请注意:
本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
处理冲突
edit处理冲突
edit当我们使用 index API 更新文档 ,可以一次性读取原始文档,做我们的修改,然后重新索引 整个文档 。
最近的索引请求将获胜:无论最后哪一个文档被索引,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到 Elasticsearch 中并使其可被搜索。 也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是 非常严重的 。试想我们使用 Elasticsearch 存储我们网上商城商品库存的数量, 每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。
有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。 假设有两个 web 程序并行运行,每一个都同时处理所有商品的销售,如图 Figure 7, “Consequence of no concurrency control” 所示。
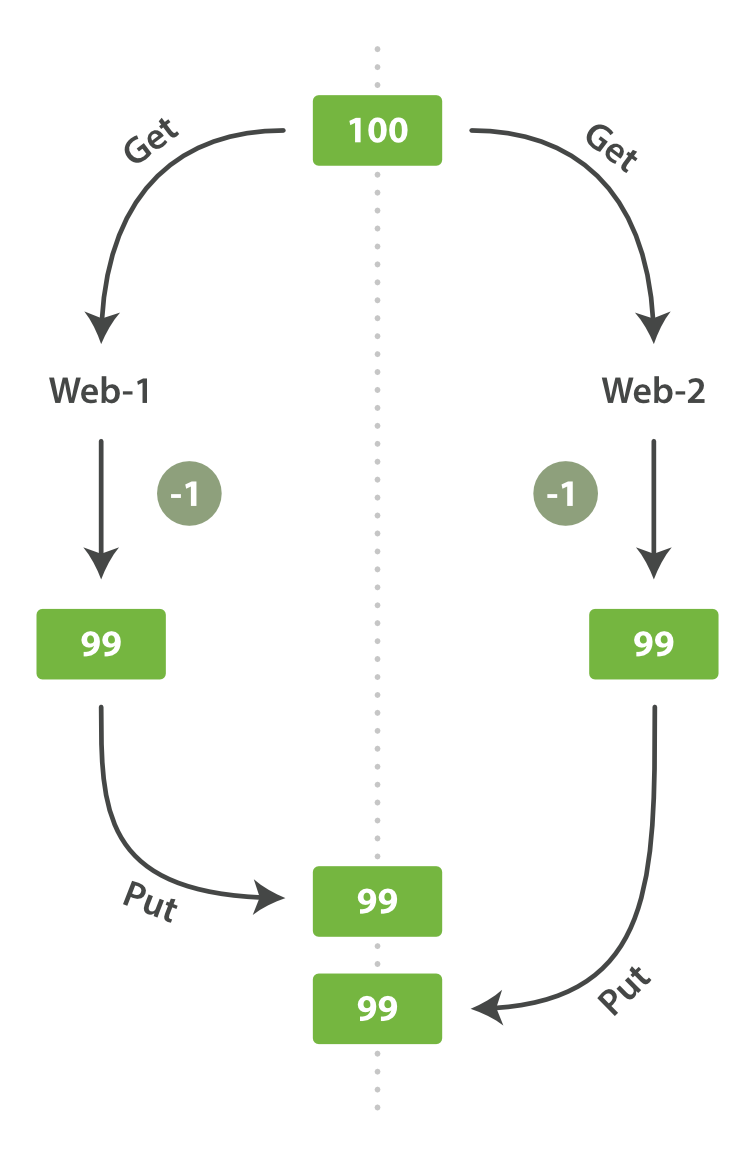
Figure 7. Consequence of no concurrency control
web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。
结果我们会认为有超过商品的实际数量的库存,因为卖给顾客的库存商品并不存在,我们将让他们非常失望。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
- 悲观并发控制
- 这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
- 乐观并发控制
- Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Was this helpful?
Thank you for your feedback.