WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
How Primary and Replica Shards Interact
editHow Primary and Replica Shards Interact
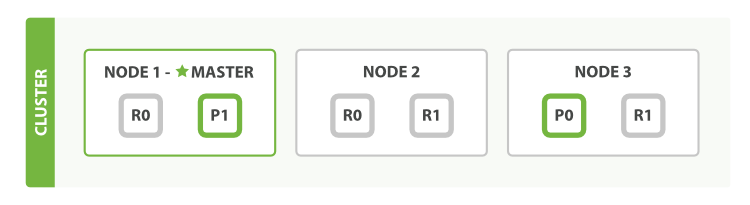
editFor explanation purposes, let’s imagine that we have a cluster
consisting of three nodes. It contains one index called blogs that has
two primary shards. Each primary shard has two replicas. Copies of
the same shard are never allocated to the same node, so our cluster
looks something like Figure 8, “A cluster with three nodes and one index”.
We can send our requests to any node in the cluster. Every node is fully
capable of serving any request. Every node knows the location of every
document in the cluster and so can forward requests directly to the required
node. In the following examples, we will send all of our requests to Node 1,
which we will refer to as the coordinating node.
When sending requests, it is good practice to round-robin through all the nodes in the cluster, in order to spread the load.