本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
近实时搜索
edit近实时搜索
edit随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。
磁盘在这里成为了瓶颈。提交(Commiting)一个新的段到磁盘需要一个
fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。
但是 fsync 操作代价很大; 如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着 fsync 要从整个过程中被移除。
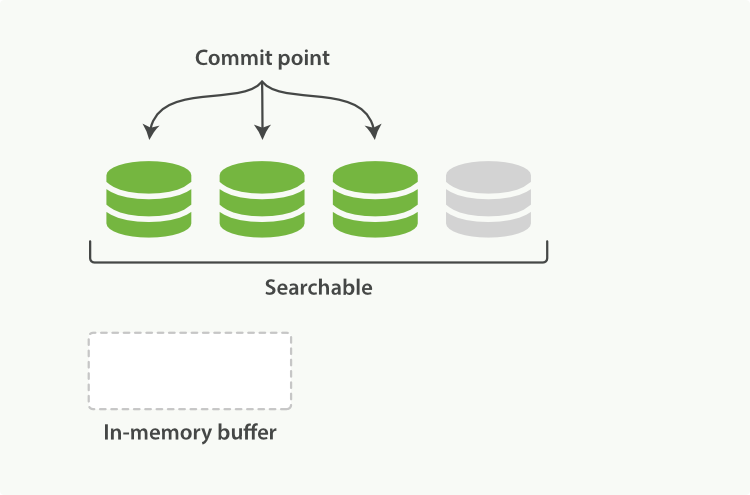
在Elasticsearch和磁盘之间是文件系统缓存。 像之前描述的一样, 在内存索引缓冲区( Figure 19, “在内存缓冲区中包含了新文档的 Lucene 索引” )中的文档会被写入到一个新的段中( Figure 20, “缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交” )。 但是这里新段会被先写入到文件系统缓存—这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
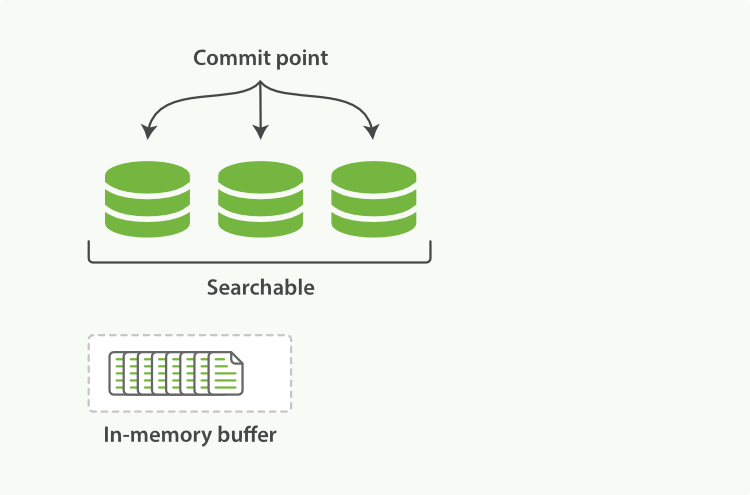
Lucene 允许新段被写入和打开—使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
refresh API
edit在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索,
可以通过设置 refresh_interval , 降低每个索引的刷新频率:
refresh_interval 可以在既存索引上进行动态更新。
在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings { "refresh_interval": -1 } PUT /my_logs/_settings { "refresh_interval": "1s" }
refresh_interval 需要一个 持续时间 值, 例如 1s (1 秒) 或 2m (2 分钟)。
一个绝对值 1 表示的是 1毫秒 --无疑会使你的集群陷入瘫痪。
本页导航