- Machine Learning: other versions:
- What is Elastic Machine Learning?
- Setup and security
- Anomaly detection
- Finding anomalies
- Tutorial: Getting started with anomaly detection
- Advanced concepts
- API quick reference
- How-tos
- Generating alerts for anomaly detection jobs
- Aggregating data for faster performance
- Altering data in your datafeed with runtime fields
- Customizing detectors with custom rules
- Detecting anomalous categories of data
- Reverting to a model snapshot
- Detecting anomalous locations in geographic data
- Mapping anomalies by location
- Adding custom URLs to machine learning results
- Anomaly detection jobs from visualizations
- Exporting and importing machine learning jobs
- Resources
- Data frame analytics
- Natural language processing
Deploy the model in your cluster
editDeploy the model in your cluster
editAfter you import the model and vocabulary, you can use Kibana to view and manage their deployment across your cluster under Machine Learning > Model Management. Alternatively, you can use the start trained model deployment API.
You can deploy a model multiple times by assigning a unique deployment ID when starting the deployment.
You can optimize your deplyoment for typical use cases, such as search and ingest. When you optimize for ingest, the throughput will be higher, which increases the number of inference requests that can be performed in parallel. When you optimize for search, the latency will be lower during search processes. When you have dedicated deployments for different purposes, you ensure that the search speed remains unaffected by ingest workloads, and vice versa. Having separate deployments for search and ingest mitigates performance issues resulting from interactions between the two, which can be hard to diagnose.
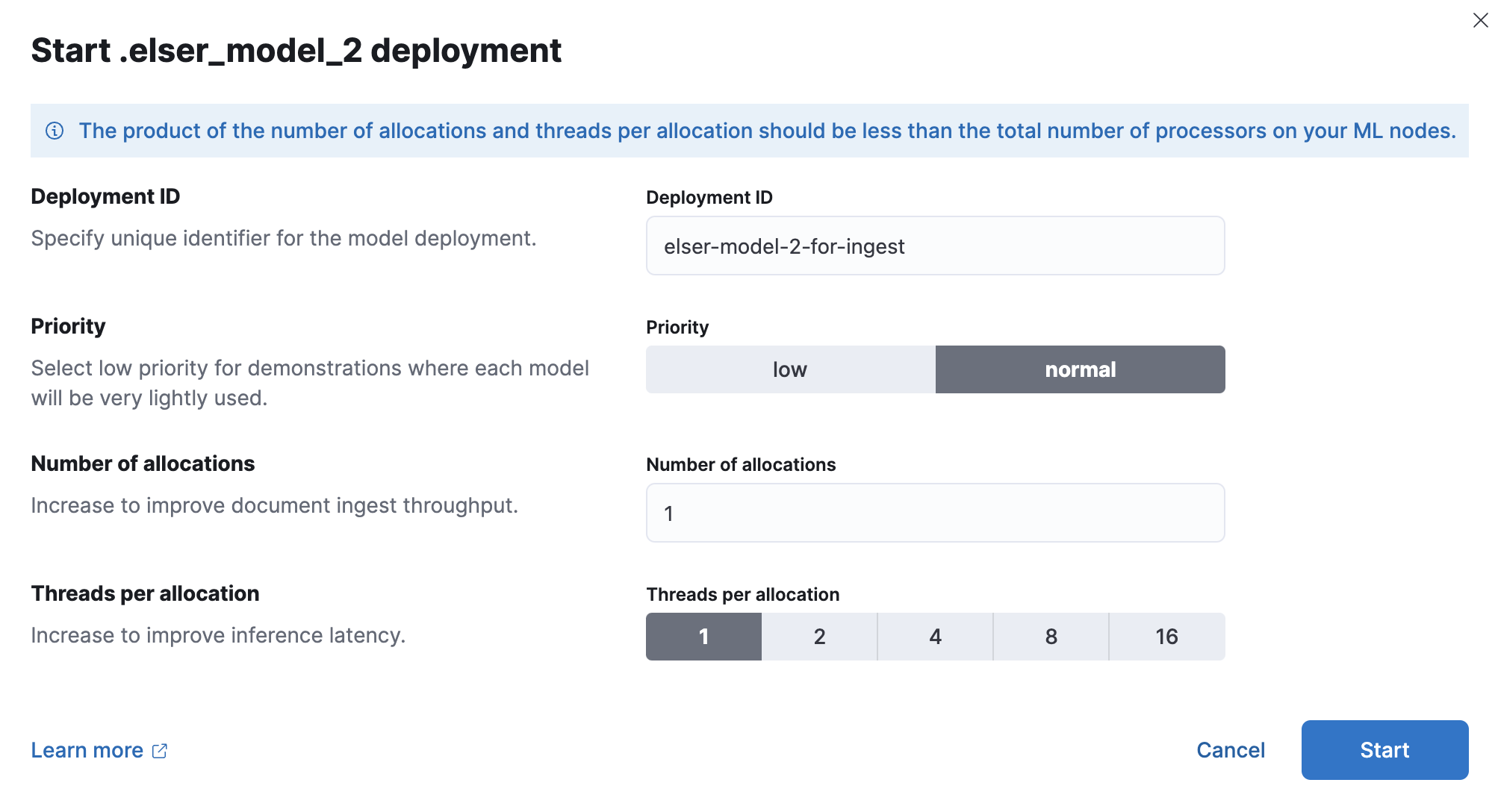
Each deployment will be fine-tuned automatically based on its specific purpose you choose.
Since eland uses APIs to deploy the models, you cannot see the models in Kibana until the saved objects are synchronized. You can follow the prompts in Kibana, wait for automatic synchronization, or use the sync machine learning saved objects API.
You can define the resource usage level of the NLP model during model deployment. The resource usage levels behave differently depending on adaptive resources being enabled or disabled. When adaptive resources are disabled but machine learning autoscaling is enabled, vCPU usage of Cloud deployments derived from the Cloud console and functions as follows:
- Low: This level limits resources to two vCPUs, which may be suitable for development, testing, and demos depending on your parameters. It is not recommended for production use
- Medium: This level limits resources to 32 vCPUs, which may be suitable for development, testing, and demos depending on your parameters. It is not recommended for production use.
- High: This level may use the maximum number of vCPUs available for this deployment from the Cloud console. If the maximum is 2 vCPUs or fewer, this level is equivalent to the medium or low level.
For the resource levels when adaptive resources are enabled, refer to <Trained model autoscaling.
Request queues and search priority
editEach allocation of a model deployment has a dedicated queue to buffer inference
requests. The size of this queue is determined by the queue_capacity parameter
in the
start trained model deployment API.
When the queue reaches its maximum capacity, new requests are declined until
some of the queued requests are processed, creating available capacity once
again. When multiple ingest pipelines reference the same deployment, the queue
can fill up, resulting in rejected requests. Consider using dedicated
deployments to prevent this situation.
Inference requests originating from search, such as the
text_expansion query, have a higher
priority compared to non-search requests. The inference ingest processor generates
normal priority requests. If both a search query and an ingest processor use the
same deployment, the search requests with higher priority skip ahead in the
queue for processing before the lower priority ingest requests. This
prioritization accelerates search responses while potentially slowing down
ingest where response time is less critical.
On this page