如何将数据采集到 Elasticsearch 服务
对于数据搜索和分析来说,Elasticsearch 无处不在。开发人员和社区可利用 Elasticsearch 寻找寻找各种各样的用例,从应用程序搜索和网站搜索,到日志、基础架构监测、APM 和 安全分析,不一而足。虽然现在有针对这些用例的免费解决方案,但是开发人员首先需要将其数据提供给 Elasticsearch。
本文将描述几种最常见的将数据采集到 Elasticsearch 服务的方法。这可能是一个托管在 Elastic Cloud 或其本地方案 Elastic Cloud Enterprise 上的集群。虽然我们主要关注于这些服务,但采集到自管型 Elasticsearch 集群的数据看起来几乎是相同的。唯一的变化是您处理集群的方式。
在我们深入探讨技术细节之前,提醒一下:如果您在阅读本文时遇到任何问题,请随时访问 discuss.elastic.co。我们的社区非常活跃,您有望会在那里找到问题的答案。
接下来,我们开始使用以下方法来深入探讨数据采集:
- Elastic Beats
- Logstash
- 语言客户端
- Kibana 开发工具
采集到 Elasticsearch 服务
Elasticsearch 提供了灵活的 RESTful API,用于与客户端应用程序通信。因此,REST 调用被用来采集数据、执行搜索和数据分析,以及管理集群及其索引。实际上,上述所有方法都依赖于这个 API 将数据采集到 Elasticsearch。
在本文后续介绍中,我们假设您已经创建了 Elasticsearch 服务集群。如果您还没有创建,请注册 Elastic Cloud 免费试用。在您创建集群后,系统将会为您提供 Elastic 超级用户帐户的云 ID 和密码。云 ID 的格式如下:cluster_name:ZXVy...Q2Zg==。它对您集群的 URL 进行了编码,并且我们将会看到,它可简化数据采集。
Elastic Beats
Elastic Beats 是一组轻量型的数据采集器,可以方便地将数据发送给 Elasticsearch 服务。由于是轻量型的,Beats 不会产生太多的运行时开销,因此,可以在硬件资源有限的设备(如 IoT 设备、边缘设备或嵌入式设备)上运行和收集数据。如果您需要收集数据,但没有资源来运行资源密集型数据收集器,那么 Beats 会是您最佳的选择。这种无处不在(涵盖所有联网设备)的数据收集方式,让您能够快速检测到异常情况做出反应,例如系统范围内的问题和安全事件等。
当然,Beats 并不局限于资源有限的系统,它们还可用于具有更多可用硬件资源的系统。
Beats 系列:概述
Beats 有多种风格,可以收集不同类型的数据:
- Filebeat 支持您从以文件形式提供的源中读取、预处理和传送数据。尽管大多数用户使用 Filebeat 来读取日志文件,但它也支持任何非二进制文件格式。Filebeat 还支持许多其他数据源,包括 TCP/UDP、容器、Redis 和 Syslog。借助丰富的模块,可以轻松针对 Apache、MySQL 和 Kafka 等常见应用程序的日志格式收集和解析相应的数据。
- Metricbeat 可收集并预处理系统和服务指标。系统指标包括关于运行中进程的相关信息,以及 CPU/内存/磁盘/网络利用率方面的数据。这些模块可用于收集来自许多不同服务的数据,包括 Kafka、Palo Alto Networks、Redis,等等。
- Packetbeat 可收集并预处理实时网络数据,从而支持应用程序监测、安全和网络性能分析。此外,Packetbeat 还支持以下协议:DHCP、DNS、HTTP、MongoDB、NFS 和 TLS。
- Winlogbeat 可从 Windows 操作系统捕获事件日志,包括应用程序事件、硬件事件,以及安全和系统事件。对于许多用例来说,从 Windows 事件日志中获得的大量信息非常有用。
- Auditbeat 可检测对关键文件的更改并从 Linux 审计框架收集事件。不同的模块简化了它的部署,这主要在安全分析用例中使用。
- Heartbeat 利用探测来监测系统和服务的可用性。因此,Heartbeat 在许多场景中都很有用,比如基础架构监测和安全分析。ICMP、TCP 和 HTTP 都是受支持的协议。
- Functionbeat 可从无服务器环境(如 AWS Lambda)中收集日志和指标。
一旦您决定了在特定场景中要使用哪个 Beats,入门就像下节所描述的那样,非常简单。
Beats 入门
在这部分中,我们将以 Metricbeat 为例,学习如何开始使用 Beats。对于其他 Beats,步骤大同小异。针对您具体的 Beat 和操作系统,请参考本文档并按照下列步骤进行操作。
- 下载并安装所需的 Beat。安装 Beats 有很多种方法,但大多数用户都会选择使用为操作系统的包管理器提供的 Elastic 存储库 (DEB/RPM),或者简单下载并解压缩所提供的 tgz/zip 包。
- 配置 Beat 并启用任何所需的模块。
- 例如,要收集系统上运行的关于 Docker 容器的指标,则通过
sudo metricbeat modules enable docker启用 Docker 模块(如果您使用包管理器安装)。如果您通过解压缩 tgz/zip 包安装,则使用/metricbeat modules enable docker。 - 云 ID 是一种简便的方法,用以指定收集的数据要发送到的 Elasticsearch 服务。将云 ID 和身份验证信息添加到 Metricbeat 配置文件 (Metricbeat .yml):
cloud.id: cluster_name:ZXVy...Q2Zg==
cloud.auth: "elastic:YOUR_PASSWORD"
- 如前所述,
cloud.id是在创建集群时提供给您的。cloud.auth是一个冒号分隔的用户名和密码的串联,且已在 Elasticsearch 集群中被授予足够的权限。 - 若要快速启动,可以使用在创建集群时提供的 Elastic 超级用户和密码。如果您使用包管理器安装,则可以在
/etc/metricbeat目录下找到配置文件;如果您使用 tgz/zip 包安装,则在解压缩的目录下。
- 将预装仪表板加载到 Kibana。大多数 Beats 和它们的模块都带有预先定义好的 Kibana 仪表板。如果您使用包管理器安装,则通过
sudo metricbeat setup将它们加载到 Kibana;如果使用 tgz/zip 包安装,则在解压缩的目录下运行./metricbeat setup。
- 运行 Beat。如果您在基于 systemd 的 Linux 系统上使用包管理器安装,则使用
sudo systemctl start metricbeat;如果您使用 tgz/zip 包安装,则使用./metricbeat -e
如果一切正常,数据就会开始流入 Elasticsearch 服务。
探索预装仪表板
前往 Elasticsearch 服务中的 Kibana 来查看数据:
- 在 Kibana Discover 中,选择
metricbeat-*索引模式,您将能够看到已采集的各个文档。 - “Kibana 基础架构”选项卡通过以各种图表形式显示有关系统资源(CPU、内存、网络)的使用情况,让您能够以更图形化的方式检查系统和 Docker 指标。
- 在 Kibana 仪表板中,选择任意带有 [Metricbeat System] 前缀的仪表板,以交互方式查看数据。
Logstash
Logstash 是一个强大而灵活的工具,可以读取、处理和传送任何类型的数据。Logstash 提供了许多功能,这些功能目前还不可用,或者通过 Beats 执行成本太高,比如通过对外部数据源执行查找来丰富文档。不管采用哪种方式,Logstash 的这种功能和灵活性都是有代价的。此外,Logstash 的硬件要求也显著高于 Beats。严格来说,Logstash 通常不应部署在低资源设备上。因此,在 Beats 功能不足以满足特定用例要求的情况下,可将 Logstash 用作其替代选择。
一种常见的架构模式是将 Beats 和 Logstash 组合起来:使用 Beats 来收集数据,并使用 Logstash 来执行 Beats 无法执行的任何数据处理。
Logstash 概述
Logstash 通过执行事件处理管道来工作,其中每个管道至少包含以下各项中的一个:
- 输入从数据源读取数据。官方支持多种数据源,包括文件、http、imap、jdbc、kafka、syslog、tcp 和 udp。
- 过滤器以多种方式处理和丰富数据。在许多情况下,首先需要将非结构化的日志行解析为更加结构化的格式。因此,除其他功能外,Logstash 还在正则表达式的基础上提供了解析 CSV、JSON、键/值对、分隔的非结构化数据和复杂的非结构化数据的过滤器(grok 过滤器)。Logstash 还提供了更多的过滤器,通过执行 DNS 查找,添加关于 IP 地址的地理信息,或通过对自定义目录或 Elasticsearch 索引执行查找来丰富数据。通过这些附加的过滤器,能够对数据进行各种转换,例如重命名、删除、复制数据字段和值(mutate 过滤器)。
- 输出将解析后并加以丰富的数据写入数据接收器,这是 Logstash 处理管道的最后阶段。虽然有许多输出插件可用,但这里我们主要讨论如何使用 Elasticsearch 输出将数据采集到 Elasticsearch 服务。
Logstash 示例管道
没有两个用例是相同的。因此,您可能必须开发符合自身特定数据输入和需求的 Logstash 管道。
我们提供了一个示例 Logstash 管道,该管道能够
- 读取 Elastic 博客 RSS 源
- 通过复制/重命名字段和删除特殊字符及 HTML 标记来执行一些简单的数据预处理
- 将文档采集到 Elaticsearch
步骤如下:
- 通过包管理器或下载并解压 tgz/zip 文件来安装 Logstash。
- 安装 Logstash rss 输入插件,这可支持读取 RSS 数据源:
./bin/logstash-plugin install logstash-input-rss - 将下列 Logstash 管道定义复制到一个新文件,例如 ~/elastic-rss.conf:
input {
rss {
url => "/blog/feed"
interval => 120
}
}
filter {
mutate {
rename => [ "message", "blog_html" ]
copy => { "blog_html" => "blog_text" }
copy => { "published" => "@timestamp" }
}
mutate {
gsub => [
"blog_text", "<.*?>", "",
"blog_text", "[\n\t]", " "
]
remove_field => [ "published", "author" ]
}
}
output {
stdout {
codec => dots
}
elasticsearch {
hosts => [ "https://<your-elsaticsearch-url>" ]
index => "elastic_blog"
user => "elastic"
password => "<your-elasticsearch-password>"
}
}
- 在上面的文件中,修改参数主机和密码,以匹配您的 Elasticsearch 服务端点和 Elastic 用户密码。在 Elastic Cloud 中,您可以从部署页的详细信息中获取 Elasticsearch 端点 URL(复制端点 URL)。
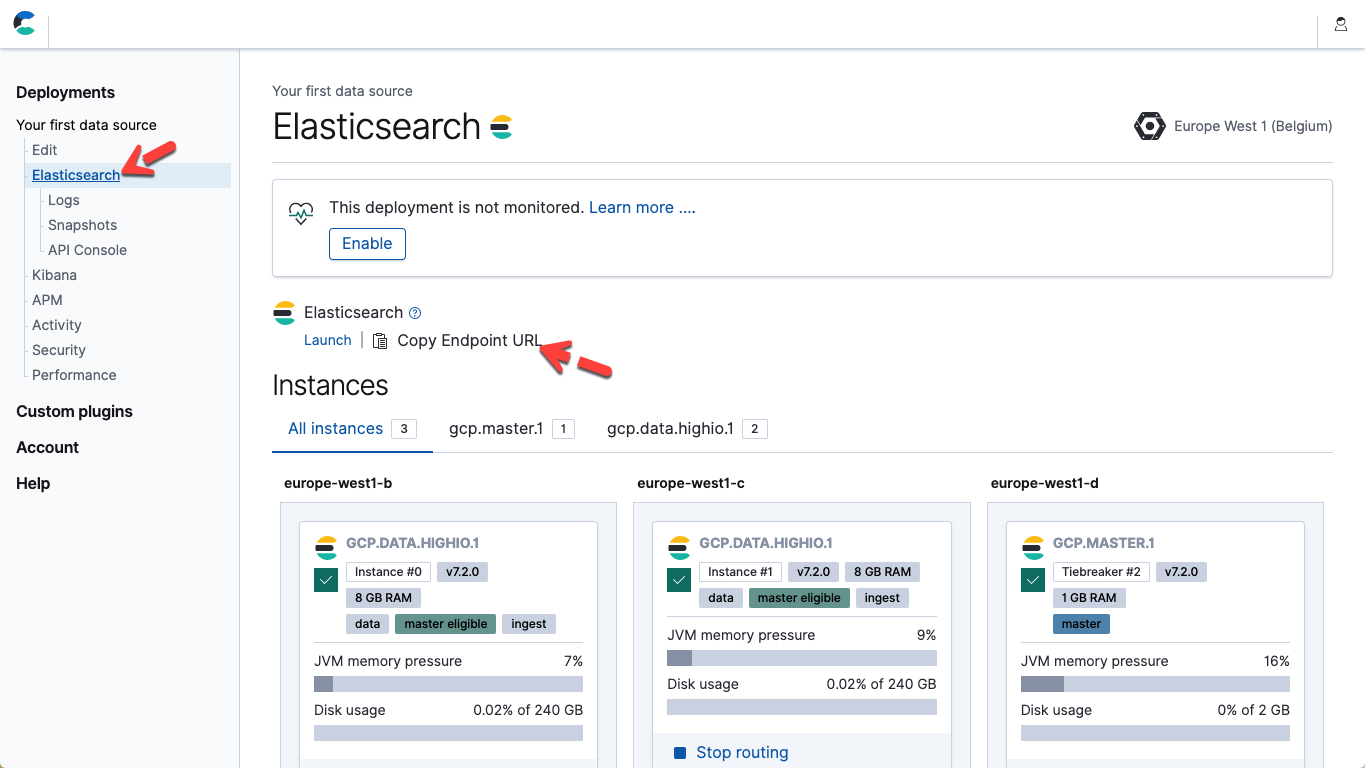
- 通过启动 Logstash 执行管道:./bin/logstash -f ~/elastic-rss.conf
启动 Logstash 需要几秒钟的时间。您会在控制台上看到出现圆点 (.....)。每个点表示一个已采集到 Elasticsearch 的文档。
- 打开 Kibana。在 Kibana 开发工具控制台中,执行以下操作,以确认已经采集了 20 个文档:POST elastic_blog/_search
语言客户端
在某些情况下,最好将数据采集与自定义应用程序代码集成。为此,我们建议使用一个官方支持的 Elasticsearch 客户端。这些客户端是抽象出数据采集低层细节的库,使您能够专注于特定应用程序的实际工作。Java、JavaScript、Go、.NET、PHP、Perl、Python 和 Ruby 都有官方客户端。有关您所选语言的所有详细信息和代码示例,请参阅相关文档即可。如果您的应用程序不是用上面所列语言编写的,则很可能会有社区贡献的客户端。Kibana 开发工具
我们推荐的用于开发和调试 Elasticsearch 请求的工具是 Kibana 开发工具控制台。开发工具公开了通用的 Elasticsearch REST API 的全部功能和灵活性,同时抽象出了底层 HTTP 请求的技术细节。不出所料,您可以使用开发工具控制台将原始 JSON 文档放到 Elasticsearch 中:PUT my_first_index/_doc/1
{
"title" :"How to Ingest Into Elasticsearch Service",
"date" :"2019-08-15T14:12:12",
"description" :"This is an overview article about the various ways to ingest into Elasticsearch Service"
}