Elasticsearch 7.7.0 released
We are pleased to announce the release of Elasticsearch 7.7.0, based on Lucene 8.5.1. Version 7.7 is the latest stable release of Elasticsearch, and is now available for download or deployment via Elasticsearch Service on Elastic Cloud.
If you're ready to roll up your sleeves and get started, we have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.7.0 release notes
- Elasticsearch 7.7.0 breaking changes
While this blog will cover the most notable new and enhanced Elasticsearch features it's important to remember that our Elastic Enterprise Search, Observability, and Security solutions also received some significant updates of their own. To learn more about these updates, you might consider giving our other release blogs read.
Asynchronous search
Elasticsearch is fast: really, really fast. If you're a long time Elasticsearch user, you know that we've historically optimized for speed. Whether it's introducing new data structures, cutting down latency through adaptive replica selection, or optimizing for common use cases like sorting time-series data — Elasticsearch is on an unending quest to deliver relevant results faster.
However, we know our users sometimes want to be able to search through vast amounts of data no matter how long the search takes. We're talking potentially many petabytes of data. While it might not happen every single day, there are times when long running queries are required. Consider regulatory audits or threat hunting scenarios that need to search through years and years of data — data that has, in fact, likely been moved to more economical (cold) storage. This is where asynchronous search shines.
With the release of Elasticsearch 7.7, asynchronous search makes long-running queries feasible and reliable. Async search allows users to run long-running queries in the background, track the query progress, and retrieve partial results as they become available. Async search enables users to more easily search vast amounts of data with no more pesky timeouts.
This is only the beginning. In future releases of the Elastic Stack we expect async search to improve dashboard performance in Kibana, support live visualizations of partial results, and allow for even more massive datasets to be available for search by making snapshots searchable. Stay tuned: as we continue to work on features to address larger (and larger) data volumes from within a cluster, we expect async search will be a key foundation for us to build on.
Cluster admins: You asked, we listened
From the very beginning, the Elastic Stack has been free and open. And the "open" part is important. Elasticsearch is housed in public repositories and developed through a transparent approach with direct involvement from the community. And when the community asks, we listen.
Reduced consumption of heap
Cluster administrators know that excessive heap consumption can cause a number of administrative challenges. Having high heap pressure in an application like Elasticsearch can lead to search and indexing performance degradation or worse: OutOfMemory errors. Over the years, we've done a lot in Elasticsearch to drastically reduce heap consumption — from using an off-heap/on-disk column store to even allowing an index to be "frozen." And we've created safety valves to prevent OutOfMemory errors even in the worst case scenarios. Still, given the volume and retention of data in some security and observability use cases, there is sometimes a need to use larger heap sizes in the cluster.
With the release of Elasticsearch 7.7 we've dramatically reduced heap memory consumption for these time-series use cases by moving the terms index of the _id off heap. While having the terms index of _id on-heap was useful when indexing with explicit IDs, we studied how our community of users and customers were using Elasticsearch and realized that making this small change will help most cluster admins to maintain more economical clusters or to scale their existing clusters to hold more documents.
Password protected keystore
No one wants their data to be compromised. Elasticsearch has long provided a keystore to prevent unwanted access to sensitive cluster settings. With the release of Elasticsearch 7.7, the Elasticsearch keystore can optionally be password protected for additional security. This is a great example of how Elasticsearch, as the heart of the Elastic Stack, is continually working to introduce features that support all three of our primary solutions and to meet the demands of our users — irrespective of use case. If you're looking for additional tips on how to secure your cluster, see our recent blog on how to prevent an Elasticsearch server breach.
Painless scripting made easier
In 2016, with the release of Elasticsearch 5.0, we introduced Painless — a simple, fast, and secure scripting language designed specifically for use with Elasticsearch. Since that time Painless has seen wide adoption by our community. With the release of Elasticsearch 7.7 we're happy to announce the beta availability of the new Painless Lab (available in the Dev Tools section of Kibana). As a "playground" (of sorts), the Painless Lab not only makes getting started easier thanks to syntax highlighting but is also a great place for existing users to test out and debug their Painless scripts.
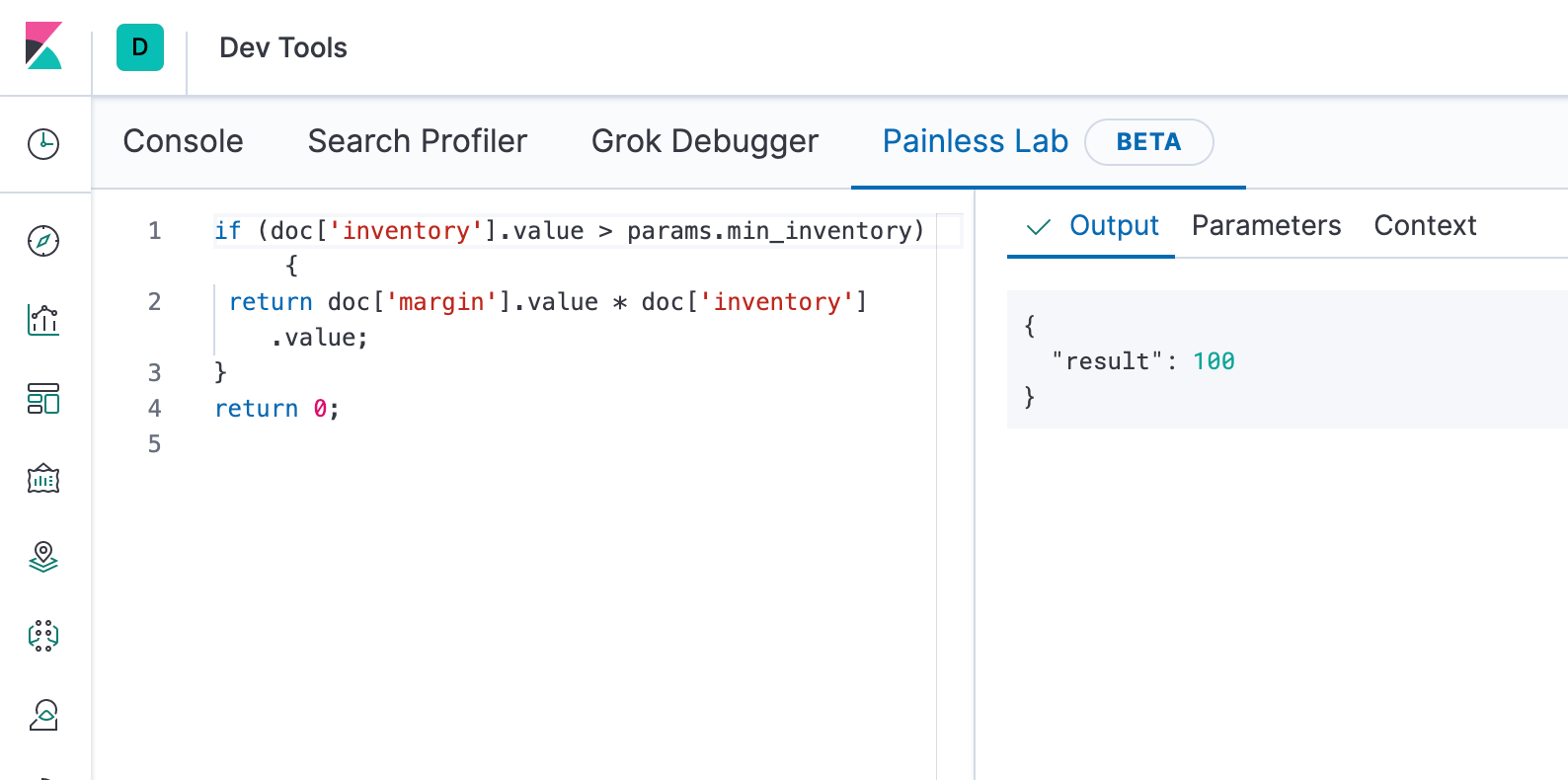
Testing out an example Painless script in the new Painless Lab.
Improved performance on time sorted queries
If you're reading this post top to bottom or if you've been using Elasticsearch for <any length of time>
With the release of Elasticsearch 7.0 we improved the performance of queries sorted by relevance (their "score") by a large margin for users that don't need an exact hit count. With the release of Elasticsearch 7.6, we used the same algorithm to significantly improve the performance of queries that were sorted by dates or numbers. With the release of Elasticsearch 7.7 we're delivering even faster results when querying time-based indices by filtering out entire shards if the shard doesn't contain any documents with competitive timestamps. This can have a tremendous impact on performance and a beneficial impact on required hardware costs.
Note that this performance enhancement does not "show up" when aggregations are requested.
In packaging news
Running Red Hat Enterprise Linux 8? CentOS 8? Windows 2019? Some good news: with the 7.7 release we're supporting Elasticsearch on all three platforms. In addition, with 7.7 we've added support for OpenJDK 14. For details please check our Elastic Support Matrix.
Also, while not yet supported, 7.7 marks the first release of official builds for Elasticsearch on ARM (note: machine learning is not yet enabled for aarch64 packages). For those of you working on non x86 platforms, we encourage you to kick the proverbial tires and let us know what you discover.
Want to get Elasticsearch up and running on Kubernetes? The official Elastic Helm charts for Elasticsearch, Kibana, Filebeat, and Metricbeat are now generally available. And if you're looking to operate, scale, and secure Elastic Stack on Kubernetes check out Elastic Cloud for Kubernetes (built on the Kubernetes Operator pattern).
That's not all, folks…
While the above listed features might have taken the spotlight, there were many more features (e.g., two new aggregations) included with the release of Elasticsearch 7.7. Be sure to check out the release highlights and the release notes for additional information.
Ready to get your hands dirty? Spin up a 14-day free trial on Elastic Cloud or download Elasticsearch today. Try it out. And be sure to let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.