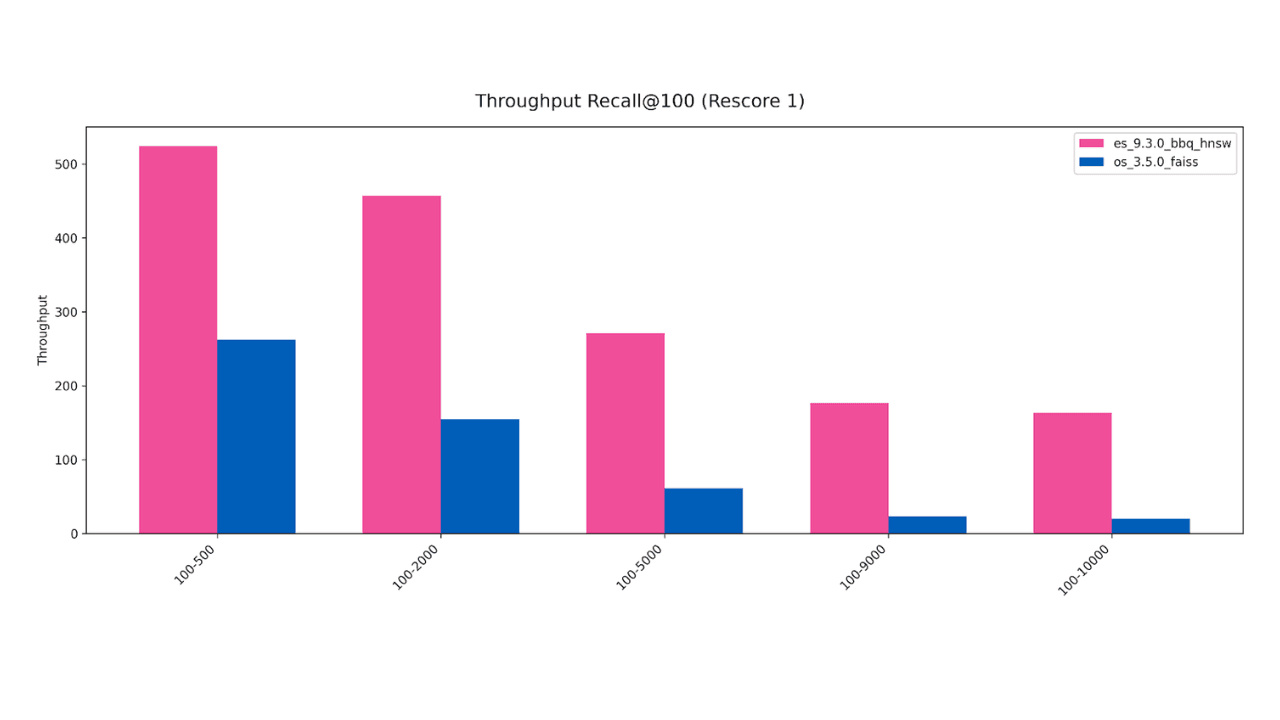
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
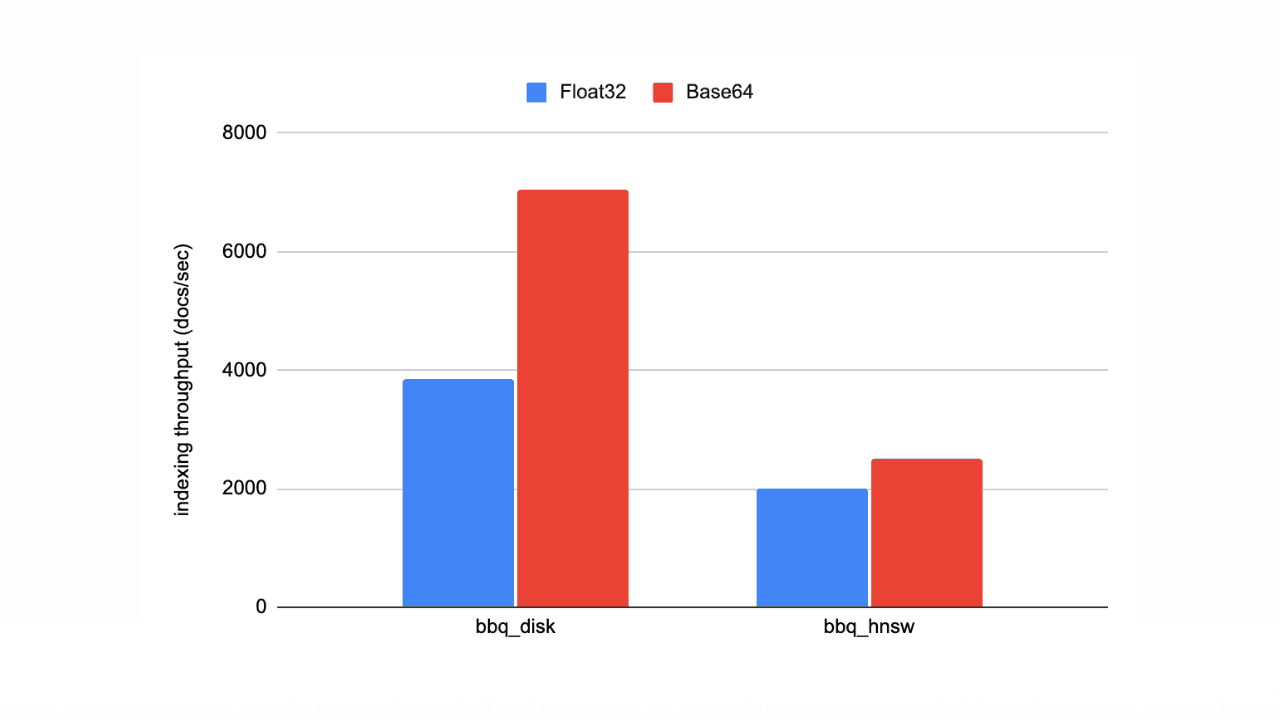
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.