- Machine Learning: other versions:
- Setup and security
- Getting started with machine learning
- Anomaly detection
- Data frame analytics
Data frame analytics feature processors
editData frame analytics feature processors
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
Data frame analytics automatically includes a Feature encoding phase, which transforms categorical features into numerical ones. If you want to have more control over the encoding methods that are used for specific fields, however, you can define feature processors. If there are any remaining categorical features after your processors run, they are addressed in the automatic feature encoding phase.
The feature processors that you defined are the part of the analytics process, when data comes through the aggregation or pipeline, the processors run against the new data. The resulting features are ephemeral; they are not stored in the index. This provides a mechanism to create features that can be used at search and ingest time and don’t take up space in the index.
Refer to the feature_processors property of the
Create data frame analytics job API to learn more.
Available feature processors:
Frequency encoding
editFrequency encoding takes into account how many times a given categorical feature is present in relation to the value of the encoded field. The more frequently the feature is present, the greater the weight of the feature in the data set. With this encoding technique, it is not possible to get back to the categorical values after the encoding is done as different categories may have the same frequency.
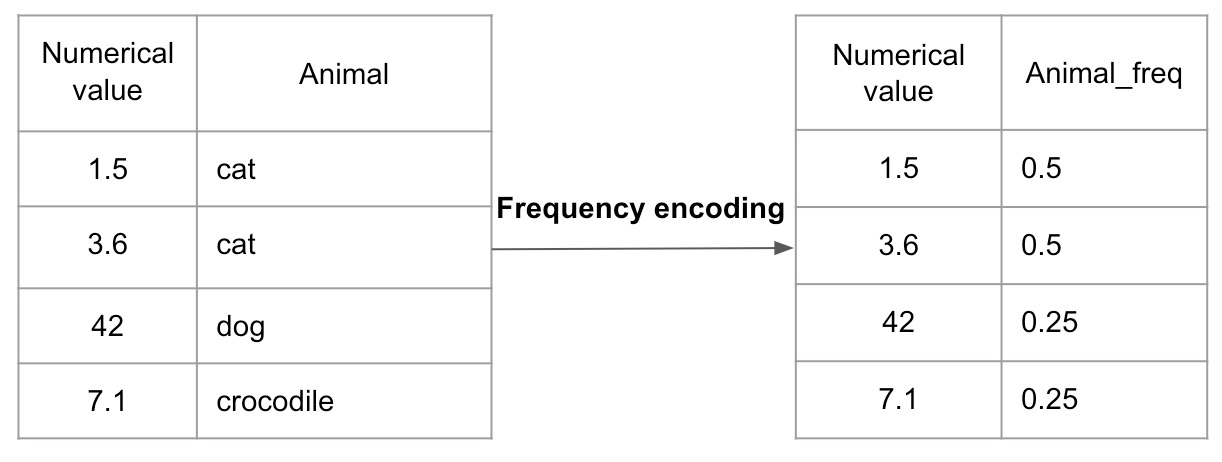
The figure shows a simple frequency encoding example. The Animal_freq value of
cat is 0.5 as the feature is present at half of the number of related values.
The labels dog and crocodile occur only once each. For this reason, the
Animal_freq value of these labels is 0.25.
NGram encoding
editNGram encoding encodes a string into a collection of ngrams (a sequence of n items) of a configured length. The output of this encoding is categorical. Consequently, additional automatic processing will be done to the resulting ngrams.

The table shows the NGram encoding of the Animal field. It executes unigram and bigram encoding (ngram of size 1 and 2) and goes to the string length of 3.
One hot encoding
editOne hot encoding transforms categorical values into numerical ones by assigning vectors to each category. The vector represents whether the corresponding feature is present (1) or not present (0) at the given value, so the encoding method maps the different categorical features to the numerical values.
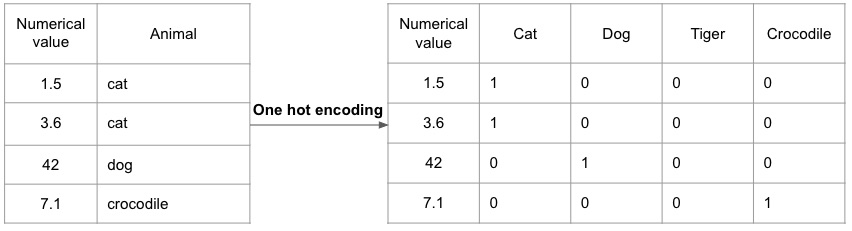
One hot encoding maps each category to the corresponding value. If the
category is present at a given value, the assigned vector is 1, if it is not,
the vector is 0.
Target mean encoding
editTarget mean encoding replaces categorical values with the mean value of the target variable as it relates to the categorical variable itself.
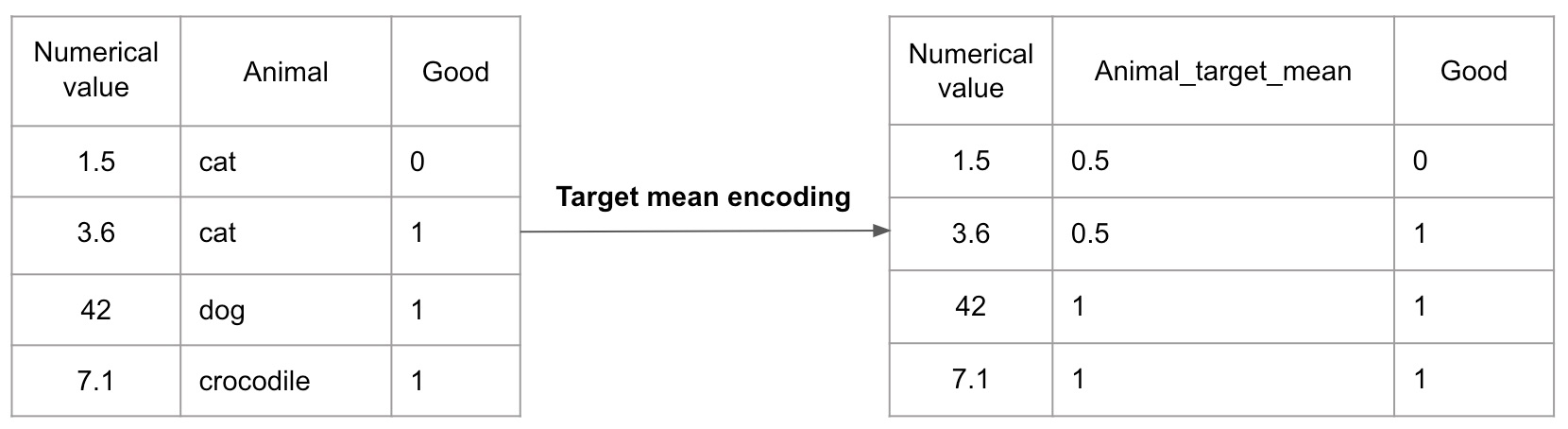
The figure shows a simple target mean encoding example. The label cat has
two occurrences in the data set. One of them has a corresponding target variable
of 0, the other one has a 1. The Animal_target_mean value of the cat
label is 0.5 after using the target mean encoding processor while the value of
dog and crocodile is 1 as each of their occurrences has a corresponding
target variable of 1.