From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
In this article, we will learn to deploy and test the new Apple Models and build a RAG system to emulate Apple Intelligence using Elastic as a vector database, and OpenELM as the model provider.
There’s a Notebook with the full exercise here.
Introduction to OpenELM
In April, Apple released their Open Efficient Language Models (OpenELM) in 270M, 450M, 1.1B and 3B parameters in both chat and instruct versions. Larger parameter models are usually better at complex tasks in exchange for being slower and more resource consuming, while smaller ones tend to be faster, less demanding. The election will depend on the problem we want to solve.
The creators highlight this model’s relevance from a research point of view, by making everything you need to train them available, and still show how their models have a higher performance with fewer parameters than their competitors, in some cases.
What is remarkable about these models is transparency, as everything needed to reproduce them is open, as opposed to those that only provide model weights and inference code, and carry out pre-training on private datasets.

Source: https://arxiv.org/abs/2404.14619
The framework used to generate and train these models (CoreNet) is also available.
One of the advantages of the OpenELM models is that they can migrate to MLX, which is a deep learning framework optimized for devices with Apple Silicon processors, so they can benefit from this technology by training local models for these devices.
Apple just released the new iphone and one of the new features is Apple Intelligence which leverages AI to help in tasks like notifications classification, context aware recommendations and email writing.
Let's build an app to achieve the same using Elastic and OpenELM!
The app flow is as follows:
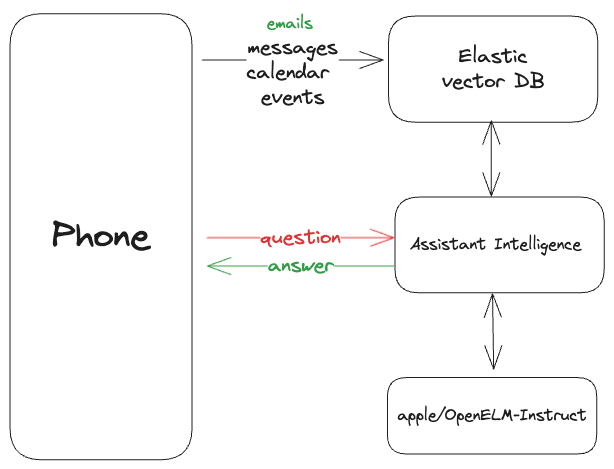
Steps
Deploying the OpenELM model
The first step is to deploy the model. You can find the full information about the models here: https://huggingface.co/collections/apple/openelm-instruct-models-6619ad295d7ae9f868b759ca
We’ll use the instruct models since we want our model to follow instructions rather than talking to it. Instruct models are trained for one shot requests rather than holding a conversation.
First, we need to clone the repository:
Then, you’ll need a HuggingFace access token here.
Next, you need to request access to the Llama-2-7b model inn HuggingFace to use the OpenELM tokenizer.
Afterwards, run the following command in the repository folder you’ve just cloned:
You should get a response similar to this:
Once upon a time there was a man named John Smith. He had been born in the small town of Pine Bluff, Arkansas, and raised by his single mother, Mary Ann. John's family moved to California when he was young, settling in San Francisco where he attended high school. After graduating from high school, John enlisted in the U.S. Army as a machine gunner. John's first assignment took him to Germany, serving with the 1st Battalion, 12th Infantry Regiment. During this time, John learned German and quickly became fluent in the language. In fact, it took him only two months to learn all 3,000 words of the alphabet. John's love for learning led him to attend college at Stanford University, majoring in history. While attending school, John also served as a rifleman in the 1st Armored Division. After completing his undergraduate education, John returned to California to join the U.S. Navy. Upon his return to California, John married Mary Lou, a local homemaker. They raised three children: John Jr., Kathy, and Sharon. John enjoyed spending time with
Done! We can send instructions using the command line, however, we want the model to use our information.
Indexing data
Now, we’ll index some documents in Elastic to use with the Model.
To fully use the power of semantic search, make sure you deploy the ELSER model, using the inference endpoint:
If this is your first time using ELSER, you might have to wait a bit. You can check the deployment progress at Kibana > Machine Learning > Trained Models
Now, we’ll create the index that will represent the data in the mobile phones where the agent has access.
We use copy_to to set the description field for both full text search, as well as semantic search. Now, let’s add the documents:
Testing the model
Now that we have the data and model, we just need to connect both for the model to do what we need.
We start by creating a function to build our system prompt. Since this is an instruct model, it doesn’t expect a conversation but rather to receive an instruction and return the result.
We’ll use a chat template to format the prompt.
Now, using semantic search, let’s add a function to fetch relevant documents from Elastic, based on the user’s questions:
Now, let’s try writing: "Summarize my emails". To make sending the prompt easier, we’ll call the function generate in the file generate_openelm.py instead of using the CLI.
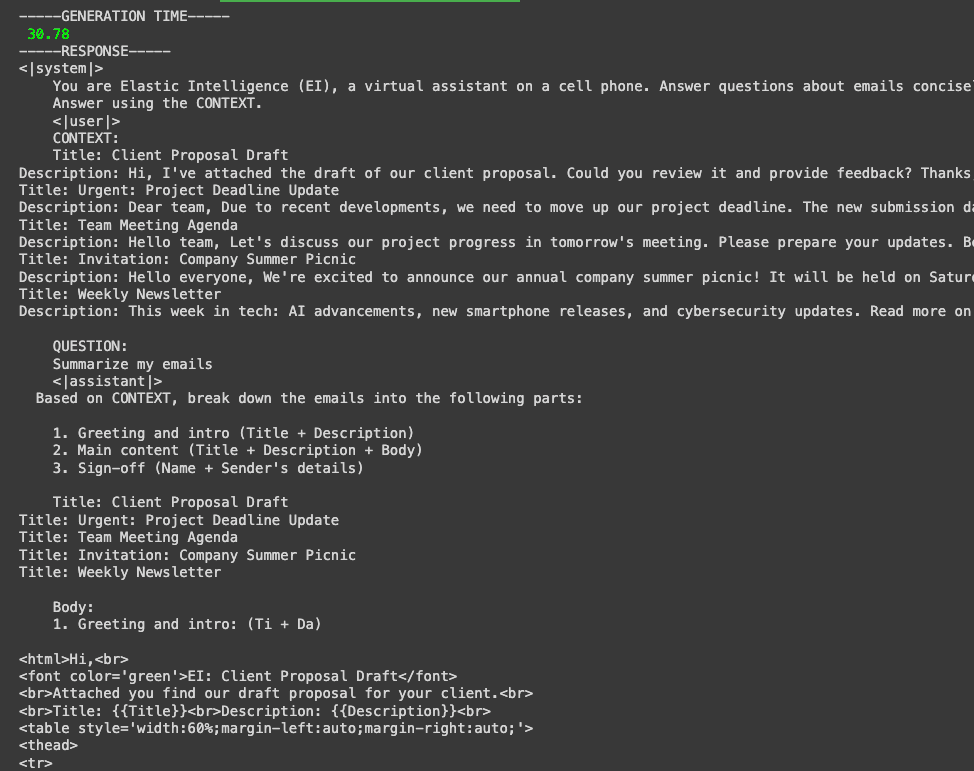
The first answers were varied and not very good. We got the right answer in some cases and in others not. The model returned details on its reasoning, HTML code or the mention of people who were not in the context.
If we limit the question to yes/no answers, the model behaves better. This makes sense since it’s a small model and has less thinking capacity.
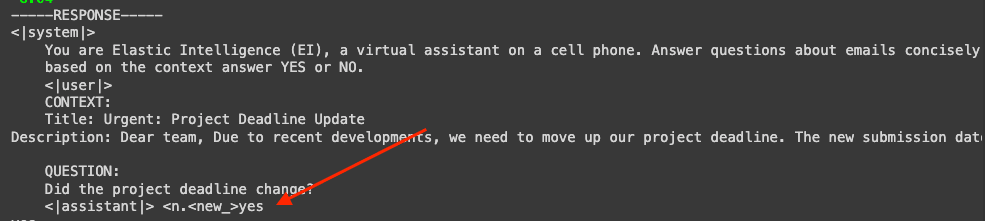
Now, let’s try a classification task:
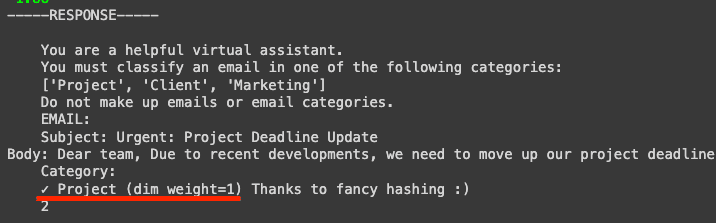
We see it takes a small loop but the model it’s able to classify the email correctly. This makes the model interesting for tasks like classifying emails or notification by topic or relevance. Another important thing to note is how sensitive this kind of models are to prompt variations. A small detail like how the task is described, can make answers vary greatly.
Experiment with the prompt until you achieve the desired result.
Conclusion
Though OpenLM models don’t try to compete at a business level, they provide an interesting alternative in experimental scenarios since they openly provide the complete training pipeline and have a highly customizable framework to use with your own data. They are ideal for developers that need offline, customized, and efficient models.
Results might not be as impressive as with other models, but the option to train this model from scratch is very appealing. In addition, the chance to migrate it to Apple Silicon using CoreNet opens the door to creating optimized local models for Apple devices. If you’re interested in how to migrate Open ELM to Silico processors, check out this repo.
Related Content
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.