Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
These days everyone is talking about ChatGPT. One of the cool features of this large language model (LLM) is the ability to generate code. We used it to generate Elasticsearch DSL queries. The goal is to search in Elasticsearch
® with sentences like “Give me the first 10 documents of 2017 from the stocks index.” This experiment showed that it is possible, with some limitations. In this post, we describe this experiment and the open source library that we published for this use case.
Can ChatGPT generate Elasticsearch DSL?
We start the experiment with some tests focusing on the ability of ChatGPT to generate Elasticsearch DSL query. For this scope, you need to provide some context to ChatGPT about the structure of the data that you want to search.
In Elasticsearch, data is stored in an index, which is similar to a "table" in a relational database. It has a mapping that defines multiple fields and their types. This means we need to provide the mapping information of the index that we want to query. By doing so, ChatGPT has the necessary context to translate the query into Elasticsearch DSL.
Elasticsearch offers a get mapping API to retrieve the mapping of an index. In our experiment, we used a stocks index data set available here. This data set contains five years of stock prices of 500 Fortune companies, spanning from February 2013 to February 2018.
Here we reported the first five lines of the CSV file containing the data set:
Each line contains the date of the stock, the open value of the day, the high and the low values, the close value, the volume of the stocks exchanged, and finally the stock name — for example, American Airlines Group Inc. (AAL).
The mapping associated to the stocks index is as follows:
We can use the GET %2Fstocks%2F_mapping API to retrieve the mapping from Elasticsearch.
[Related article: ChatGPT and Elasticsearch: OpenAI meets private data]
Let's build a prompt to find out
In order to translate a query expressed in human language to Elasticsearch DSL, we need to find the right prompt to give to ChatGPT. This is the most difficult part of the process: to actually program ChatGPT using the correct question format (in other words, the right prompt).
After some iterations, we ended up with the following prompt that seems to work quite well:
The value {mapping} and query} in the prompt are two placeholders to be replaced with the mapping json string (for example, returned by the GET %2Fstocks%2F_mapping in the previous example) and the query expressed in human language (for example: Return the first 10 documents of 2017).
Of course, ChatGPT is limited and in some cases it won’t be able to answer a question. We found that, most of the time, this happens because the sentence used in the prompt is too general or ambiguous. To solve this situation, we need to enhance the prompt using more details. This process is called iteration, and it requires multiple steps to define the proper sentence to be used.
If you want to try out how ChatGPT can translate a search sentence in an Elasticsearch DSL query (or even SQL), you can use dsltranslate.com.
Putting it all together
Using the ChatGPT API offered by OpenAI and the Elasticsearch API for mapping and search, we put it all together in an experimental library for PHP.
This library exposes a search() function with the following API:
Where $index is the index name to be used, $prompt is the query expressed in human language and $bool is an optional parameter for using a cache (enabled by default).
The process of this function is reported in the following diagram:
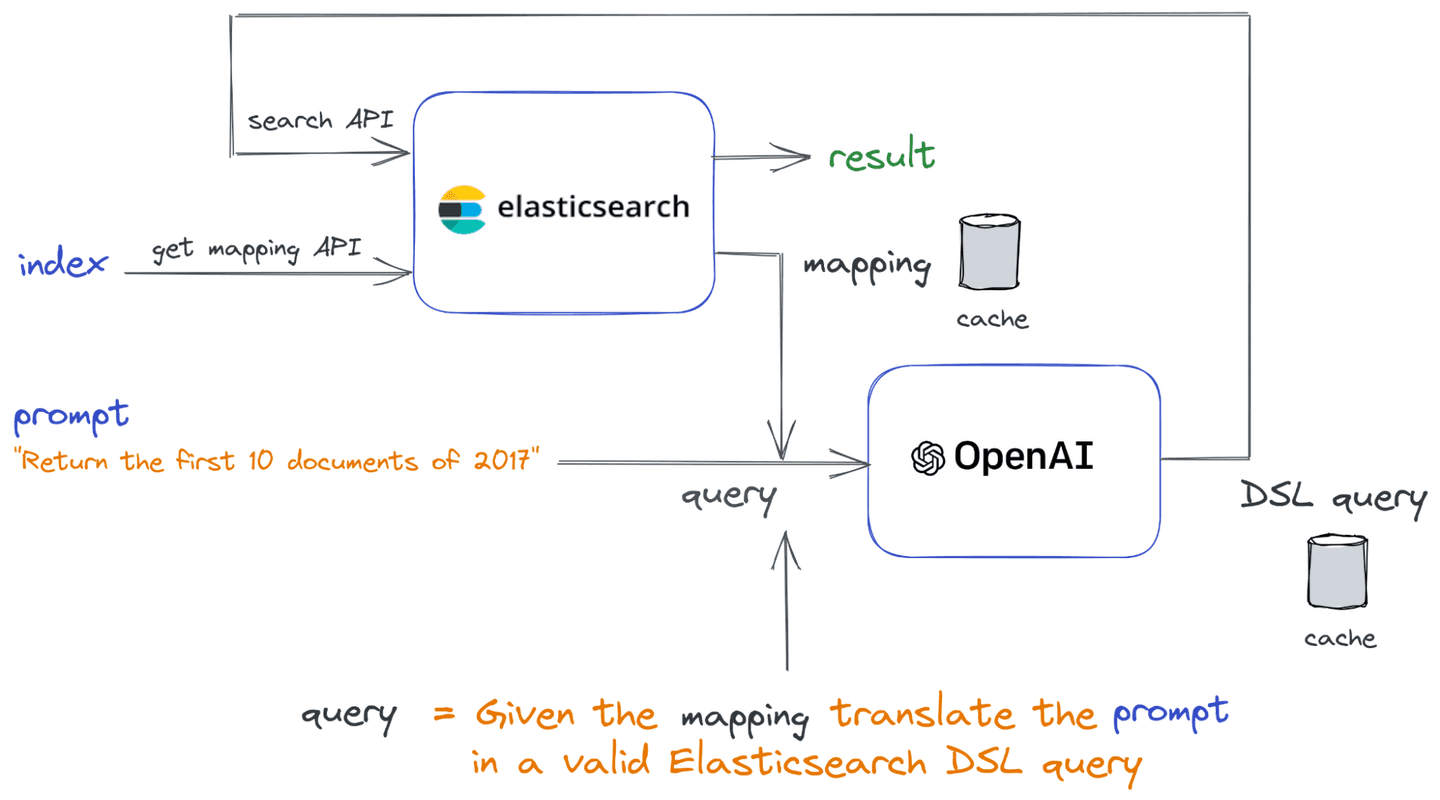
The inputs are index and prompt (on the left). The index is used to retrieve the mapping from Elasticsearch (using the get mapping API). The result is a mapping in JSON that is used to build the query string to send to ChatGPT using the following API code. We used the gpt-3.5-turbo model of OpenAI that is able to translate in code.
The result from ChatGPT contains an Elasticsearch DSL query that we use to query Elasticsearch. The result is then returned to the user. To query Elasticsearch, we utilized the official elastic%2Felasticsearch-php client.
To optimize response time and reduce the cost of using the ChatGPT API, we used a simple caching system based on files. We used a cache to:
- Store the mapping JSON returned by Elasticsearch: We store this JSON in a file named after the index. This allows us to retrieve the mapping information without making additional calls to Elasticsearch.
- Store the Elasticsearch DSL generated by ChatGPT: To cache the generated Elasticsearch DSL, we named the cache file using the hash (MD5) of the prompt used. This approach enables us to reuse previously generated Elasticsearch DSL for the same query, eliminating the need to call the ChatGPT API again.
We also added the possibility to retrieve the Elasticsearch DSL programmatically using the getLastQuery() function.
Running the experiment with financial data
We used Elastic Cloud to store the stocks value reported here. In particular, we used a simple bulk script to read the stocks file in CSV and send it to Elasticsearch using the bulk API.
For more details on how to set up an Elastic Cloud and retrieve the API key, read the documentation.
Once we stored the stocks index, we used a simple PHP script for testing some query expressed in English. The script we used is examples%2Ftest.php.
To execute this examples%2Ftest.php script, we need to set three environment variables:
- OPENAI_API_KEY: the API key of OpenAI
- ELASTIC_CLOUD_ENDPOINT: the url of the Elasticsearch instance
- ELASTIC_CLOUD_API_KEY: the API key of Elastic Cloud
Using the stocks mapping, we tested the following queries recording all the Elasticsearch DSL responses:
As you can see, the results are pretty good. The last one about the difference between closed and open fields was quite impressive!
All the requests have been translated in a valid Elasticsearch DSL query that is correct according to the question expressed in natural language.
Use the language you speak!
A very nice feature of ChatGPT is the ability to specify questions in different languages.
That means you can use this library and specify the query in different natural languages, like Italian, Spanish, French, German, and so on.
Here is an example:
All the previous search have the same results producing the following Elasticsearch query (more or less):
Important: ChatGPT is an LLM that has been optimized for English, which means the best results are obtained using queries entered in English.
Limitations of LLMs
Unfortunately, ChatGPT and LLMs in general are not capable of verifying the correctness of the answer from a semantic point of view. They give answers that look right from a statistical point of view. This means, we cannot test if the Elasticsearch DSL query generated by ChatGPT is the right translation of the query in natural language.
Of course, this is a big limitation at the moment. In some other use cases, like mathematical operations, we can solve the correctness problem using an external plugin, like the Wolfram Plugin of ChatGPT. In this case, the result of ChatGPT uses the Wolfram engine that checks the correctness of the response, using a mathematical symbolic model.
Apart from the correctness limitation, which implies we should always check ChatGPT’s answers, there are also limitations to the ability to translate a human sentence in an Elasticsearch DSL query.
For instance, using the previous stocks data set if we ask something as follows:
The DSL query generated by ChatGPT is not valid producing this Elasticsearch error:
Failed to parse date field [2015-01-01] with format [yyyy].
If we rephrase the sentence using more specific information, removing the apparent ambiguity about the date format, we can retrieve the correct answer, as follows:
Basically, the sentence must be expressed using a description of how the Elasticsearch DSL should be rather than a real human sentence.
Wrapping up
In this post, we presented an experimental use case of ChatGPT for translating natural language search sentences into Elasticsearch DSL queries. We developed a simple library in PHP for using the OpenAI API to translate the query under the hood, providing also a caching system.
The results of the experiment are promising, even with the limitation on the correctness of the answer. That said, we will definitely investigate further the possibility to query Elasticsearch in natural language using ChatGPT, as well as other LLM models that are becoming more and more popular.
Learn more about the possibilities with Elasticsearch and AI.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Related Content

March 4, 2026
Entity resolution with Elasticsearch, part 3: Optimizing LLM integration with function calling
Learn how function calling enhances LLM integration, enabling a reliable and cost-efficient entity resolution pipeline in Elasticsearch.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.