使用 Elasticsearch Freeze index API 创建冻结索引
背景介绍
当我们希望充分利用硬件时,经常会采用热温架构。当我们有基于时间的数据时,如日志、指标和 APM 数据时,它特别有用。这类设置大多依赖于这样一个事实,即相应数据是只读的(采集后),索引可以基于时间(或大小)。因此可以根据我们期望的保留期轻松删除它们。在这个架构中,我们将 Elasticsearch 节点分为两种类型:“热”和“温”。
热节点保存最新数据,因而需要处理所有索引负载。由于最近的数据通常是最常被查询的,因此热节点是我们集群中最强大的节点:存储速度快、内存容量大、CPU 性能出色。但是,这种超高配置也意味着成本高昂,所以在热节点上存储不常查询的旧数据并不划算。
另一方面,温节点将以更具成本效益的方式专用于长期存储。温节点上的数据不像热节点上那样经常可能被查询,集群内的数据将根据我们的计划保留期从热节点移到温节点(通过分片分配过滤实现),同时仍然可供在线查询。
从 Elastic Stack 6.3 开始,我们一直在构建新功能,以增强热温架构并简化对基于时间的数据进行处理的过程。
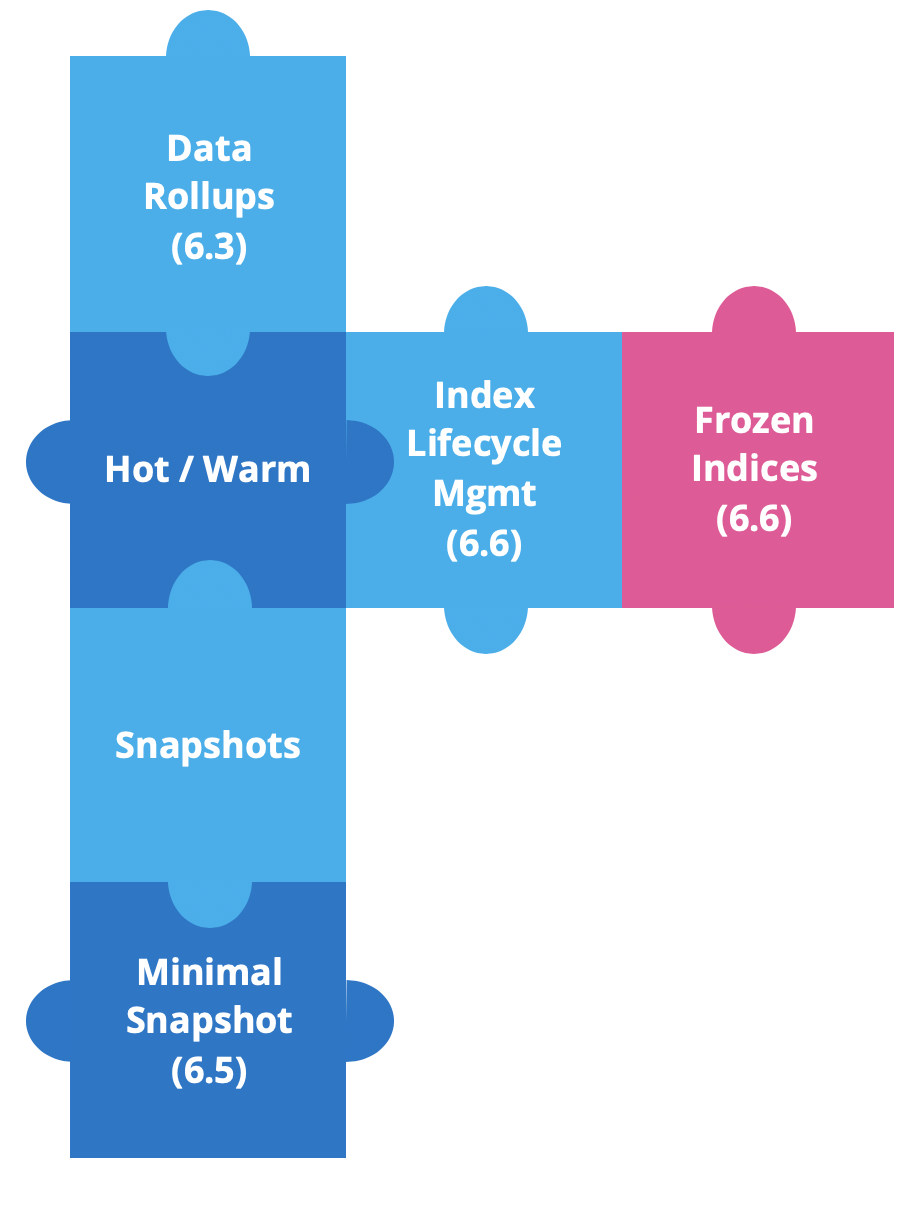
数据汇总最先在 6.3 版中推出,用于节省存储空间。在时序数据中,我们需要获取最新数据的细粒度细节。但是我们不太可能对历史数据有同样的需求,因为我们通常将数据集视为一个整体。这样,汇总功能就应运而生了;从版本 6.5 开始,我们可以在 Kibana 中创建、管理和可视化汇总数据。
不久之后,我们添加了仅源快照。这最大限度减少了快照数量,进而显著减少了所需的存储空间;其缺点在于,如果我们想要恢复数据和进行查询,就必须重新索引数据。这从 6.5 版开始就可以使用了。
在 6.6 版中,我们发布了两个强大的功能:索引生命周期管理 (ILM) 和冻结索引
ILM 提供了随时间推移自动管理索引的方法。它简化了索引从热到热的移动,当索引太旧时允许删除,或者自动强制将索引合并到一个段。
在这篇博客的剩余部分,我们将讨论冻结指数。
为什么冻结指数?
“旧”数据最大的难点之一是,不管年龄多大,指数仍然有很大的内存足迹。即使我们把它们放在冷节点上,它们仍然使用堆。
一个可能的解决方案是关闭索引。如果我们关闭一个索引,它不需要内存,但是我们需要重新打开它来运行搜索。重新打开索引将导致操作成本,并且还需要在关闭之前使用的堆。
在每个节点上,内存(堆)与存储的比率将限制每个节点的可用存储量。对于内存密集型场景,它可能低至 1:8(内存:数据),对于要求较低的内存用例,它可能接近 1:100。
这就是冻结指数的来源。如果我们可以有仍然打开的索引——让它们保持可搜索性——但不占据堆会怎么样?我们可以向保存冻结索引的数据节点添加更多存储,打破 1:100 的比率,理解搜索可能会变慢的折衷。
当我们冻结一个索引时,它变成只读的,它的临时数据结构从内存中删除。反过来,当我们对冻结的索引运行查询时,我们必须将数据结构加载到内存中。搜索冻结的索引不一定要很慢。Lucene 很大程度上依赖于文件系统缓存,它可能有足够的容量将索引的大部分保留在内存中。在这种情况下,每个碎片的搜索速度相当。然而,冻结的索引仍然受到限制,使得每个节点同时只执行一个冻结的碎片。与未冻结的索引相比,这一方面可能会降低搜索速度。
冻结是如何工作的
冻结的索引通过专用的搜索节流线程池进行搜索。默认情况下,这使用单个线程,以确保冻结的索引一次一个地加载到内存中。如果正在进行并发搜索,它们将进入队列以添加额外的保护措施,防止节点耗尽内存。
因此,在热-温架构中,我们现在能够将索引从热转换为温,然后能够在归档或删除之前冻结它们,从而降低硬件需求。
在冻结索引之前,为了降低基础架构成本,我们必须对数据进行快照和归档,这增加了巨大的运营成本。如果我们需要再次搜索,就必须恢复数据。现在,我们可以保持历史数据可供搜索,而不需要很大的内存占用。如果我们需要在已经冻结的索引上再次写入,我们可以解冻它。

如何冻结 Elasticsearch 索引
冻结索引易于在集群中实现,因此让我们开始学习如何使用冻结索引 API 以及如何搜索冻结索引。
首先,我们将从在测试索引上创建一些样本数据开始。
POST /sampledata/_doc
{
"name":"Jane",
"lastname":"Doe"
}
POST /sampledata/_doc
{
"name":"John",
"lastname":"Doe"
}
然后检查我们的数据是否被摄入。这将返回两次点击:
GET /sampledata/_search
作为最佳实践,在冻结索引之前,建议首先运行 force_merge。这将确保每个碎片在磁盘上只有一个片段。它还将提供更好的压缩,并简化我们在对冻结索引运行聚合或排序搜索请求时所需的数据结构。在具有多个段的冻结索引上运行搜索可能会产生高达多个数量级的显著性能开销。
POST /sampledata/_forcemerge?max_num_segments=1
下一步是通过取消冻结索引 API 端点来调用对我们的索引的冻结。
POST /sampledata/_freeze
搜索冻结索引
现在它被冻结了,你会发现常规搜索不起作用。其原因是,为了限制每个节点的内存消耗,冻结的索引被限制。 由于我们可能会错误地锁定冻结的索引,我们将通过向请求中添加 ignore_throttled=false 来防止意外减速。
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
现在,我们可以通过运行以下请求来检查新索引的状态:
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
这将返回与以下类似的结果,索引状态为“open”:
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
如上所述,我们必须保护集群不会耗尽内存,因此我们可以在节点上同时加载用于搜索的冻结索引的数量是有限的。搜索受限线程池中的线程数默认为 1,默认队列为 100。这意味着如果我们运行一个以上的请求,它们将排队多达一百个。我们可以通过以下请求监控线程池状态,以检查队列和拒绝:
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
它应该返回类似以下内容的响应:
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
冻结的指数可能会慢一些,但可以用非常有效的方式进行预过滤。还建议将请求参数 pre_filter_shard_size 设置为1。
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
这不会给查询增加很大的消耗,并且允许我们利用通常的场景。例如,当在时间序列索引上搜索日期范围时,并非所有碎片都匹配。
如何写入冻结的 Elasticsearch 索引
如果我们试图写一个已经冻结的索引会发生什么?让我们去寻找答案。
POST /sampledata/_doc
{
"name":"Janie",
"lastname":"Doe"
}
发生什么事了?冻结的索引是只读的,因此写入被阻止。我们可以在索引设置中检查这些:
GET /sampledata/_settings?flat_settings=true
将返回:
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
我们必须使用解冻索引 API,调用索引上的解冻端点。
POST /sampledata/_unfreeze
现在我们将能够创建第三个文档并搜索它。
POST /sampledata/_doc
{
"name":"Janie",
"lastname":"Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
解冻只能在特殊情况下进行。请记住,在再次冻结索引之前,一定要运行“force_merge”,以确保最佳性能。
在 Kibana 使用冻结指数
首先,我们需要加载一些样本数据,比如样本飞行数据。
点击“Add”按钮获取样本飞行数据。
现在,我们应该能够通过单击“View data”按钮来查看加载的数据。仪表板将与这个相似。
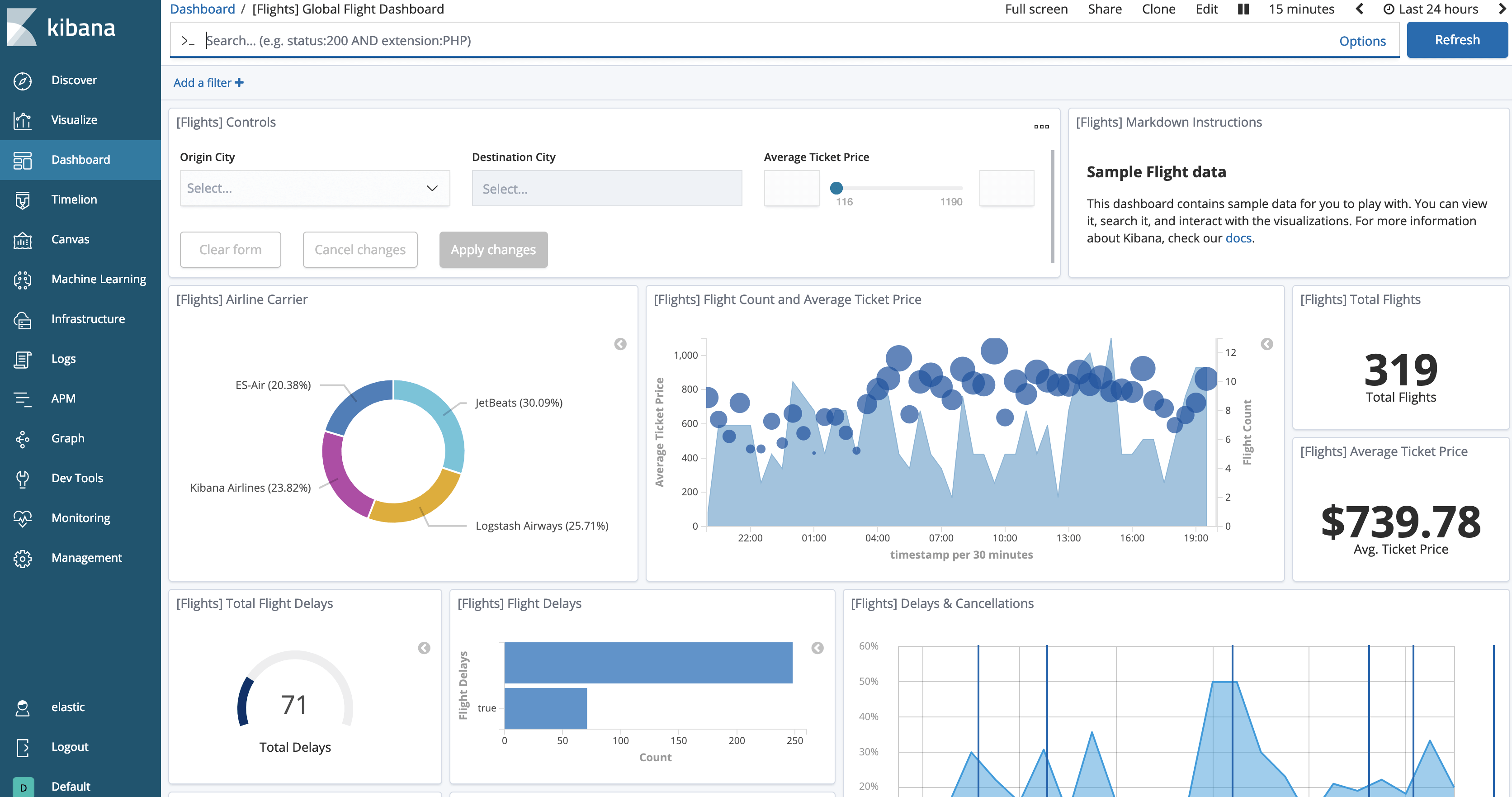
现在我们可以测试冻结指数:
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
如果我们回到仪表板,我们会注意到数据显然已经“disappeared”。
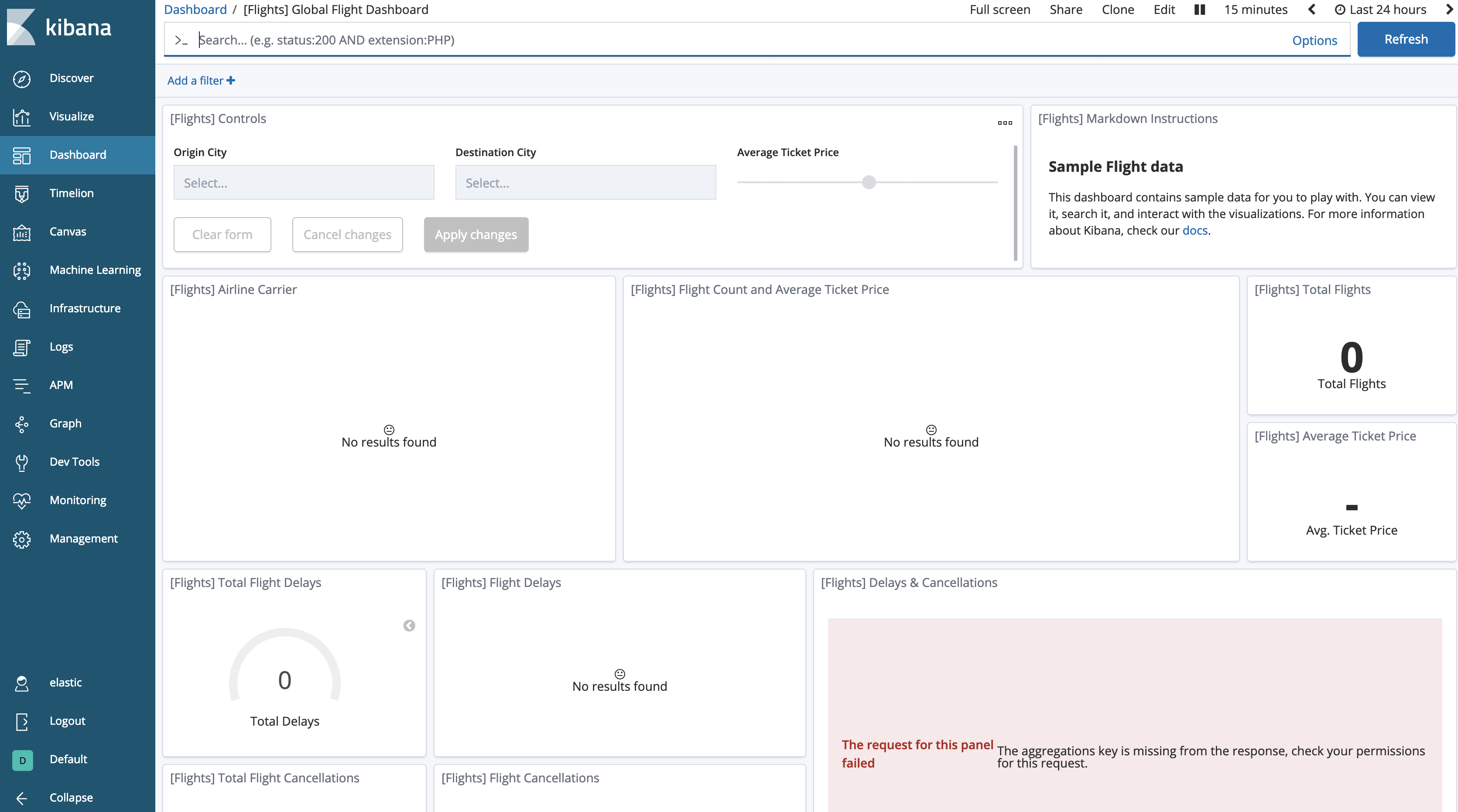
我们需要告诉 Kibana 允许搜索冻结的索引,默认情况下是禁用的。
转到 Kibana 管理,选择高级设置。在搜索部分,您会发现“Search in frozen indices”被禁用。切换以启用和保存更改。

航班的仪表板会再次显示数据。
总结
冻结指数是热-温架构中非常强大的工具。它们提供了一个更具成本效益的解决方案,可以在保留在线搜索的同时提高保留率。我建议您用硬件和数据测试搜索延迟,以便为冻结的索引提供合适的大小和搜索延迟。
查看 Elasticsearch 文档,了解有关冻结索引 API 的更多信息。一如既往,如果您有任何问题,请联系我们的讨论论坛。冻结快乐!