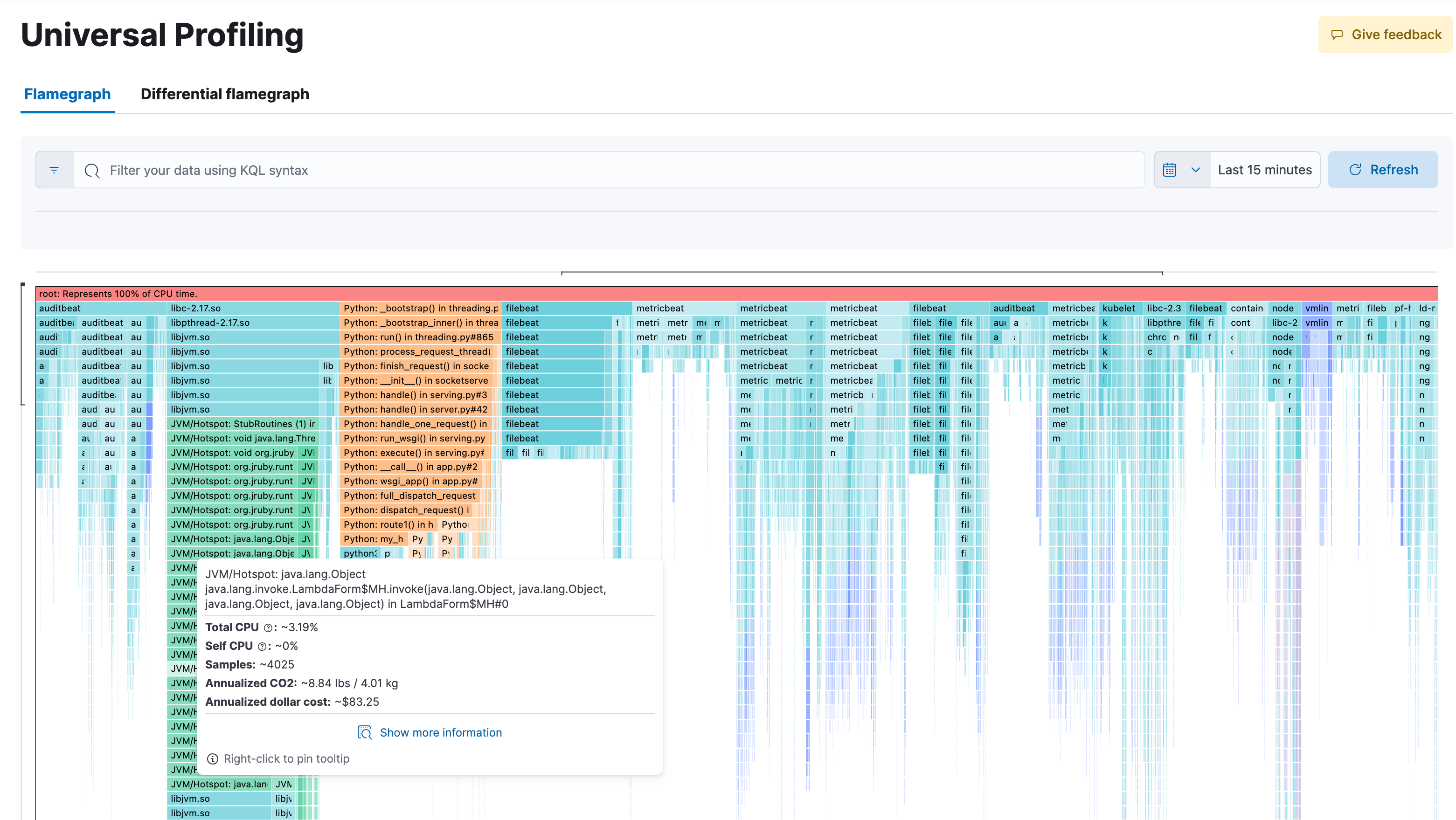
持续性能分析,就是好用
利用全天候的全系统性能分析,在所有级别上获得前所未有的可见性。借助 eBPF 技术和 OpenTelemetry,Universal Profiling 对运行在机器上的每一行代码进行性能分析——不仅包括您的应用程序代码,还包括内核和第三方库。通过仅以非强迫性方式采集必要数据,它能够在生产系统上连续运行,且不会造成可观测到的影响(CPU 开销不到 1%)!无需侵入性代码变更或插桩。
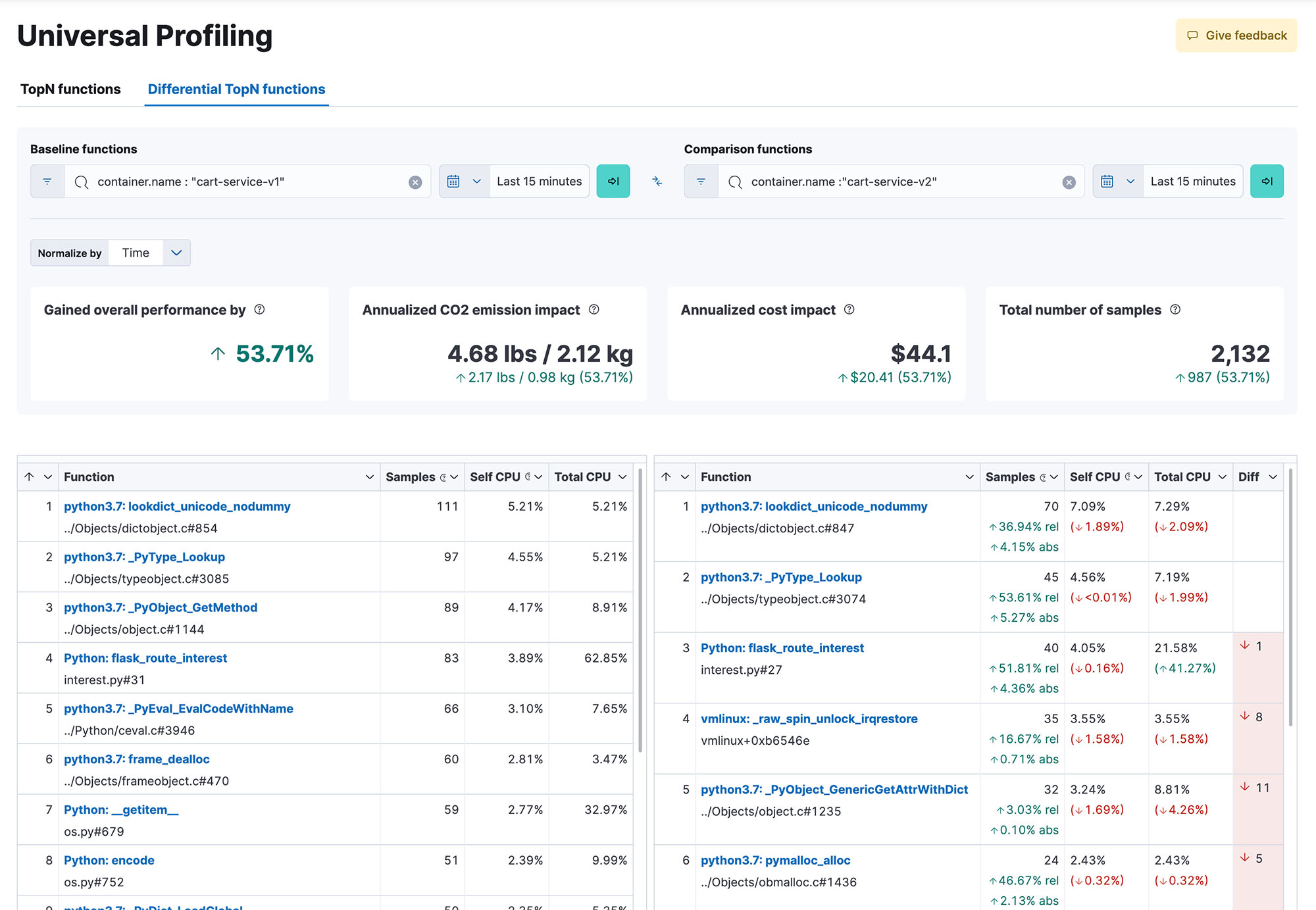
性能优化,易如反掌
在代码执行过程中,跨方法、类别、线程和容器获得有关您所有代码的全系统可见性,而且还能跨内部版本进行比较以确定性能回归状况。借助快速响应、简单易用的火焰图表,您从单个视图中即可了解整个系统的性能。精确定位最耗费资源的代码,从而找出并解决性能瓶颈,优化云支出,并减少基础架构的碳足迹。
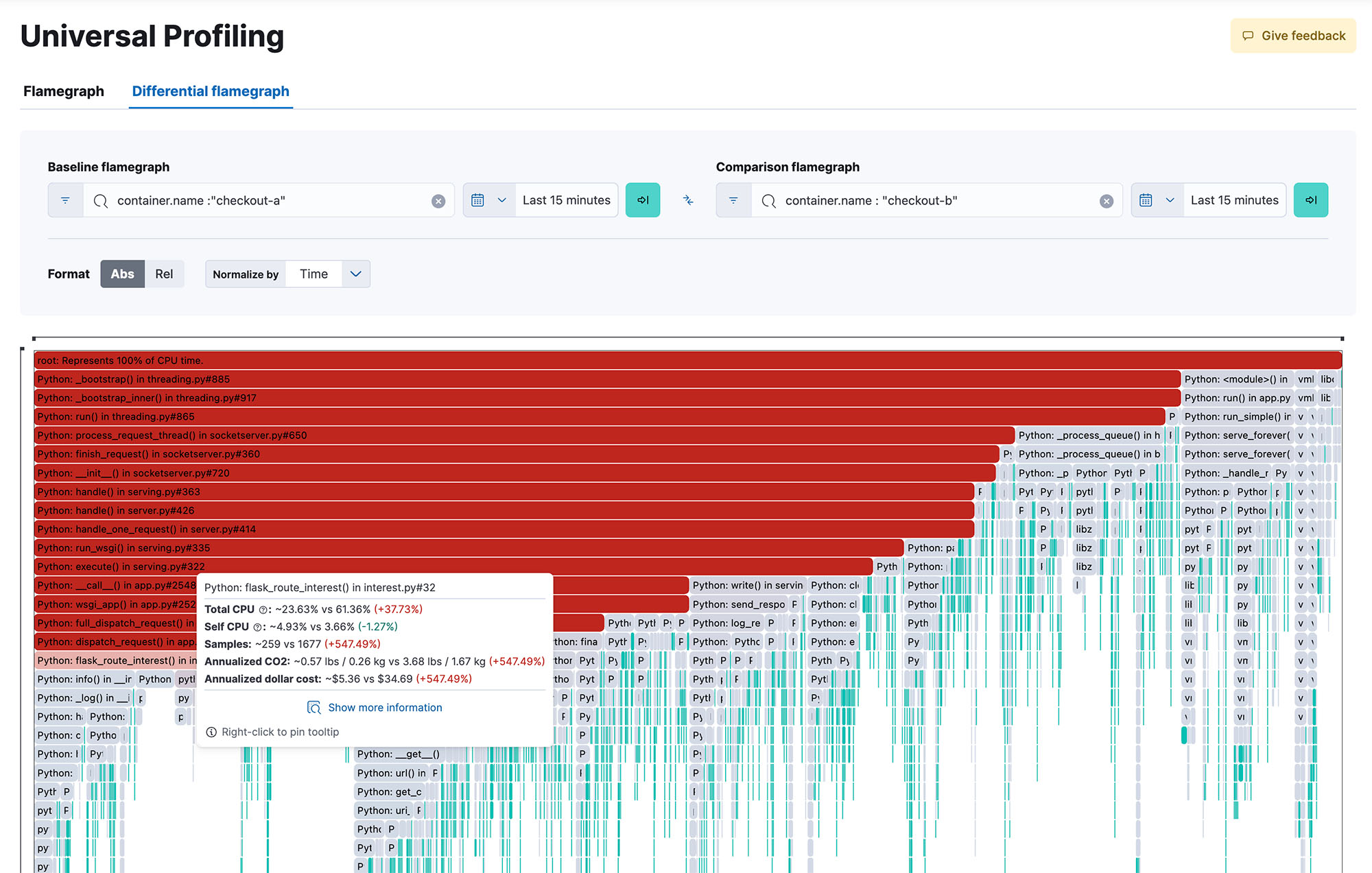
灵活且流畅的部署
Elastic Universal Profiling 不需要进行任何应用程序源代码变更、检测或其他侵入性操作。只需部署代理,就能在几分钟后收到性能分析数据。代理可以使用 Elastic Agent 进行部署,既可作为原生二进制文件或作为具有特权的 Docker 容器手动运行,也可以使用您集群的编排框架自动部署。
广泛的生态系统支持
性能分析支持包括几乎所有常用语言运行时的混合语言跟踪,其中包括:PHP、Python、Java(或任何 JVM 语言)、Go、Rust、C/C++、Node.js/V8、Ruby、Perl 和 Zig。还包括对所有主要容器化和编排框架的卓越支持,无论是在本地运行还是在托管 Kubernetes 平台(例如 GKE、AKS 或 EKS)上运行皆可。

持续的全系统性能分析只是观测工作负载的一种方式
监测基础架构、日志和用户 — 一个解决方案全部搞定。