Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
You can build semantic search and semantic reranking with Google Vertex AI and Elasticsearch open inference API!
Following our close collaboration with the Google Vertex AI team, we're excited to announce that the Elasticsearch vector database now natively integrates with Google Vertex AI, enabling developers to store embeddings generated by any text embedding model available in Google Vertex AI Text Embeddings API. Elasticsearch also integrates natively with Google Vertex AI’s reranking capabilities via the Elastic open inference API. Developers can use both capabilities in combination, or on their own, for building powerful semantic search and RAG applications.
Google Vertex AI is a managed development platform for AI applications. You can access a variety of models including text embedding and reranking models. In this blog post, we’ll use `text-embedding-004` to generate embeddings for English text. To improve the quality of our search results we’ll use the `semantic-ranker-512@latest` model.
In this blog, we will:
- Generate embeddings using
text-embedding-004 - Use Elastic’s new
semantic_textfield to chunk and store embeddings in Elasticsearch - Build a semantic reranking example with
semantic-ranker-512@latest - Use Elastic’s retrievers to build two stage retrieval with BM25 and semantic reranking
Getting Started with generating Embeddings
To get started, you’ll need a Google Account with access to the Google Vertex AI platform. Then you need to select an existing or create a new Google Cloud project in the Google Cloud console. Save your project id somewhere as we need it later.
Afterwards you need to enable the Vertex AI API:

Then you need to create a service account under IAM & Admin > Service Accounts:
You need to make sure that your service account has the correct role and permissions to be able to generate embeddings with Google Vertex AI. Assign the Vertex AI User (roles aiplatform.user) containing the permission aiplatform.endpoints.predict.
When creating a key for your service account make sure to select json. Download the service account JSON and save it for later.
Now, open Kibana’s Dev Console. You can also perform the following steps using an HTTP GUI client like postman or any other tool like curl.
You’ll create an inference endpoint using the Create inference API by providing your service account JSON, the location, the model you want to use and your project id:
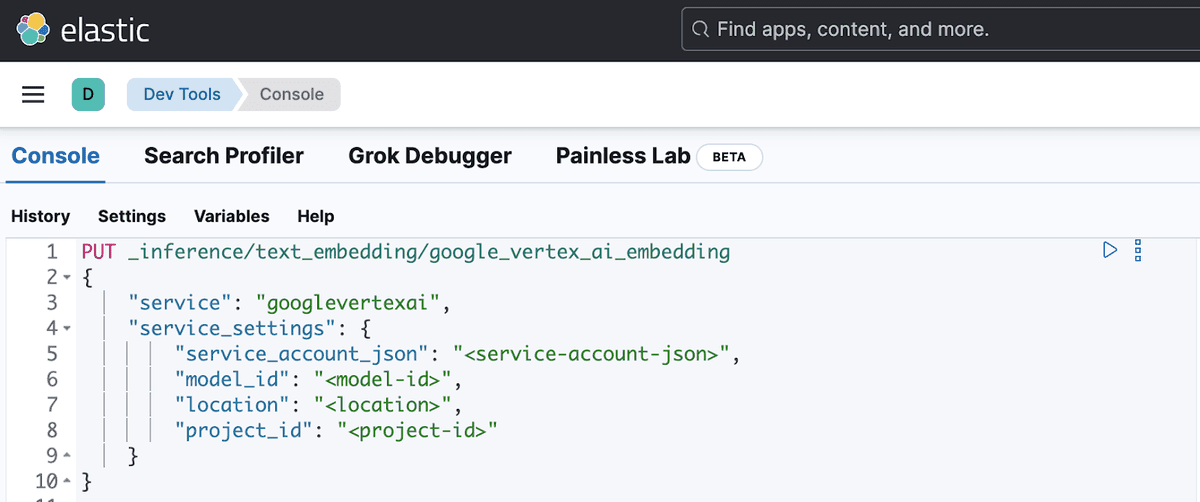
You will receive a response from Elasticsearch with the created endpoint:
Under the hood Elasticsearch will connect to Google Vertex AI with your credentials to get the number of dimensions used for generating your embeddings. It’ll also set the similarity measure used during retrieval to a reasonable default (in this case dot_product).
You can test your endpoint by calling the perform inference API:
The API will return a response with the generated embeddings for your input:
Using semantic_text with Google Vertex AI Embeddings
Now that we’ve an inference endpoint setup with Google Vertex AI Embeddings we can use the new semantic_text field type inside Elasticsearch for performing semantic search out of the box without the need of setting up additional application code explicitly calling the inference API to generate embeddings during ingestion and during query time.
Note that the combination of inference API and semantic_text performs automatic chunking (breaking larger text into smaller chunks) if the text to generate embeddings for is too large! We are very excited to see how developers use this feature.
To continue our example, we’ll create an index, which references our inference endpoint google_vertex_ai_embedding for generating embeddings when indexing a document and during search at query time:
We can now index documents and the semantic_text field type will take care of generating dense embeddings using our inference endpoint, which calls the Google Vertex AI API under the hood. For demonstration purposes we’ll just index one document:
You can now issue a semantic search request using the following request:
You should get back the document we’ve indexed previously:
Getting started with Semantic Reranking
We’ve already created an account and a project, which we’ll reuse to set up reranking.
Why use rerankers? Rerankers improve the relevance of results from earlier-stage retrieval mechanisms. Semantic rerankers use machine learning models to reorder search results based on their semantic similarity to a query.
Back to our implementation, you need to enable the Discovery Engine API to be able to rerank documents:
You can reuse the service account we’ve created before or create a new one. Assign the role Discovery Engine Viewer (roles/discoveryengine.viewer) containing the permission discoveryengine.rankingConfigs.rank to the service account you’ll use.
For the following steps you can use the Kibana Dev Console again or any http client of your liking.
First, we’ll create an inference endpoint to be able to rerank documents:
Again you’ll receive a response indicating that the inference endpoint was created successfully:
Let’s send a set of documents to our newly created endpoint to make sure that reranking works. We’ll use the example of Google Vertex AI’s reranking docs:
You’ll receive a response, which should rank the scientific explanation higher:
Using retrievers with Google Vertex AI Semantic Reranking
In 8.14 we introduced another exciting feature called retrievers, which provides an intuitive API to define multi-stage retrieval pipelines within a single _search API call. This removes the burden on your application to issue multiple search requests to Elasticsearch and to combine the results accordingly afterwards. In our example we define a simple multi-stage retrieval pipeline, which uses the common BM25 algorithm to retrieve a set of relevant documents to the term “sky”. Afterwards this set of documents will be passed to our inference endpoint google_vertex_ai_rerank to refine the order of our result set even further to give us the scientific explanation of why the sky is blue.
We're creating a small collection of documents using the Bulk API that include poems about mountains, the sky, the ocean, along with one scientific explanation of why the sky is blue:
Conclusion
Harness the power of semantic_text and retrievers together with Google Vertex AI’s dense embedding and reranking capabilities using just a few simple API calls abstracting away the complicated parts of semantic search and reranking. All of these features are already available in our serverless offering, so try it out now!
Visit the Google Vertex AI page on Search Labs, or try other sample notebooks on Search Labs GitHub.
Related Content
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.