Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Elastic 8.15 is out, and Semantic Search is easier than ever to pull off.
We're going to cover how to accomplish all of these tasks in 15 minutes:
- Store your documents in some data storage service like an AWS S3 Bucket
- Set up an Elastic S3 Connector
- Upload an embedding model using the eland library, set-up an inference API in Elastic
- Connect that to an index that uses the semantic_text datatype
- Add your inference API to that index
- Configure and sync content with the S3 Connector
- Use the Elastic Playground immediately
You will need:
- An Elastic Cloud Deployment updated to Elastic 8.15
- An S3 bucket
- An LLM API service (Anthropic, Azure, OpenAI, Gemini)
And that's it! Let's get this done.
Collecting data
To follow along with this specific demo, I've uploaded a zip file containing the data used here. It's the first 60 or so pages of the Silmarillion, each as a separate pdf file. I'm going through a Lord of the Rings kick at the moment. Feel free to download it and upload it to your S3 bucket!
Splitting the document into individual pages is sometimes necessary for large documents, as the native Elastic S3 Connector will not ingest content from files over 10MB in size.
I use this Python script for splitting a PDF into individual pages:
Setting up the S3 connector
The connector can ingest a huge variety of data types. Here, we're sticking to an S3 bucket loaded with pdf pages.
My S3 Bucket
I'll just hop on my Elastic Cloud deployment, go to Search->Content->Connectors, and make a new connector called aws-connector, with all the default settings. Then I'll open up the configuration and add the name of my bucket, and the secret key and access key tagged to my AWS user.
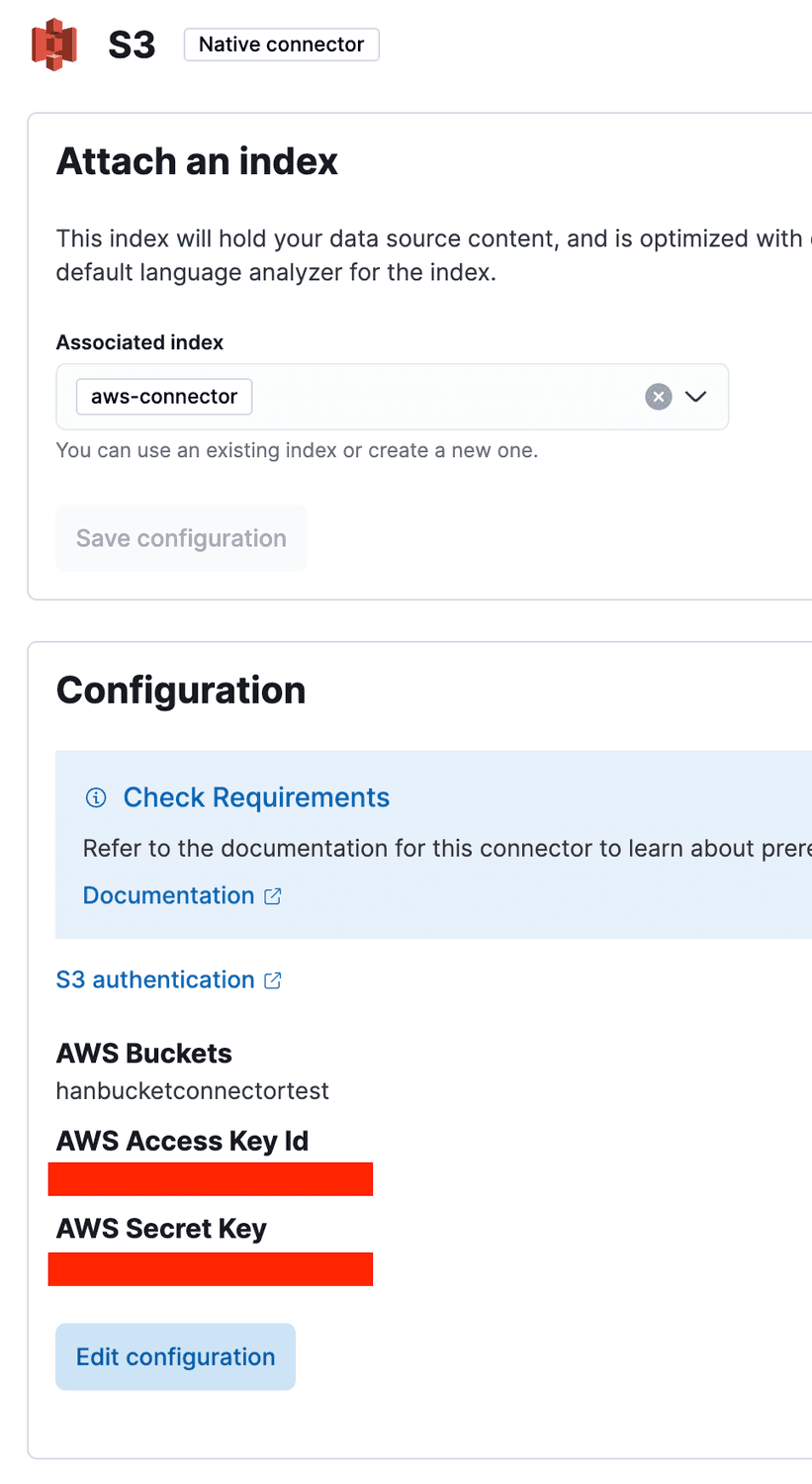
Elastic Cloud S3 Connector Configuration
Run a quick sync to verify that everything is working okay. Synchronization will ingest every uningested file in your data source, extract its content, and store it as a unique document within your index. Each document will contain its original filename. Data source documents with the same filenames as existing indexed documents won't be reingested, so have no fear! Synchronization can also be regularly scheduled. The method is described in the documentation. If everything is working fine, assuming my AWS credentials and permissions are all in order, the data's going to go into an index called aws-connector.
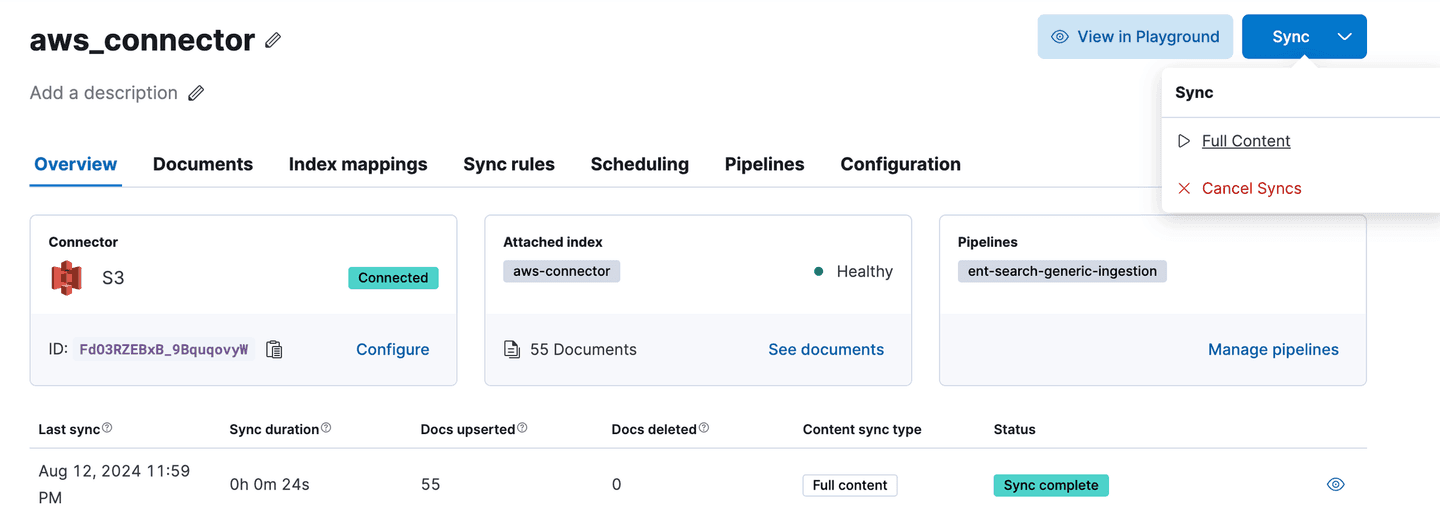
First successful sync of our S3 connector
Looks like it's all good. Let's grab our embedding model!
Uploading an embedding model
Eland is a Python Elasticsearch client which makes it easy to convert numpy, pandas, and scikit-learn functions to Elasticsearch powered equivalents. For our purposes, it will be our method of uploading models from HuggingFace, for deployment in our Elasticsearch cluster. You can install eland like so:
Now get to a bash editor and make this little .sh script, filling out each parameter appropriately:
MODEL_ID refers to a model taken from huggingface. I'm choosing all-MiniLM-L6-v2 mainly because it is very good, but also very small, and easily runnable on a CPU. Run the bash script, and once done, your model should appear in your Elastic deployment under Machine Learning -> Model Management -> Trained Models.

Deploy the model you just uploaded with eland
Just click the circled play button to deploy the model, and you're done.
Setting up your semantic_text index
Time to set up semantic search. Navigate to Management -> Dev Tools, and delete your index because it does not have the semantic_text datatype enabled.
Check the model_id of your uploaded model with:
Now create an inference endpoint called minilm-l6, and pass it the correct model_id. Let's not worry about num_allocations and num_threads, because this isn't production and minilm-l6 is not a big-boy.
Now recreate the aws-connector index. Set the "body" property as type "semantic_text", and add the id of your new inference endpoint.
Get back to your connector and run another full-content sync (For real this time!). The incoming documents are going to be automatically chunked into blocks of 250 words, with an overlap of 100 words. You don't have to do anything explicitly. Now that's convenient!
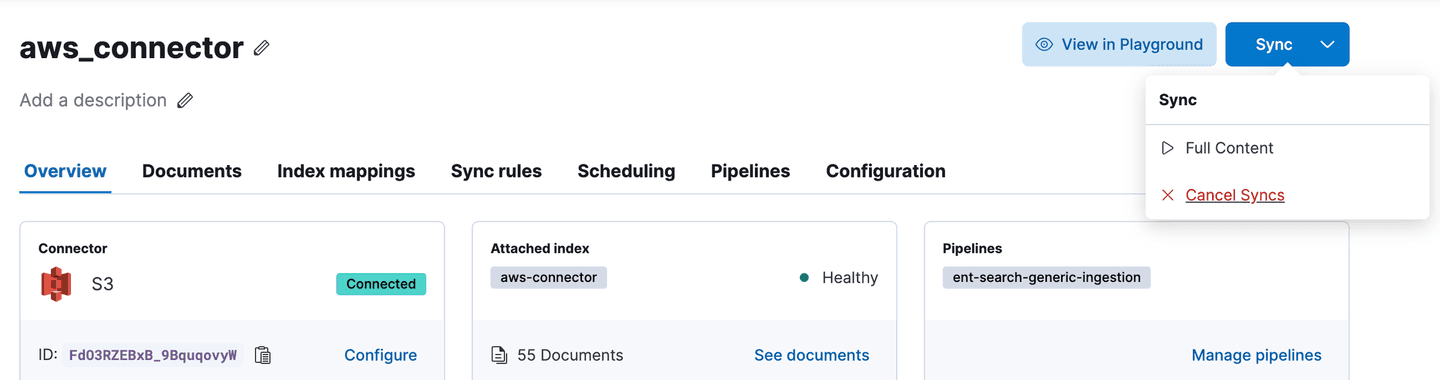
Sync your S3 connector for real this time!
And it's done. Check out your aws-connector index, there'll be 140 documents in there, each of which is now an embedded chunk:
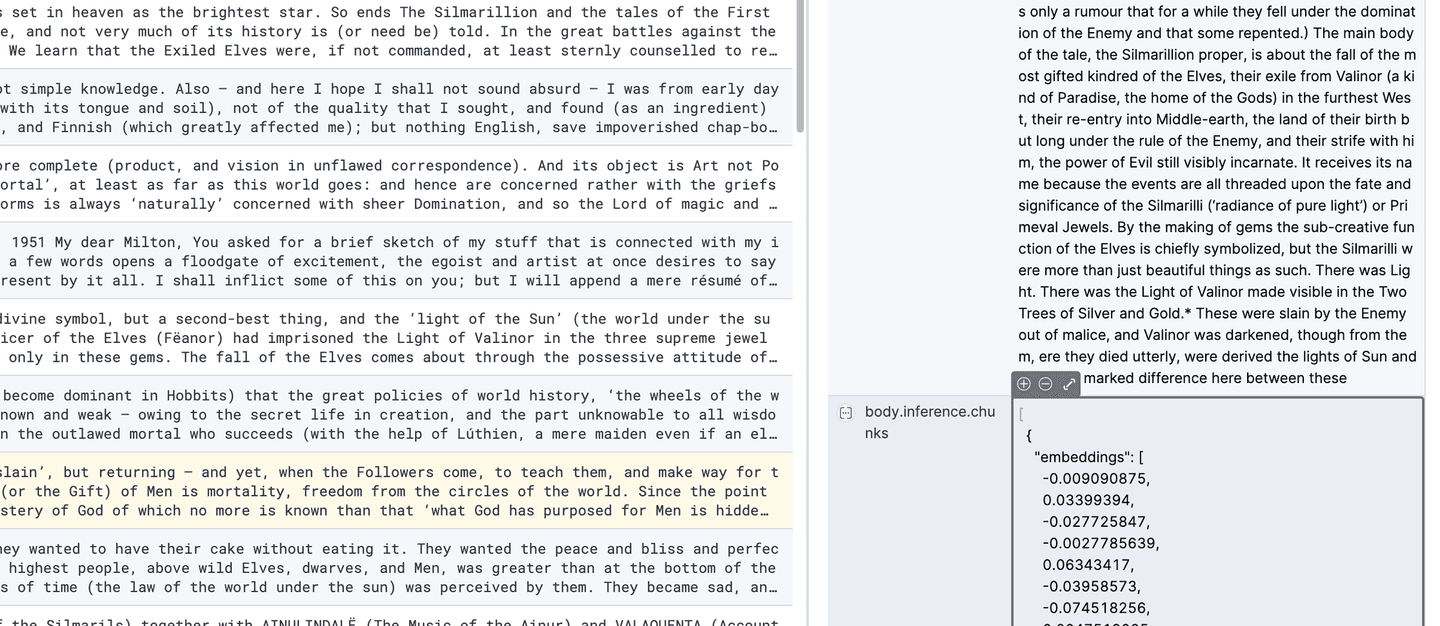
Index full of chunked documents
Do RAG with the Elastic Playground
Scurry over to Search -> Build -> Playground and add an LLM connector of your choice. I'm using Azure OpenAI:

Set your endpoint and API key
Now let's set up a chat experience. Click Add Data Sources and select aws-connector:
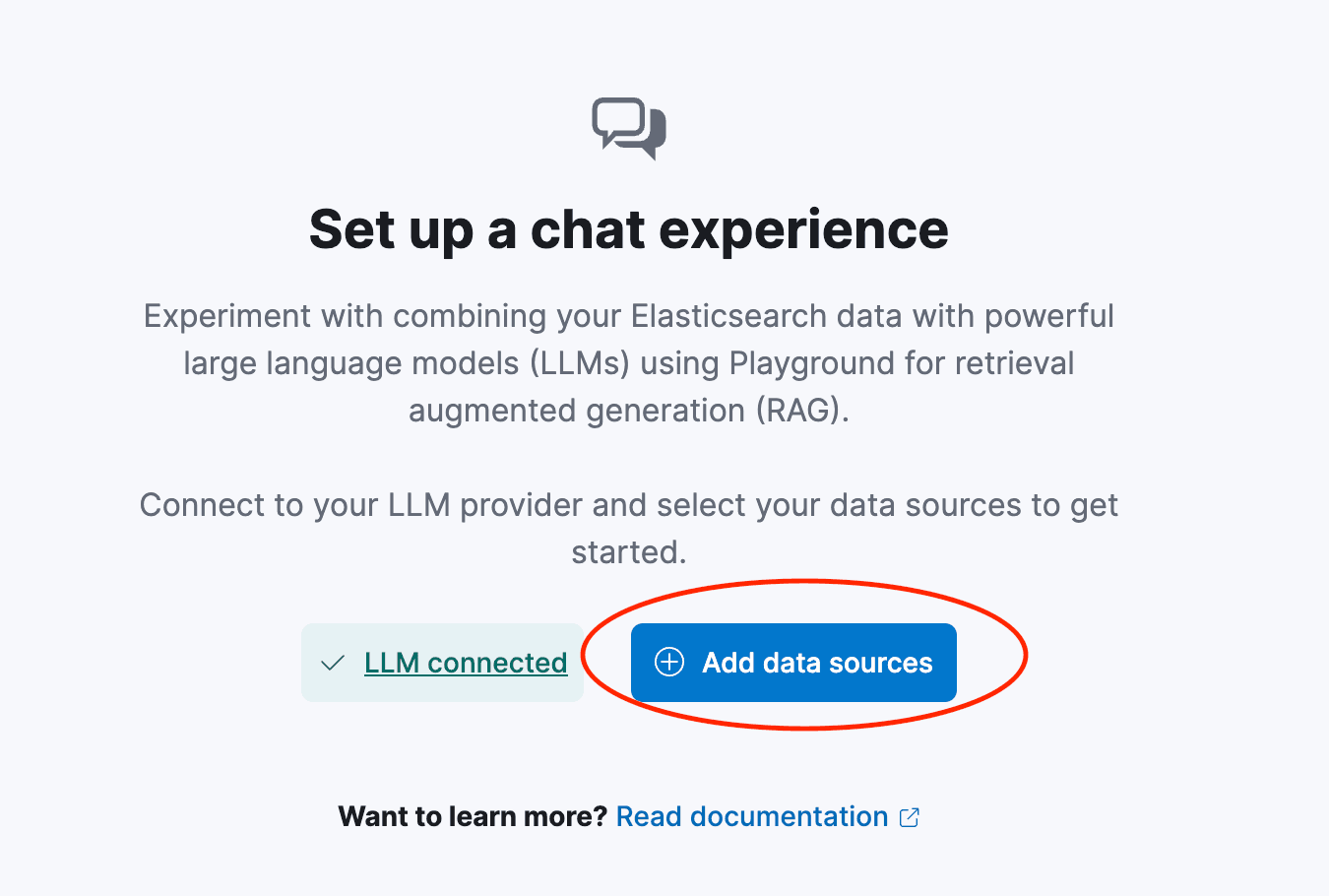
Set up your chat experience
Check out the query tab of your new chat experience. Assuming everything was properly set up, it will automatically be set to this hybrid search query, with the model_id minilm-l6.
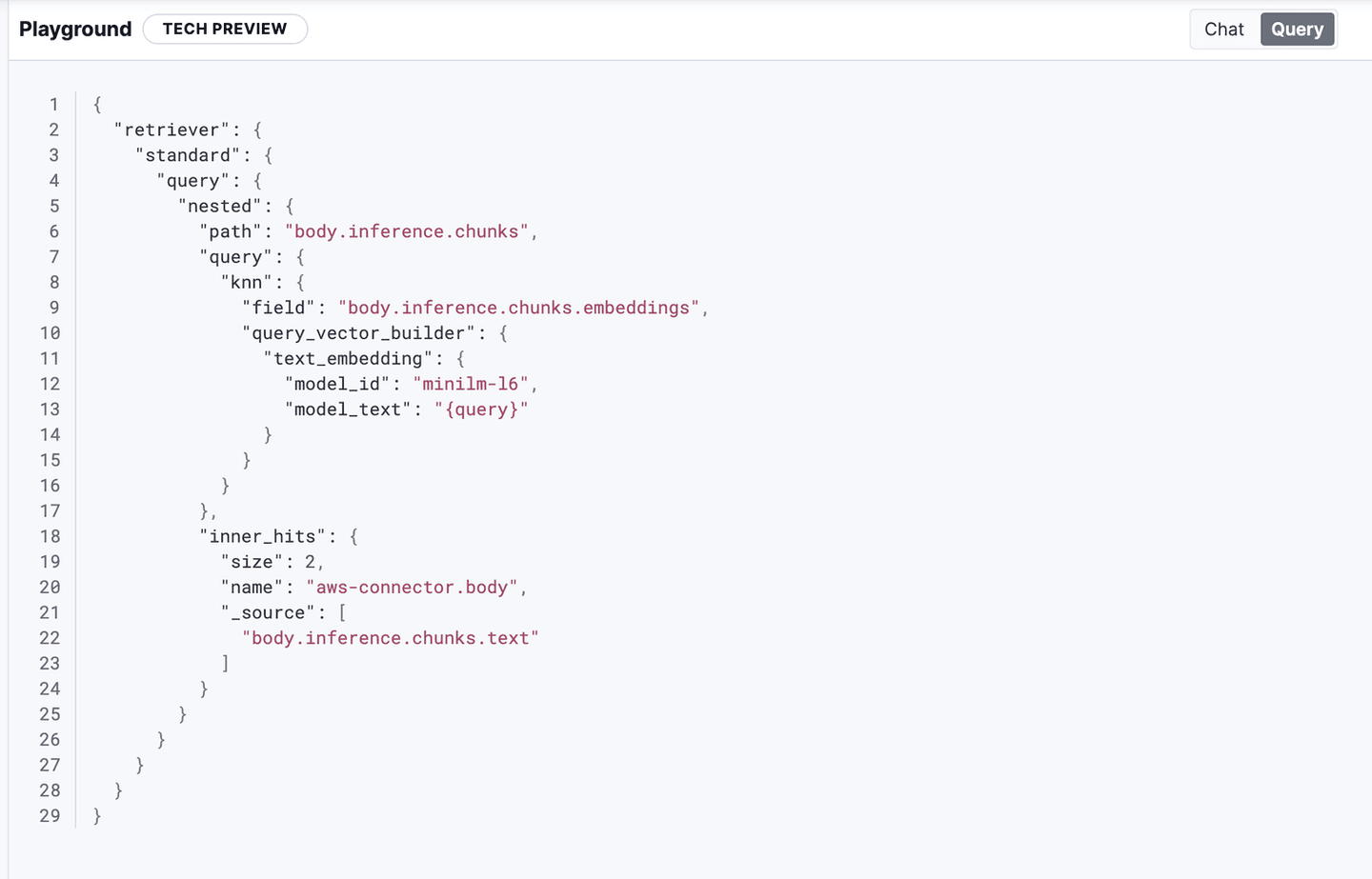
Default hybrid search query
Let's ask a question! We'll take three documents for the context, and add my special RAG prompt:
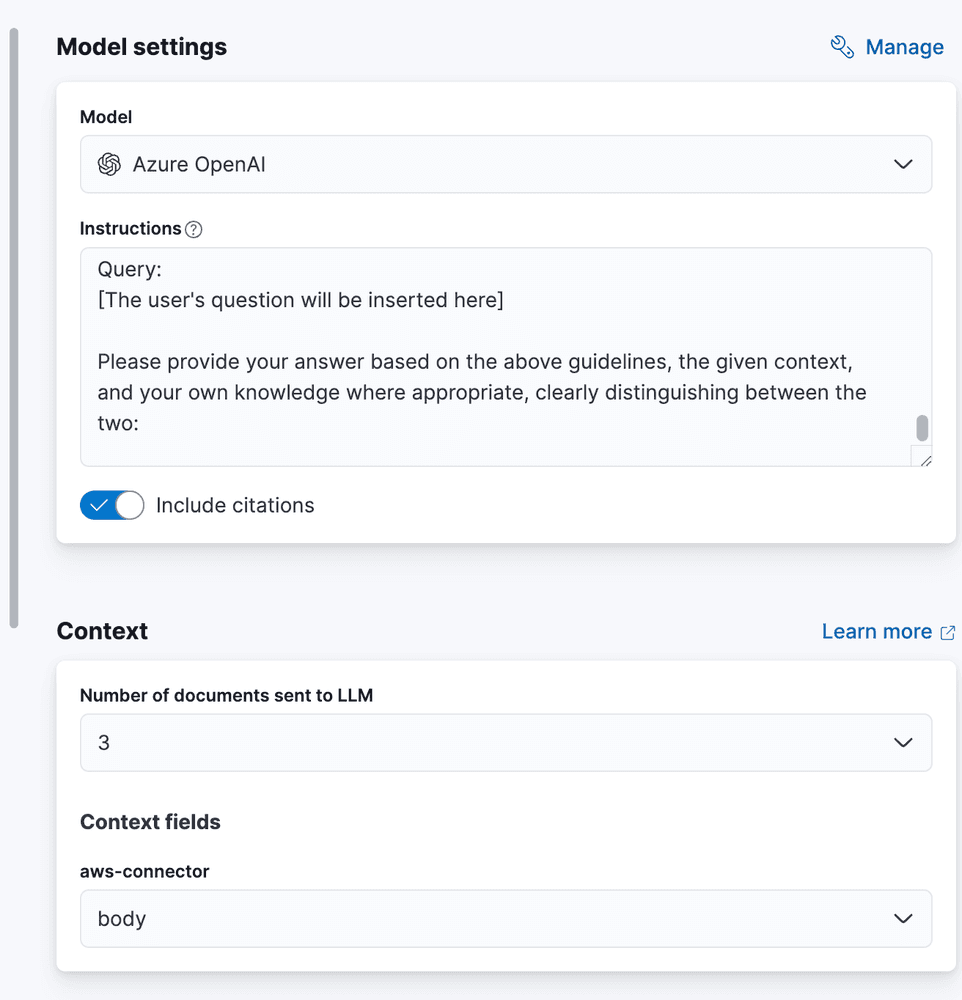
Add a prompt and select the number of search results for context
Query: Describe the fall from Grace of Melkor
We'll use a relatively open-ended RAG query. To be answered satisfactorily, it will need to draw information from multiple parts of the text. This will be a good indicator of whether RAG is working as expected.
Well I'm convinced. It even has citations! One more for good luck:
Query: Who were the greatest students of Aule the Smith?
This particular query is nothing too difficult, I'm simply looking for a reference to a very specific quote from the text. Let's see how it does!
Well, that's correct. Looks like RAG is working just fine.
Conclusion
That was incredibly convenient and painless — hot damn! We're truly living in the future. I can definitely work with this. I hope you're as excited to try it as I am to show it off.
Related Content

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.

January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.

January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.