WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Fetch Phase
editFetch Phase
editThe query phase identifies which documents satisfy the search request, but we still need to retrieve the documents themselves. This is the job of the fetch phase, shown in Figure 15, “Fetch phase of distributed search”.
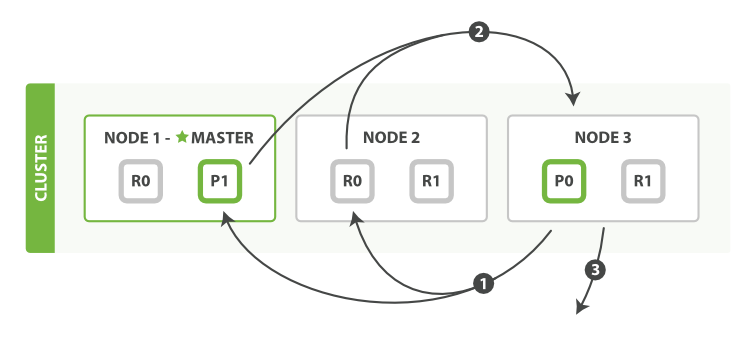
The distributed phase consists of the following steps:
-
The coordinating node identifies which documents need to be fetched and
issues a multi
GETrequest to the relevant shards. - Each shard loads the documents and enriches them, if required, and then returns the documents to the coordinating node.
- Once all documents have been fetched, the coordinating node returns the results to the client.
The coordinating node first decides which documents actually need to be
fetched. For instance, if our query specified { "from": 90, "size": 10 },
the first 90 results would be discarded and only the next 10 results would
need to be retrieved. These documents may come from one, some, or all of the
shards involved in the original search request.
The coordinating node builds a multi-get request for each shard that holds a pertinent document and sends the request to the same shard copy that handled the query phase.
The shard loads the document bodies—the _source field—and, if
requested, enriches the results with metadata and
search snippet highlighting.
Once the coordinating node receives all results, it assembles them into a
single response that it returns to the client.