Introdução à ES|QL (Elasticsearch Query Language)
Agilize a obtenção de insights criando agregações, visualizações e alertas diretamente do Discover com a ES|QL

 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
O que é a ES|QL (Elasticsearch Query Language)?
ES|QL (Elasticsearch Query Language) é a nova e inovadora linguagem de consulta com barras verticais da Elastic®, projetada para acelerar seus processos de análise e investigação de dados com poderosos recursos de computação e agregação.
Navegue pelas complexidades da identificação de ataques cibernéticos em andamento ou da detecção de problemas de produção com maior facilidade e eficiência.
A ES|QL não apenas simplifica a busca, a agregação e a visualização de grandes conjuntos de dados, mas também proporciona aos usuários recursos avançados como pesquisas e processamento em tempo real, tudo em uma única tela no Discover.
A ES|QL adiciona três recursos poderosos ao Elastic Stack
-
Um novo e rápido mecanismo de consulta distribuído e dedicado que melhora o _query. O novo mecanismo de consulta da ES|QL oferece recursos de busca avançados com processamento simultâneo, melhorando a velocidade e a eficiência, independentemente da fonte e da estrutura dos dados.. O desempenho do novo mecanismo é mensurado e é público. Acompanhe o benchmark de desempenho neste dashboard público.
-
Uma nova e poderosa linguagem com barras verticais. ES|QL é a nova linguagem com barras verticais da Elastic que transforma, enriquece e simplifica as investigações de dados. Saiba mais sobre os recursos da linguagem ES|QL na documentação.
-
Uma experiência nova e unificada de exploração/investigação de dados que acelera a resolução criando agregações e visualizações em uma tela, proporcionando um fluxo de trabalho ininterrupto.
Por que investimos tempo e esforço na ES|QL?
Nossos usuários precisam de ferramentas ágeis que não apenas apresentem dados, mas também ofereçam métodos eficientes para entendê-los, bem como a capacidade de agir com base em insights em tempo real e no processamento dos dados após a ingestão.
O compromisso da Elastic em melhorar a experiência de exploração dos dados dos usuários nos levou a investir na ES|QL. Ela foi projetada para ser acessível para os iniciantes e poderosa para os especialistas. Com a interface intuitiva da ES|QL, os usuários podem começar rapidamente e mergulhar profundamente em seus dados sem curvas de aprendizado acentuadas. O preenchimento automático e a documentação no app garantem que a criação de consultas avançadas se torne um fluxo de trabalho simples.
Além disso, a ES|QL não mostra apenas números: ela dá vida a eles. As visualizações contextuais alimentadas pelo mecanismo de sugestões do Lens se adaptam automaticamente à natureza das suas consultas, fornecendo uma visão clara dos seus insights.
Além disso, uma integração direta às funcionalidades de dashboards e alertas reflete nossa visão de uma experiência coesa e completa.
Na essência, nosso investimento na ES|QL foi uma resposta direta às crescentes necessidades da nossa comunidade: um passo em direção a um fluxo de trabalho mais interconectado, criterioso e eficiente.
Analisando mais a fundo os casos de uso de segurança e observabilidade
Nosso compromisso com a ES|QL também decorre de um profundo entendimento dos desafios enfrentados por nossos usuários (por exemplo, engenheiros de confiabilidade do site (SREs), DevOps e caçadores de ameaças).
Para os SREs, a observabilidade é essencial. Cada segundo de inatividade ou falha pode ter um efeito cascata na experiência do usuário e, consequentemente, nos resultados financeiros. Um exemplo disso é o recurso de alerta da ES|QL: com sua ênfase em destacar tendências significativas em vez de incidentes isolados, os SREs podem identificar e resolver proativamente ineficiências ou falhas do sistema. Isso reduz o ruído e garante que eles reajam a ameaças genuínas à estabilidade do sistema, tornando a resposta mais oportuna e eficaz.
As equipes de DevOps estão constantemente em uma corrida contra o tempo, implantando diversas atualizações, patches e novos recursos. Com a nova e poderosa exploração e visualização de dados da ES|QL, eles podem avaliar rapidamente o impacto de cada implantação, monitorar a integridade do sistema e receber feedback em tempo real. Além de melhorar a qualidade das implantações, isso também garante uma correção rápida do curso, se necessário.
Para os caçadores de ameaças, o cenário de segurança está em constante evolução e mudança. Um exemplo de como a ES|QL os capacita nesse cenário é o recurso ENRICH. Esse recurso permite que eles pesquisem dados em diferentes conjuntos de dados, revelando padrões ou anomalias ocultos que podem indicar uma ameaça à segurança. Além disso, com as visualizações contextuais, eles não apenas veem dados brutos, mas também obtêm insights práticos, apresentados visualmente. Isso reduz drasticamente o tempo necessário para discernir possíveis ameaças, garantindo reações mais rápidas às vulnerabilidades.
Seja você um SRE tentando decifrar um pico na carga do servidor, um profissional de DevOps avaliando o impacto da versão mais recente ou um caçador de ameaças investigando uma possível violação, a ES|QL complementa o usuário, em vez de complicar a jornada.
As próximas seções do post do blog ajudarão você a começar a usar a ES|QL e mostrarão alguns exemplos tangíveis de como ele é poderoso para explorar seus dados.
Como começar a usar a ES|QL no Kibana
Para começar a usar a ES|QL, navegue até Discover e selecione Try ES|QL (Experimentar a ES|QL) no seletor de visualização de dados. Ela é intuitiva e fácil de usar.
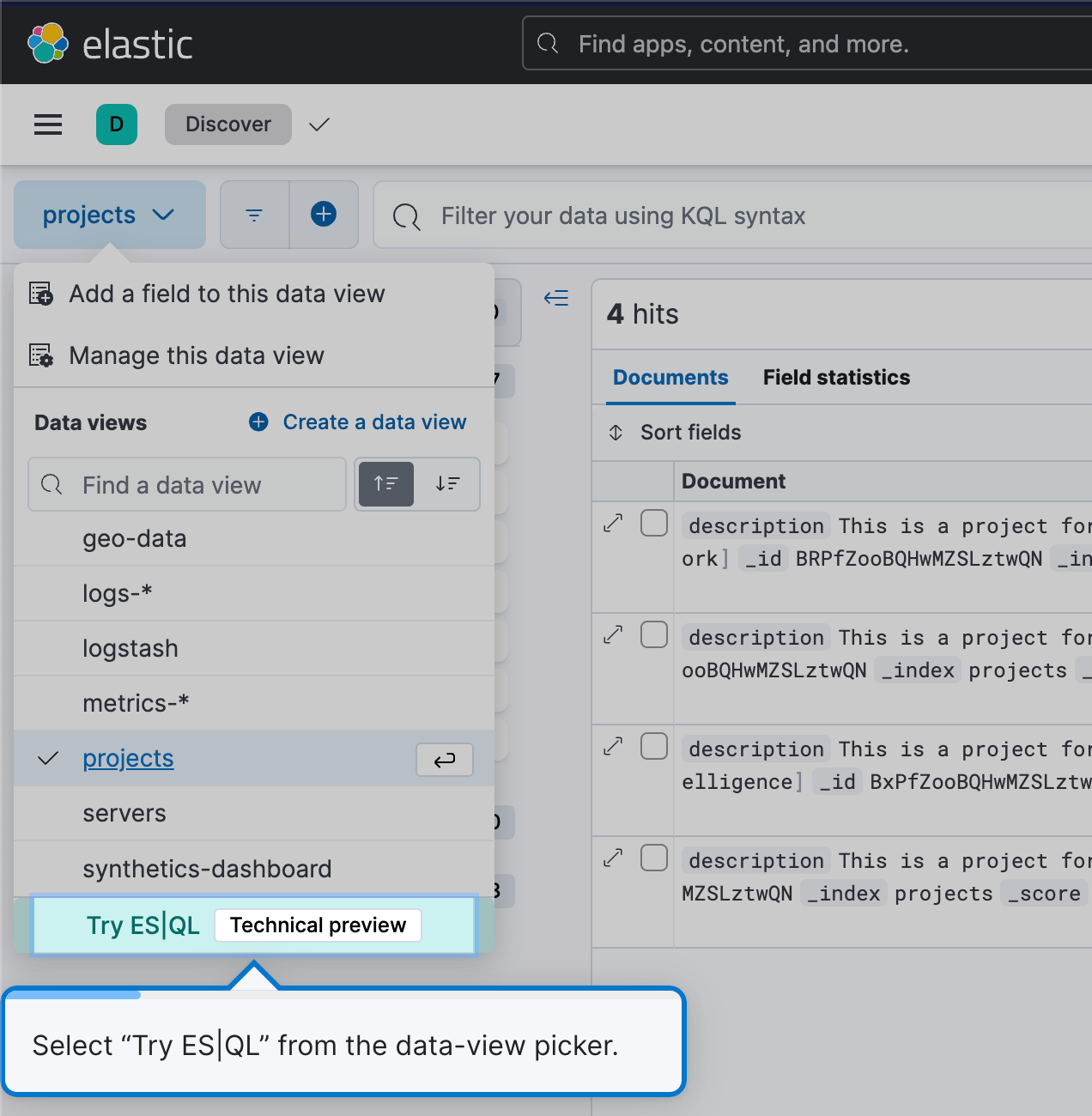
Isso colocará você no modo ES|QL no Discover.
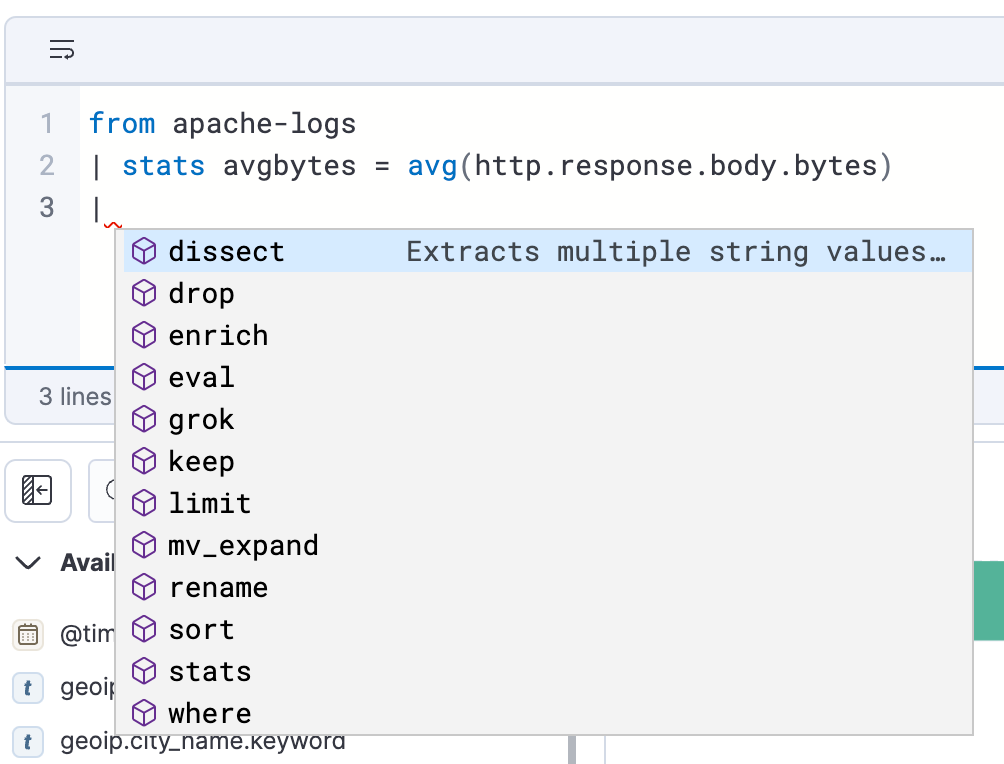
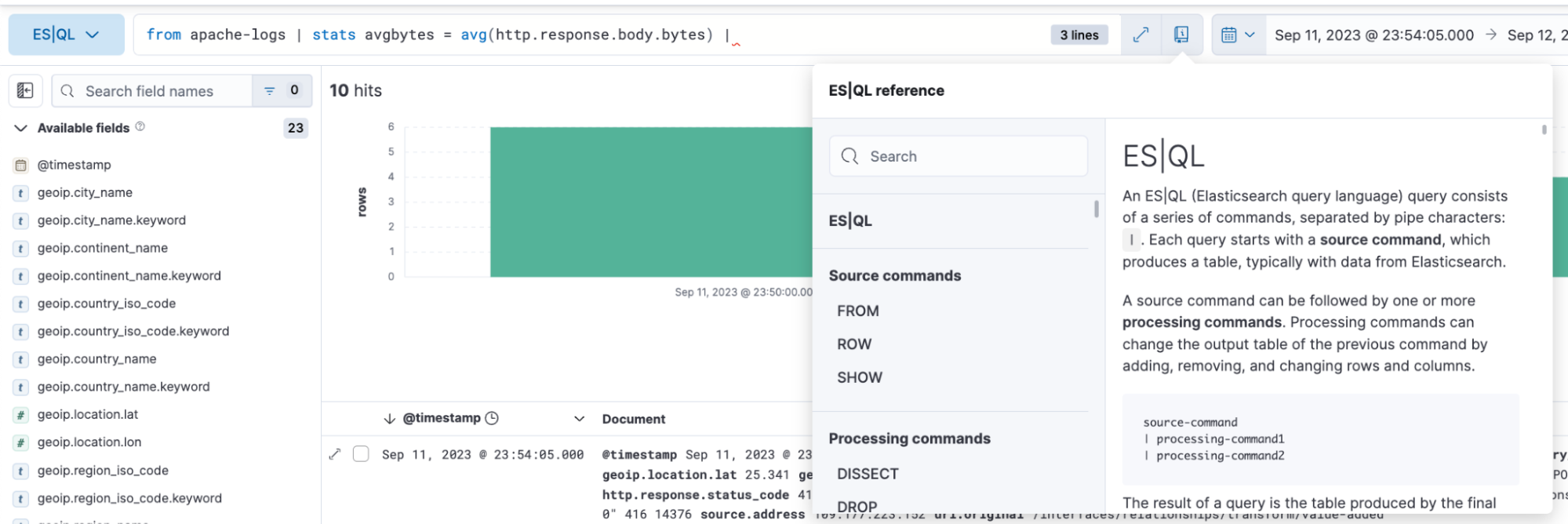
Criação de consultas fácil e eficiente
A ES|QL no Discover oferece preenchimento automático e documentação no app, facilitando a criação de consultas poderosas diretamente na barra de consulta.
Como analisar e visualizar dados com ES|QL
Com a ES|QL, você pode fazer uma exploração de dados abrangente e poderosa. Ela permite que você conduza uma exploração de dados ad-hoc no Discover, crie agregações, transforme dados, enriqueça conjuntos de dados e muito mais, diretamente no criador de consultas. Os resultados são apresentados em formato tabular ou como visualizações, dependendo da consulta que você estiver executando.
Abaixo você encontrará exemplos de consultas ES|QL para observabilidade e como os resultados são representados em formato tabular e como representação visual.
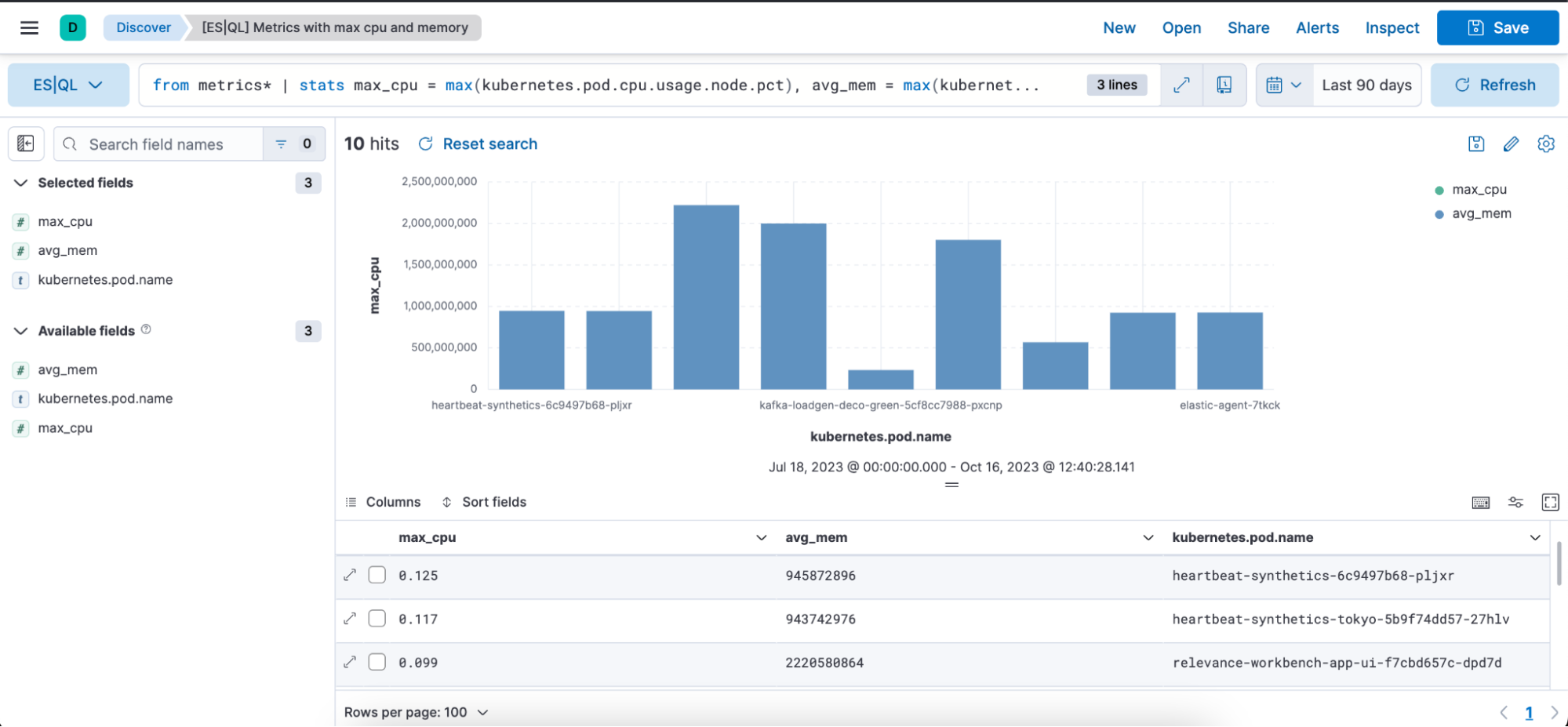
Consulta ES|QL com caso de uso de métricas.
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10A consulta acima mostra como você pode utilizar os seguintes comandos de origem, funções de agregação e comandos de processamento:
Comando de origem from (documentação)
from metrics*: inicia uma consulta a partir de padrões de indexação que correspondam ao padrão “metrics*”. O asterisco(*) atua como um curinga, o que significa que selecionará dados de todos os padrões de indexação cujos nomes comecem com “metrics”.
Agregações stats…by (documentação), max (documentação) e by (documentação)
Esse segmento agrega os dados com base em estatísticas específicas. Ele se divide da seguinte forma:
max_cpu=max(kubernetes.pd.cpu.usage.node.pct): para cada “kubernetes.pod.name” distinto, ele encontra a porcentagem máxima de uso da CPU e armazena esse valor em uma nova coluna chamada “max_cpu”.
max_mem = max(kubernettes.pod.memory.usage.bytes): para cada “kubernetes.pod.name” distinto, ele encontra o uso máximo de memória em bytes e armazena esse valor em uma nova coluna chamada “avg_mem”.
Comandos de processamento (documentação)
- sort (documentação)
- limit (documentação)
sort max_cpu desc: classifica as linhas de dados resultantes pela coluna “max_cpu” em ordem decrescente. Isso significa que a linha com o valor mais alto de “max_cpu” estará no topo.
limit 10: isso limita a saída às 10 primeiras linhas após a classificação.
Em resumo, a consulta:
- Agrupa dados de todos os índices de métricas usando um padrão de indexação
- Agrega os dados para encontrar a porcentagem máxima de uso de CPU e o uso máximo de memória para cada pod distinto do Kubernetes
- Classifica os dados agregados pelo uso máximo da CPU em ordem decrescente
- Exibe apenas as 10 primeiras linhas com maior uso de CPU
Visualizações contextuais. Ao escrever consultas ES|QL no Discover, você receberá representações visuais alimentadas pelo mecanismo de sugestões do Lens. A natureza da sua consulta determina o tipo de visualização recebido, seja uma métrica, um mapa de calor de histograma etc.
Veja abaixo uma representação visual na forma de um gráfico de barras e uma representação de tabela da consulta acima com colunas max_cpu, avg_mem e kubernetes.pod.name:
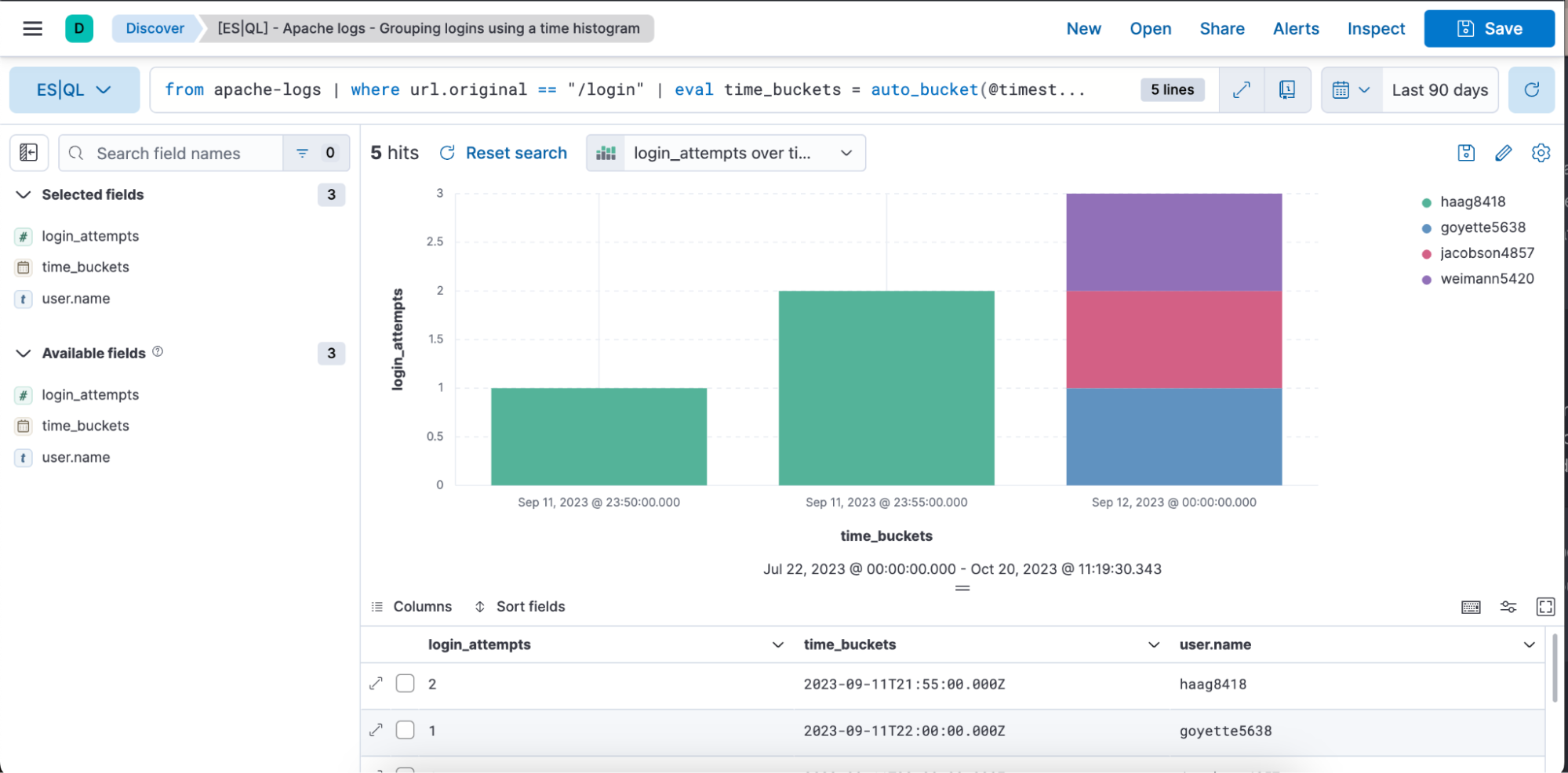
Exemplo de consulta ES|QL com Observability e caso de uso de dados de série temporal:
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts descA consulta acima mostra como você pode utilizar os seguintes comandos de origem, funções de agregação, comandos de processamento e funções:
Comando de origem from (documentação)
from apache-logs: inicia uma consulta a partir de um índice denominado “apache-logs”. Esse índice contém entradas de log relacionadas ao tráfego do servidor web Apache.
where (documentação)
where url.original==”/login”: filtra os registros apenas para aqueles em que o campo “url.original” é igual a “/login”. Isso significa que só estamos interessados em entradas de log referentes a tentativas de login ou acessos à página de login.
eval (documentação) e auto_bucket (documentação)
eval time_buckets =... : cria uma nova coluna chamada “time_buckets”.
A função “auto_bucket” cria buckets intuitivos e retorna um valor de data e hora para cada linha que corresponde ao bucket resultante em que a linha se enquadra.
“@timestamp” é o campo que contém o carimbo de data/hora de cada entrada de log.
“50” é o número de buckets.
“2023-09-11T21:54:05.000Z”: hora de início dos buckets
“2023-09-12T00:40:35.000Z”: hora de término dos buckets
Isso significa que as entradas de log de “2023-09-11T21:54:05.000Z” a “2023-09-12T00:40:35.000Z” serão divididas em 50 intervalos igualmente espaçados, e cada entrada será associada a um intervalo específico com base em seu carimbo de data/hora.
O objetivo não é fornecer exatamente o número desejado de buckets, mas sim escolher um intervalo com o qual você se sinta confortável e que forneça no máximo o número desejado de buckets. Se você pedir mais buckets, auto_bucket poderá escolher um intervalo menor.
Agregações de stats…by (documentação), count (documentação) e by (documentação)
stats login_attempts = count(user.name) by time_buckets, user.name: agrega os dados para calcular o número de tentativas de login. Isso é feito contando as ocorrências de “user.name” (representando usuários únicos que tentam fazer login).
A contagem é agrupada por “time_buckets” (os intervalos de tempo que criamos) e “user.name”. Isso significa que, para cada bucket de tempo, veremos quantas vezes cada usuário tentou fazer login.
sort (documentação)
Sort login_attempts desc: por fim, os resultados agregados são classificados pela coluna “login_attempts” em ordem decrescente. Isso significa que o resultado mostrará o maior número de tentativas de login na parte superior.
Em resumo, a consulta:
- Seleciona dados do índice “apache-logs”
- Filtra entradas de log relacionadas à página de login
- Agrupa essas entradas em intervalos de tempo específicos
- Conta o número de tentativas de login de cada usuário em cada um desses intervalos de tempo
- Exibe primeiro os resultados classificados pelo maior número de tentativas de login
Veja abaixo uma representação visual na forma de um gráfico de barras e uma representação de tabela da consulta acima com colunas login_attempts, time_buckets e user.name.
Edição de visualização em linha no Discover e no dashboard
Edite visualizações de ES|QL diretamente no Discover e nos dashboards. Não há necessidade de navegar até o Lens para edições rápidas; você pode fazer as alterações ali mesmo.
Veja abaixo um vídeo de um fluxo de trabalho completo ou leia o guia passo a passo:
Como escrever uma consulta ES|QL
Como obter uma visualização contextual com base na natureza da consulta
Editar a visualização em linha
Salvá-la em um dashboard
Editar a visualização em um dashboard
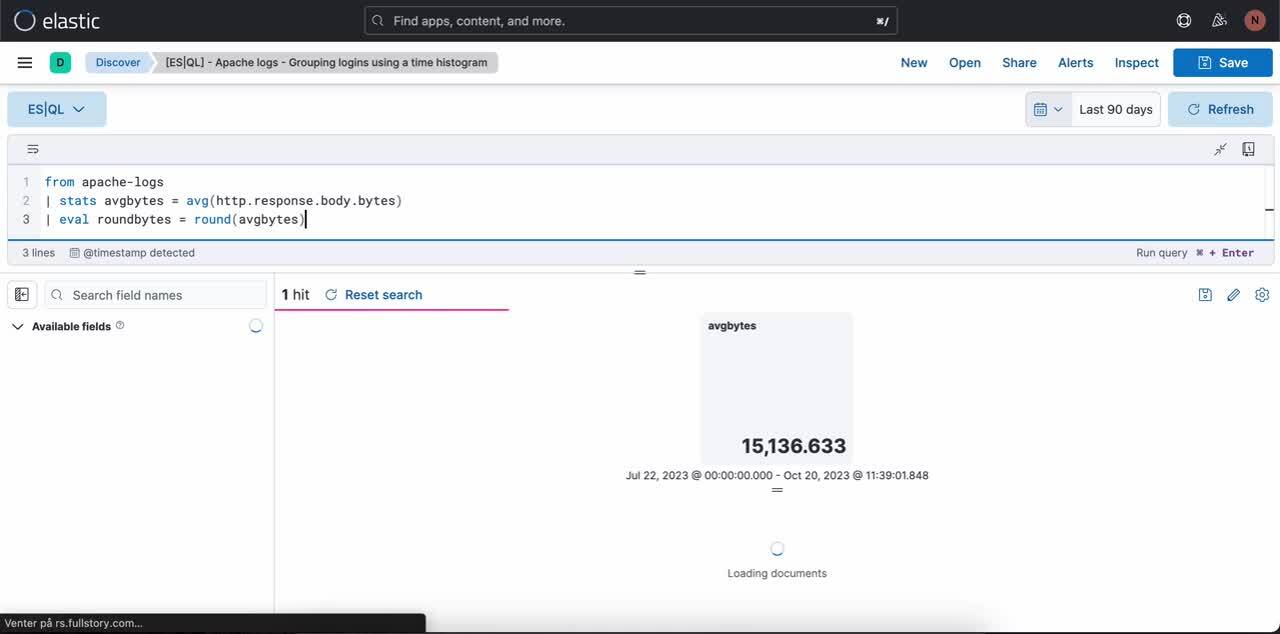
Etapa 1. Como escrever uma consulta ES|QL. Exemplo de consulta que produz uma visualização de métrica:
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
| drop avgbytesEtapa 2. Como obter uma visualização contextual (neste caso, uma visualização de métrica) com base na natureza da consulta. Você pode então selecionar o ícone de lápis para entrar no modo de edição em linha.
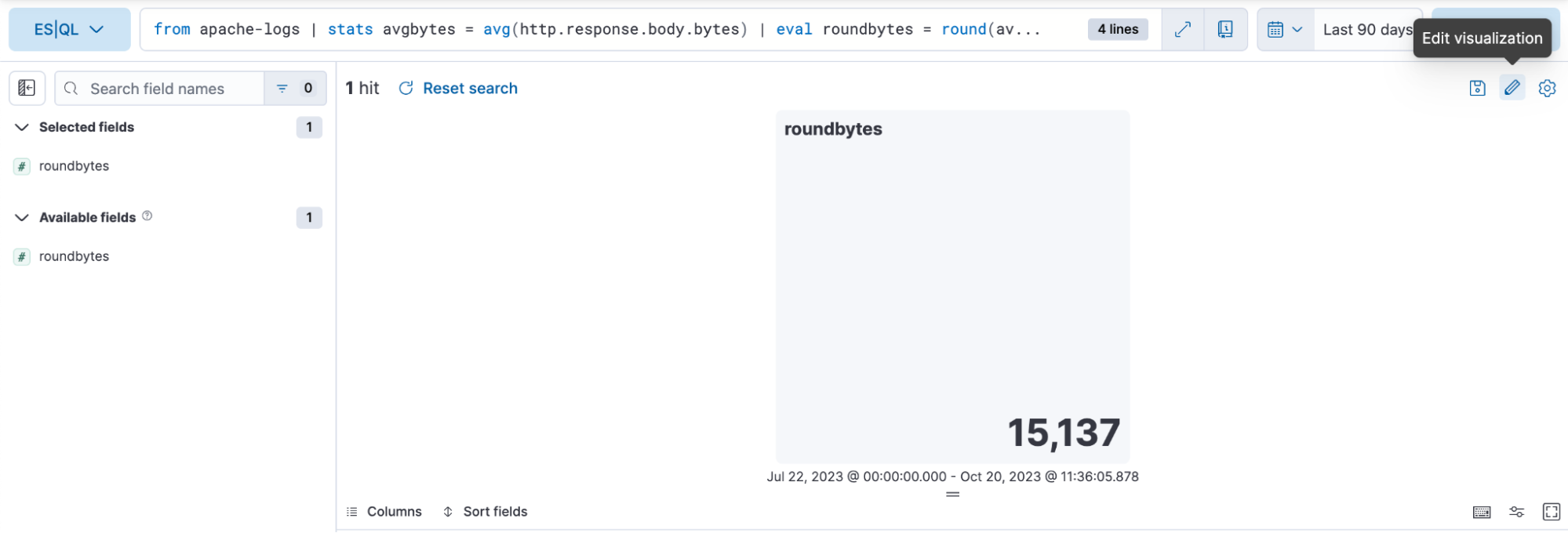
Etapa 3. Como editar a visualização usando o modo de edição em linha
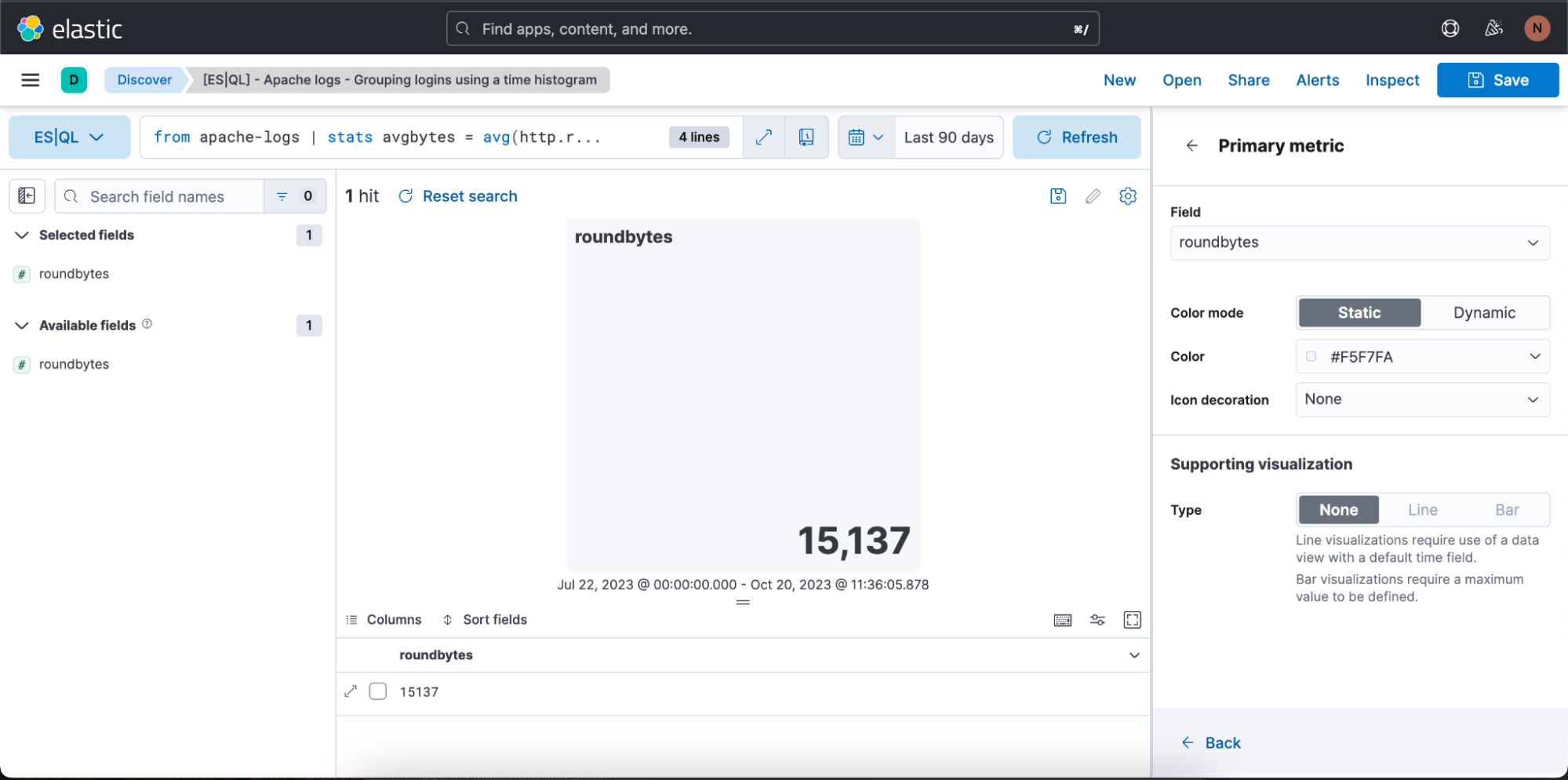
No caso acima, queremos que a visualização esteja no modo de cores dinâmicas, então mudamos para “Dynamic” (Dinâmico).
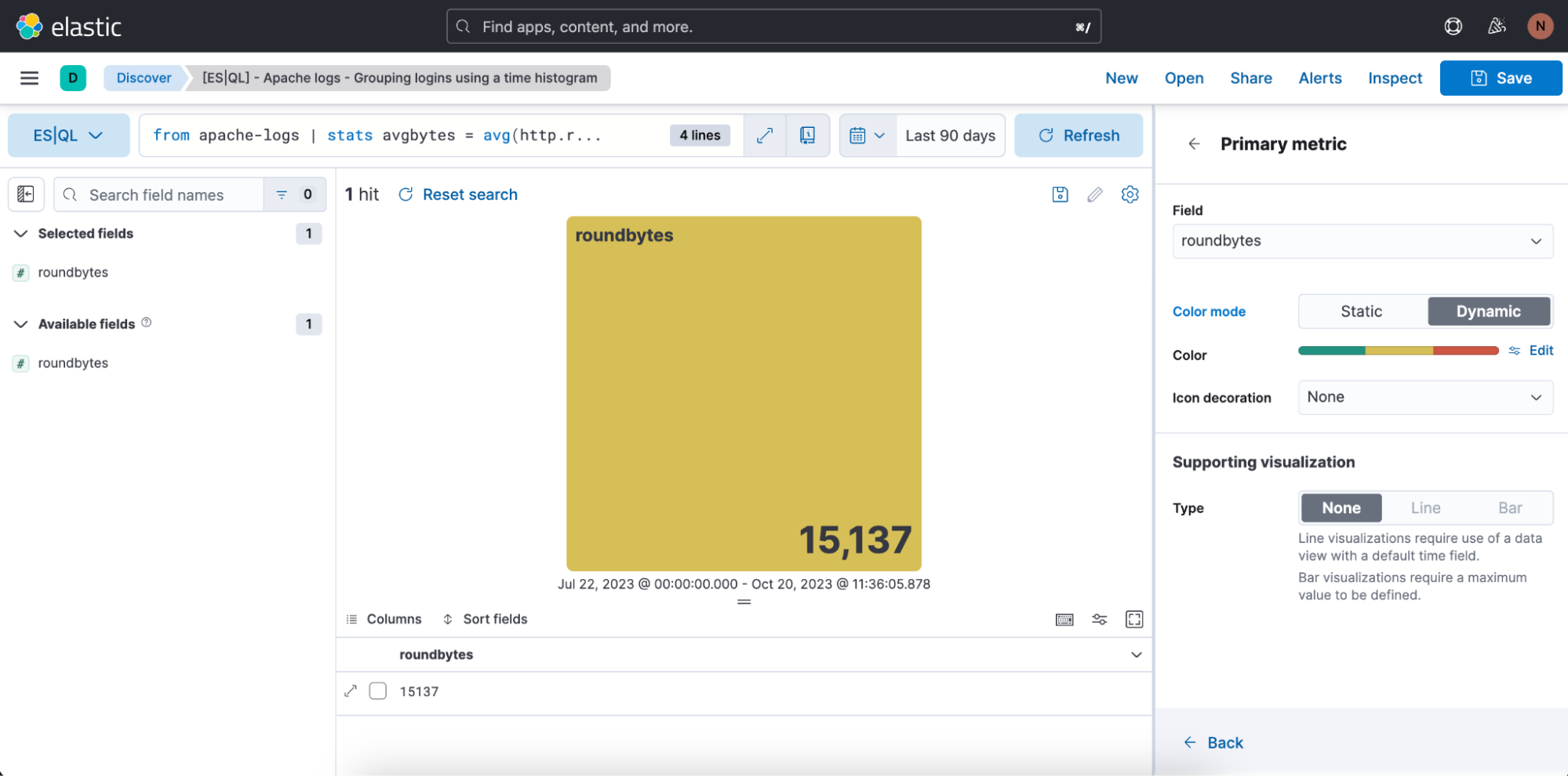
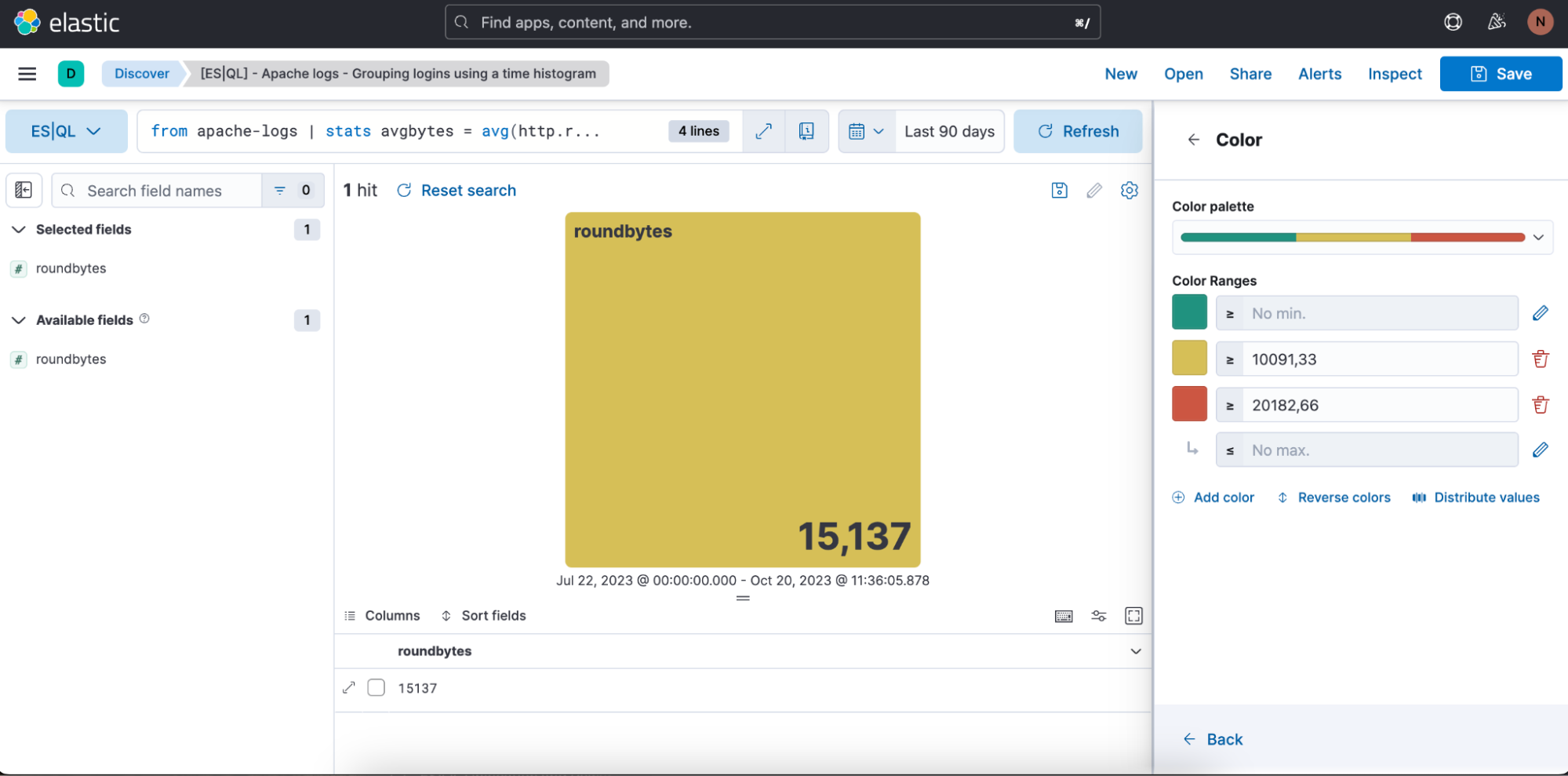
Também temos a oportunidade de definir as gamas de cores que queremos usar:
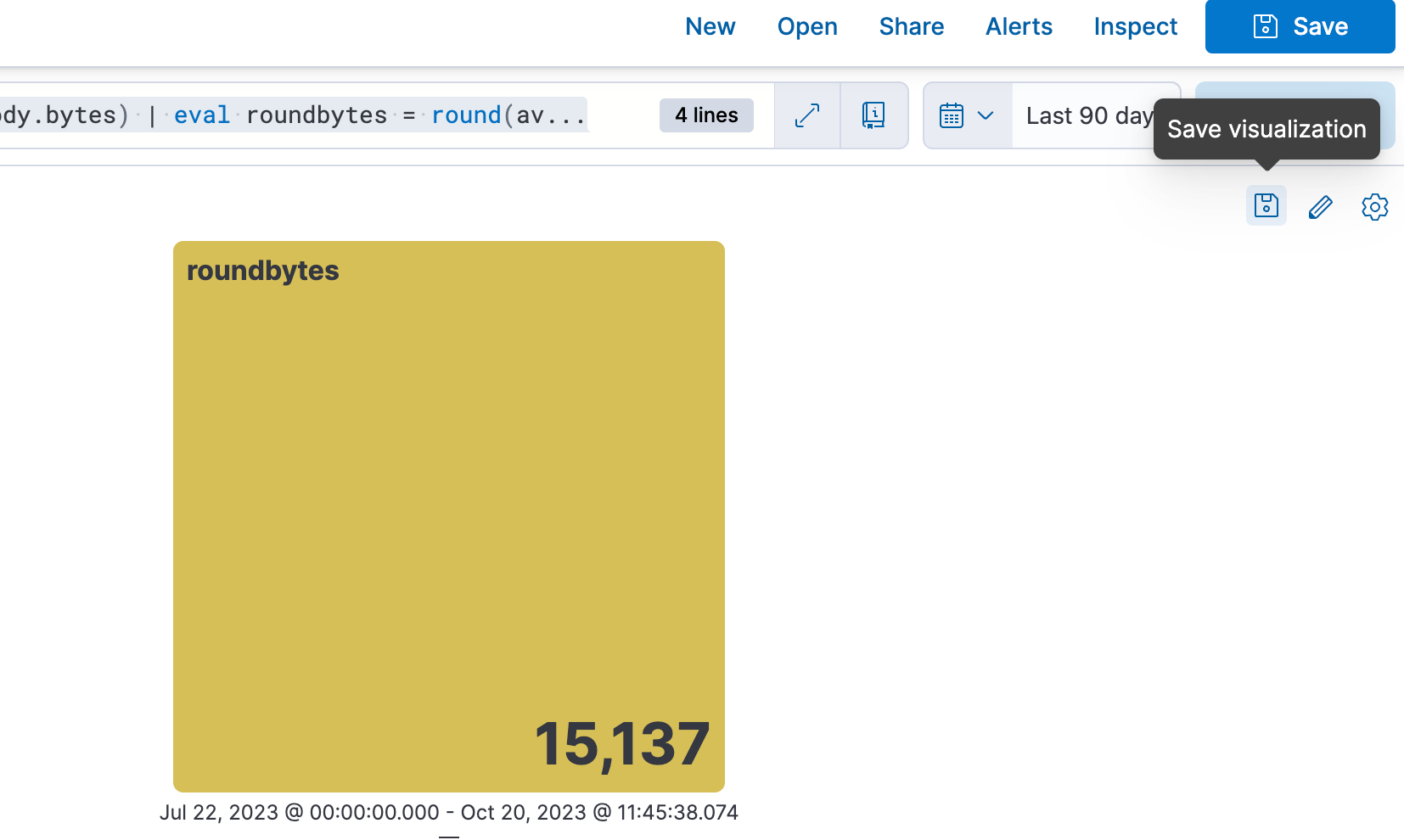
Etapa 4. Como salvar em um dashboard
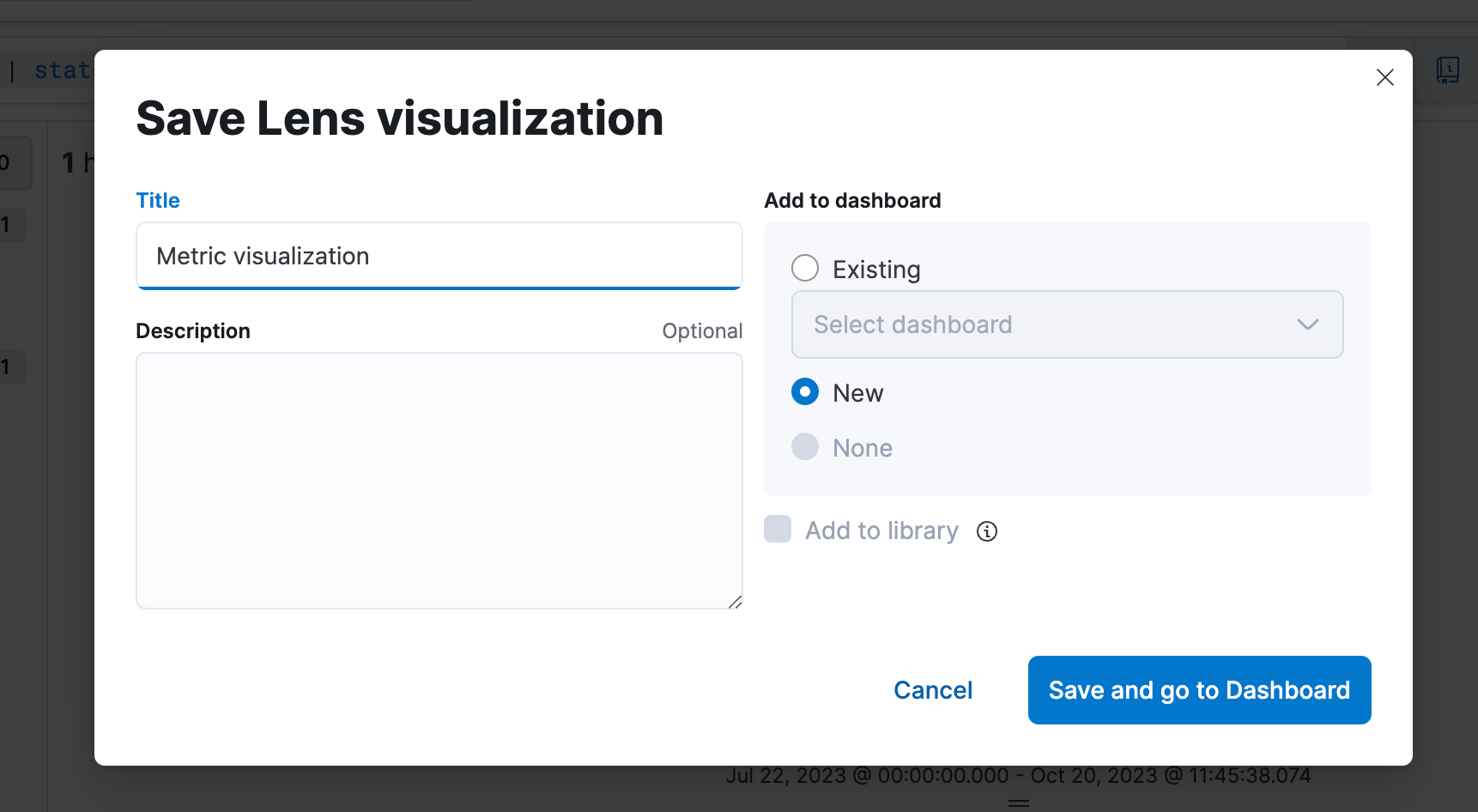
Etapa 5. Como editar a visualização em um dashboard
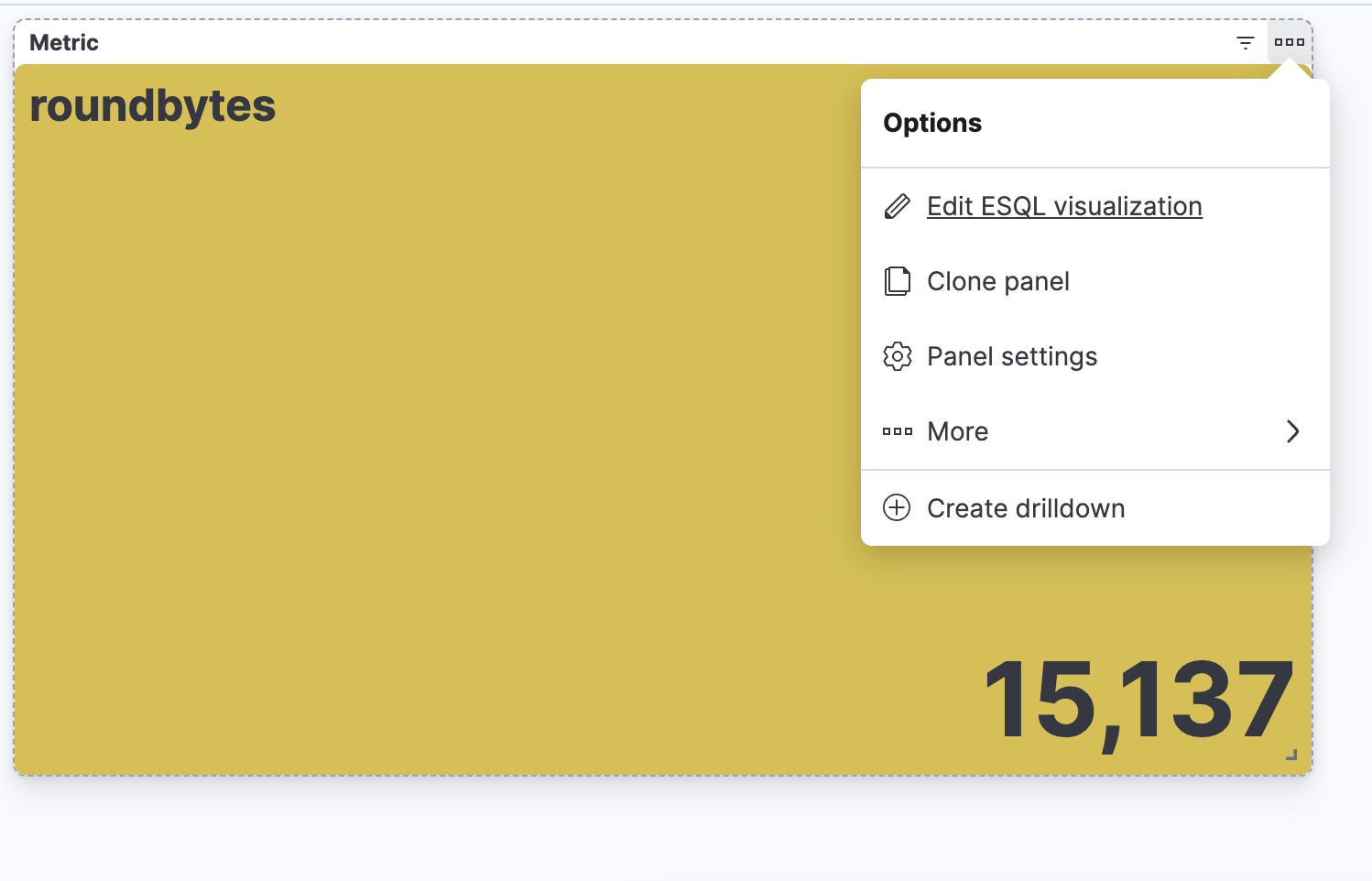
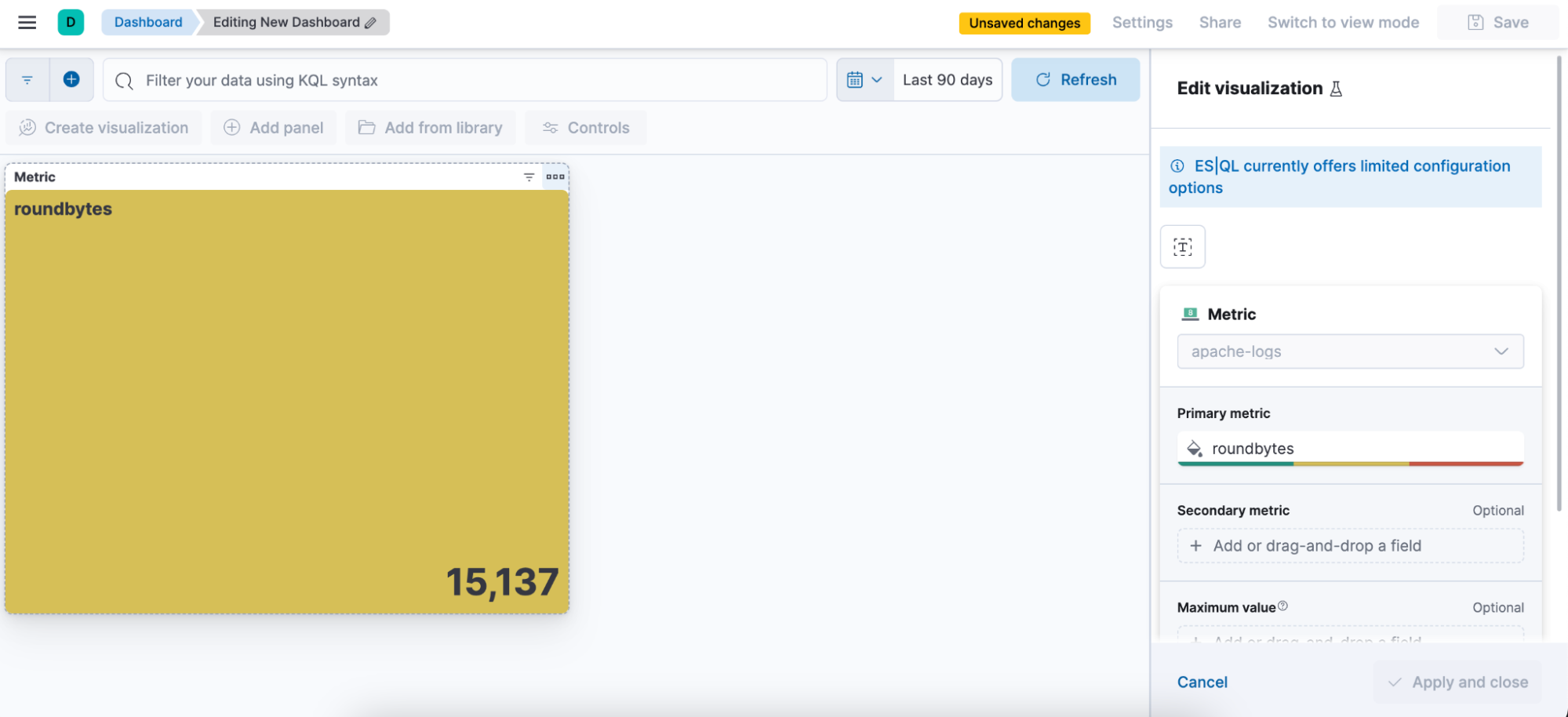
Como criar um alerta de ES|QL diretamente do Discover
Você pode utilizar a ES|QL para alertas de observabilidade e segurança, definindo valores agregados como limites. Aumente a precisão da detecção e receba notificações práticas, enfatizando tendências significativas em vez de incidentes isolados e reduzindo falsos positivos.
A seguir, veremos como criar um tipo de regra de alerta de ES|QL no Discover.
O novo tipo de regra de alerta está disponível no tipo de regra existente do Elasticsearch. Esse tipo de regra traz todas as novas funcionalidades disponíveis na ES|QL e proporciona novos casos de uso de alerta.
Com o novo tipo, os usuários poderão gerar um único alerta com base em uma consulta ES|QL definida e ver uma prévia do resultado da consulta antes de salvar a regra. Quando a consulta retornar um resultado vazio, nenhum alerta será gerado.
Exemplo de consulta para um alerta:
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10
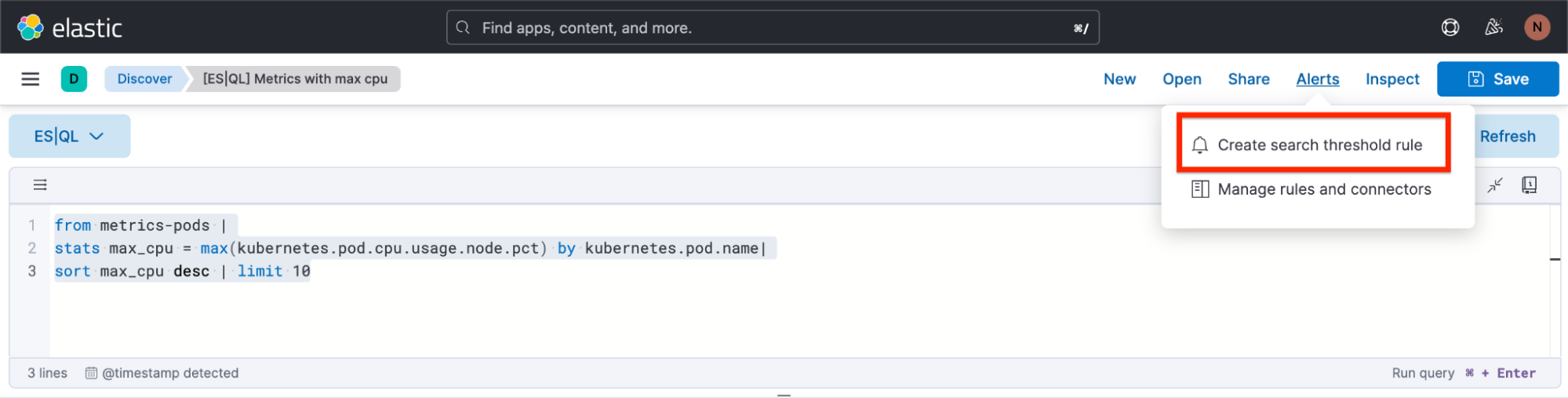
Como criar um alerta do Discover
Etapa 1. Clique em “Alerts” (Alertas) e depois em “Create search threshold rule” (Criar regra de limite de busca). Você pode começar a criar seu tipo de regra de alerta de ES|QL antes ou depois de definir sua consulta ES|QL na barra de consulta. A vantagem de fazer isso depois de defini-la é que a consulta é colada automaticamente no menu desdobrável “Create Alert” (Criar alerta).
Etapa 2. Comece a definir seu tipo de regra de alerta de ES|QL
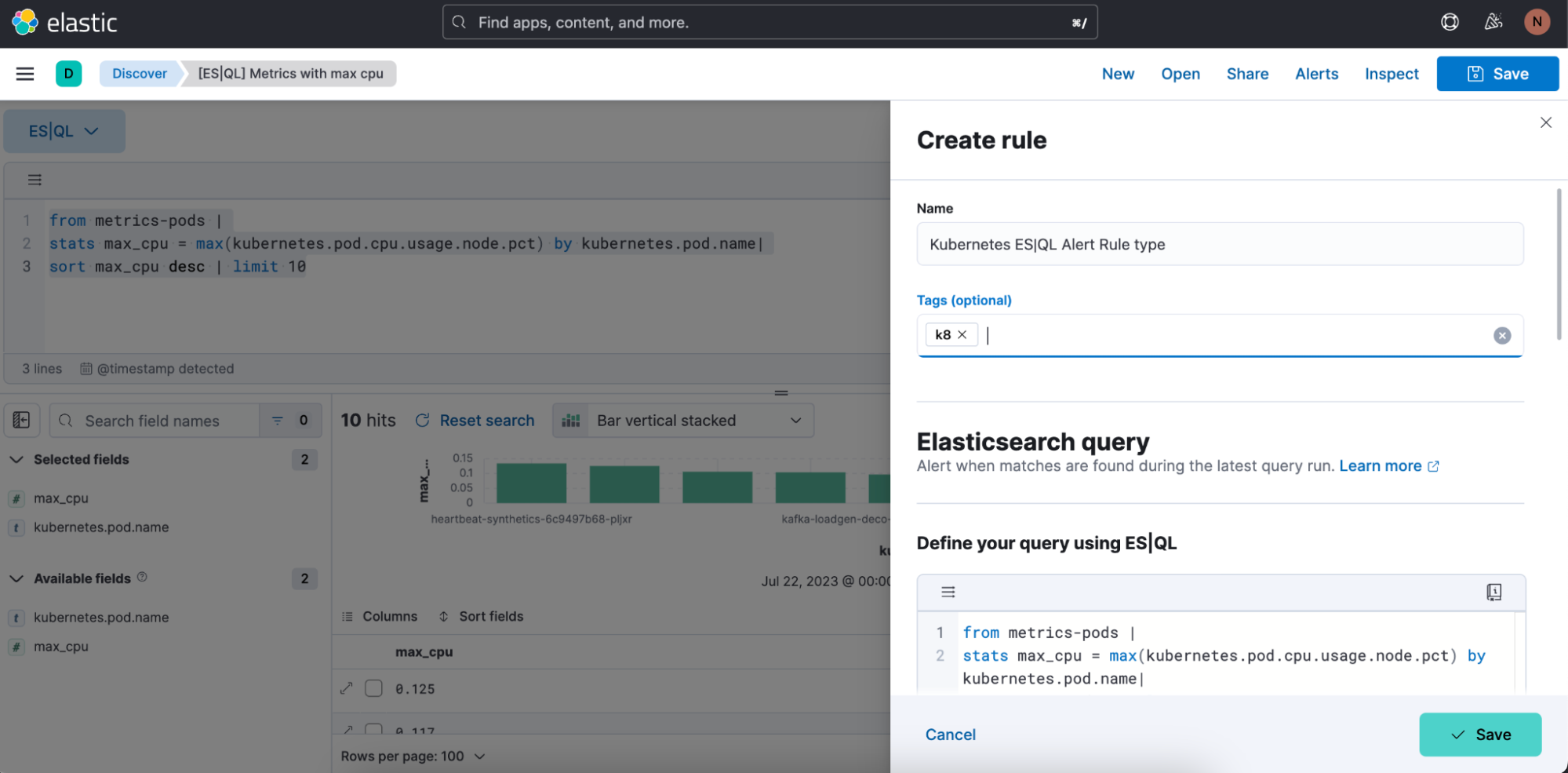
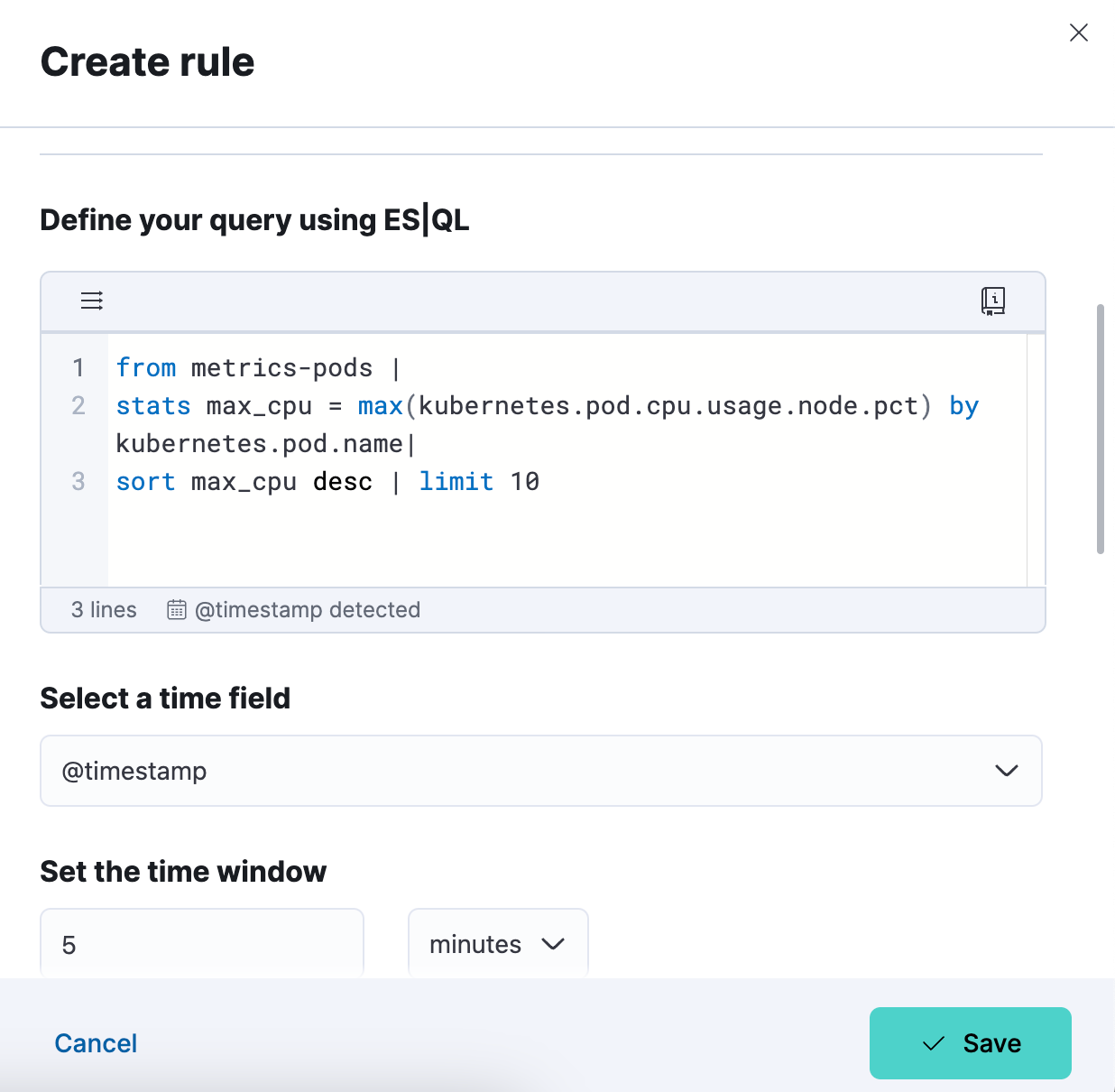
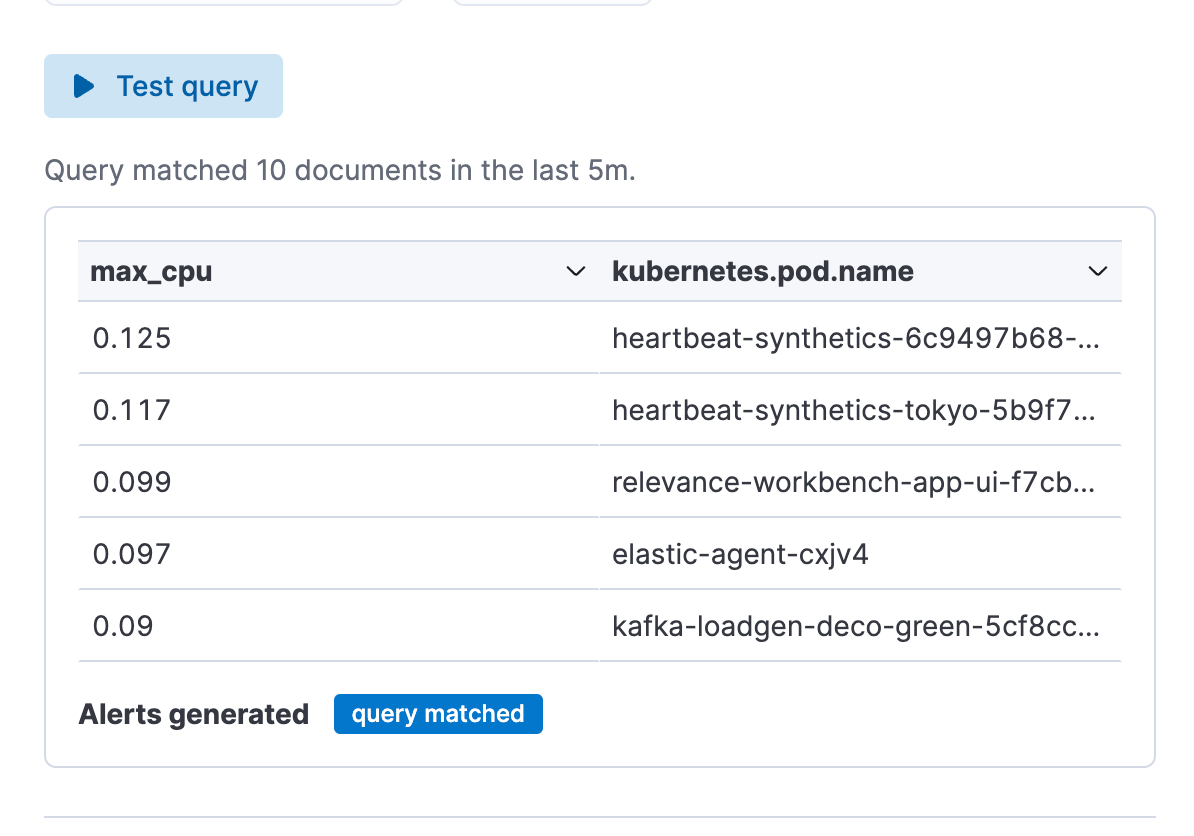
Etapa 3. Teste sua consulta de tipo de regra de alerta. Você pode iterar a consulta ES|QL colada e testá-la clicando em “Test query” (Testar consulta). Isso lhe dará uma prévia dos resultados em uma tabela.
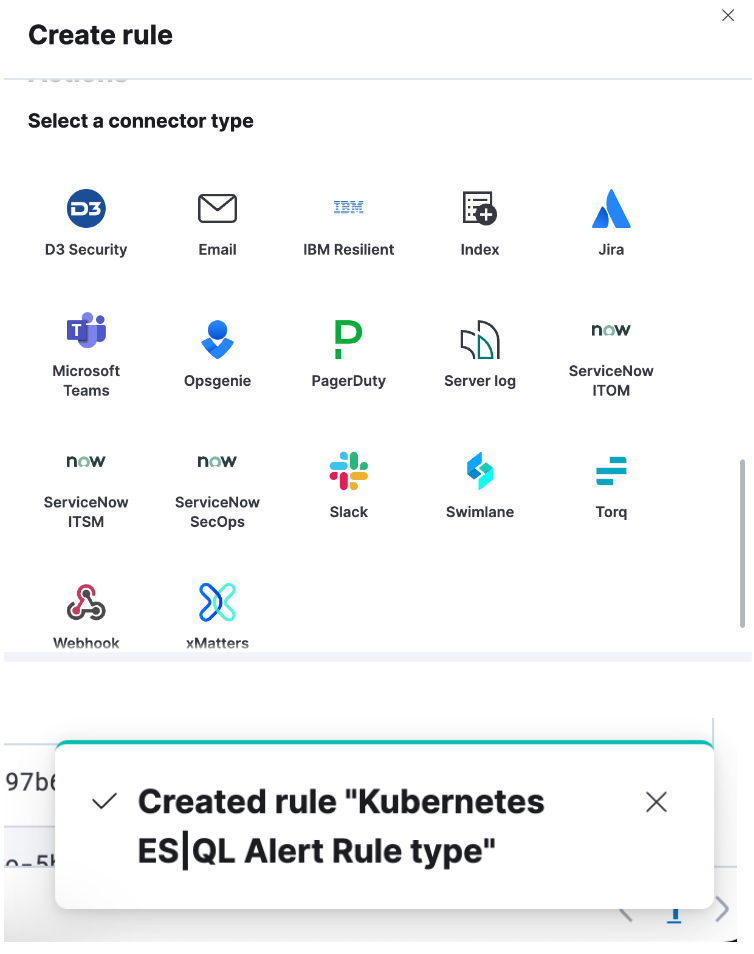
Etapa 4. Configure seu conector e salve. Pronto! Você criou um tipo de regra de alerta de ES|QL!
Enriqueça seu conjunto de dados de consulta com campos de outro conjunto de dados
Você pode usar o comando enrich (documentação) para aprimorar seu conjunto de dados de consulta com campos de outro conjunto de dados, completo com sugestões no contexto para a política selecionada (ou seja, sugerindo o campo correspondente e as colunas enriquecidas).
Exemplo de consulta usando ENRICH, na qual uma política de enriquecimento “servers-to-project” está sendo utilizada por meio da consulta para enriquecer o conjunto de dados com o nome, server_hostname, e o custo:
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc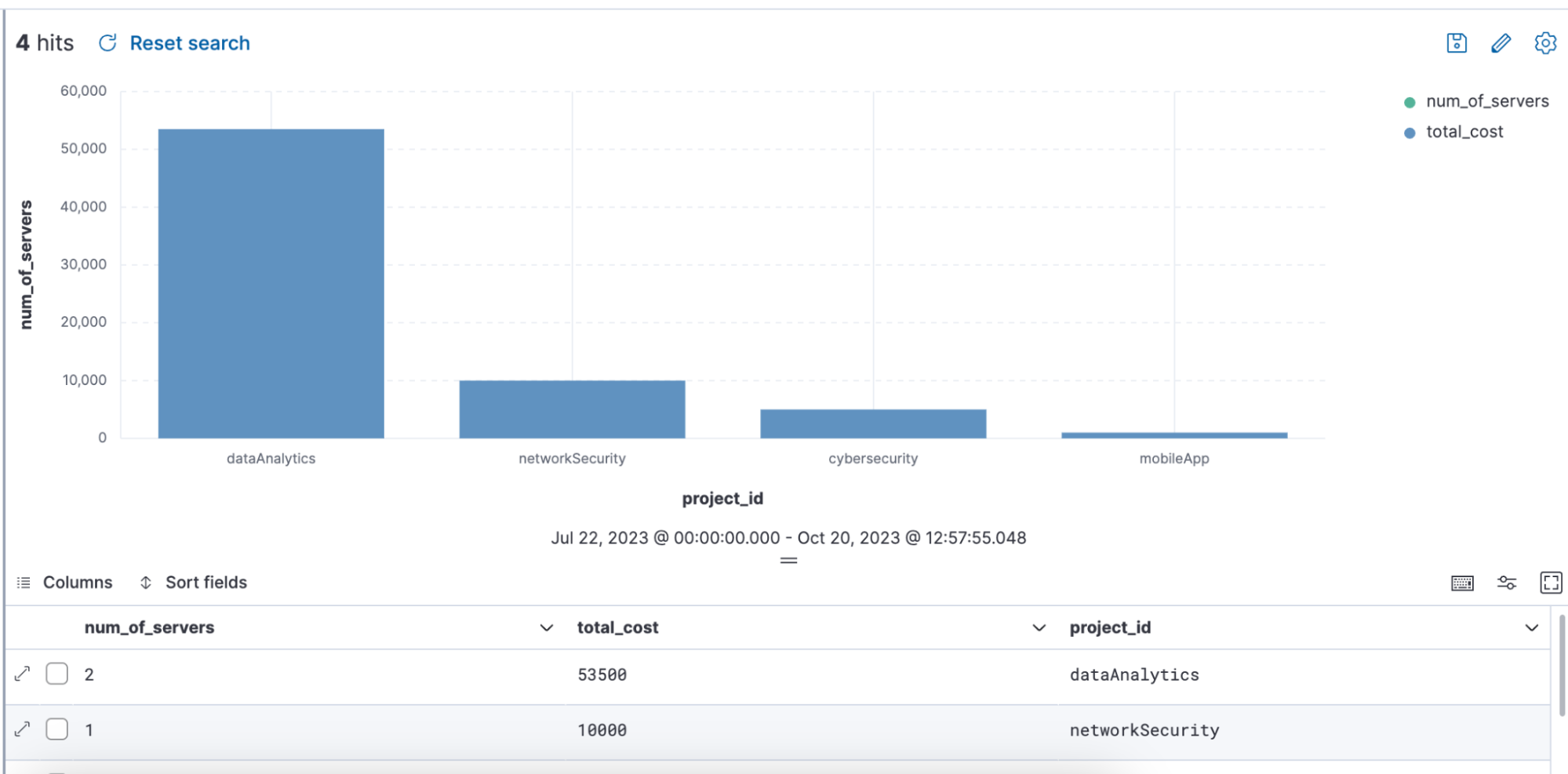
Também tornamos mais fácil criar políticas de enriquecimento adicionando uma visão geral e um assistente para criar políticas de enriquecimento.
Para ter uma visão geral das políticas de enriquecimento, navegue até Stack Management (Gerenciamento da stack) ⇒ Index Management (Gerenciamento de índice) e lá você verá uma guia chamada Enrich Policies (Políticas de enriquecimento):
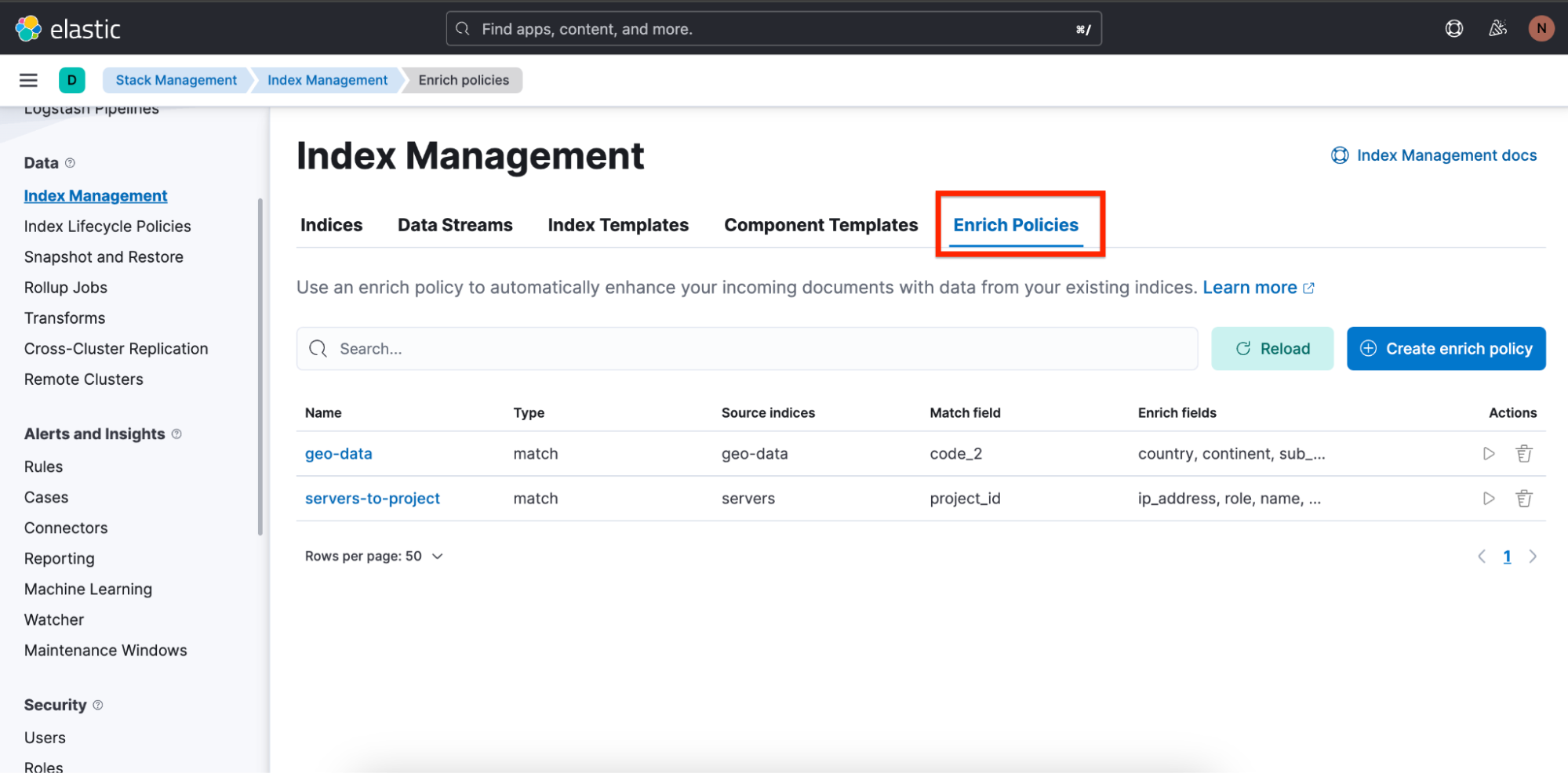
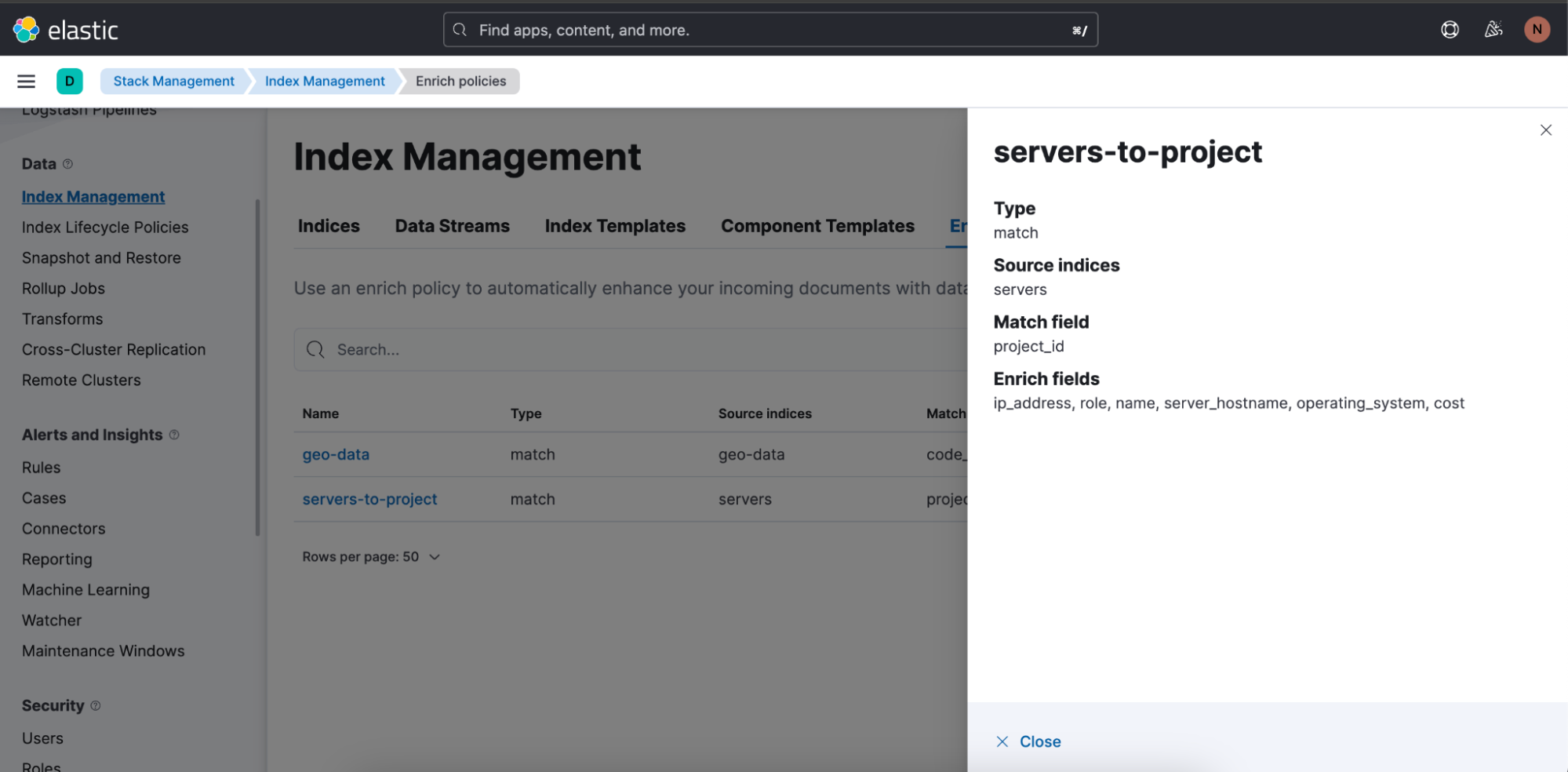
Aqui está a política de enriquecimento usada na consulta acima: “servers-to-project”:
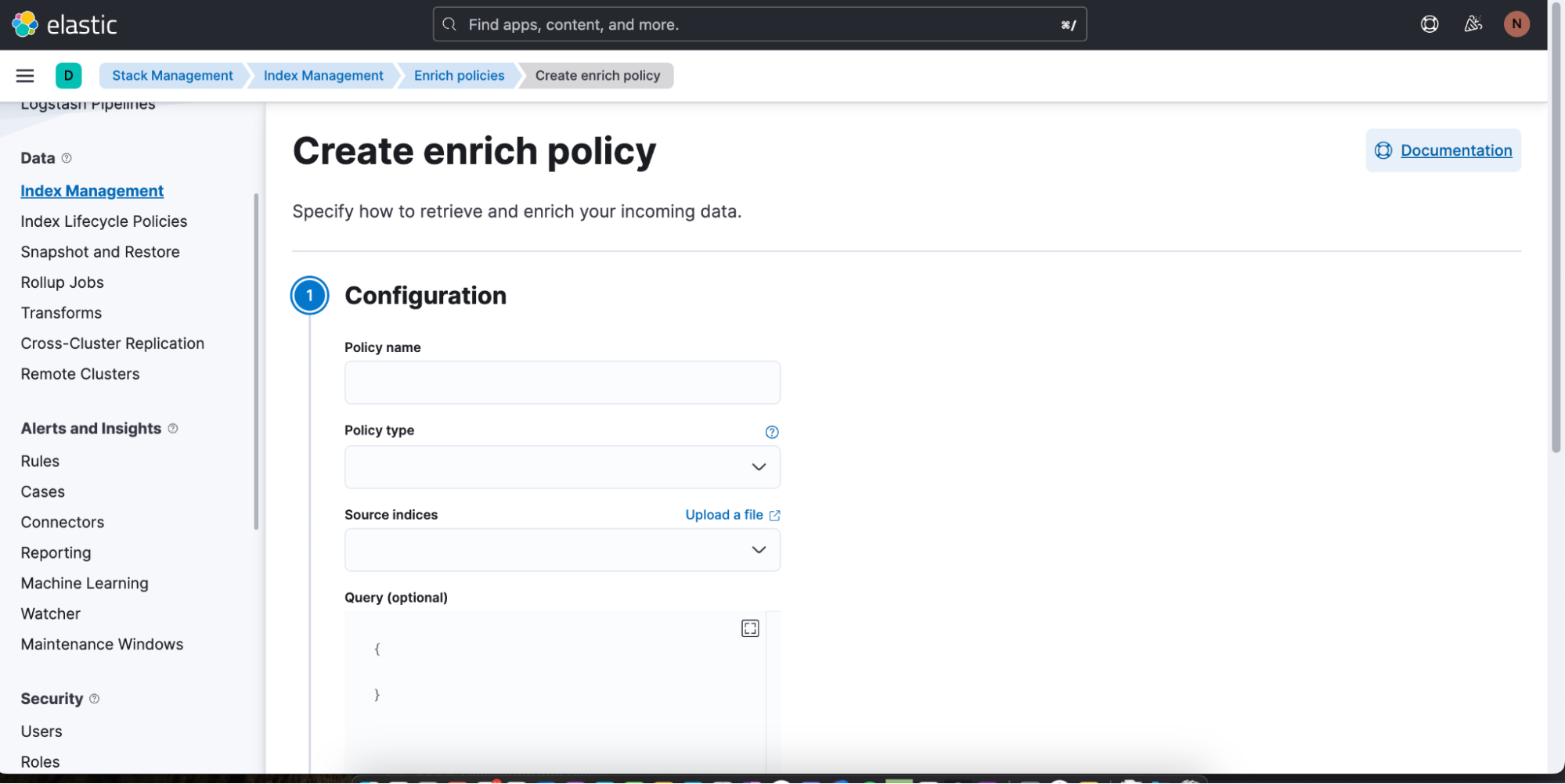
Você pode começar a criar facilmente uma nova política de enriquecimento clicando em Create enrich policy (Criar política de enriquecimento). Após a criação e a execução, a política poderá ser usada em uma consulta ES|QL no Discover.
Aprimorando a exploração de dados: o poder e a promessa da ES|QL
A ES|QL é a inovação mais recente da Elastic para avançar na análise e na exploração de dados. Não se trata apenas de mostrar dados; trata-se de torná-los compreensíveis, práticos e visualmente atraentes. Alimentada por um mecanismo de consulta rápido, distribuído e dedicado, projetada como uma nova linguagem com barras verticais e envolta em uma experiência unificada de exploração de dados, a ES|QL atende aos desafios de usuários como engenheiros de confiabilidade do site, DevOps, caçadores de ameaças e outros tipos de analistas.
A ES|QL capacita os SREs a lidar com ineficiências do sistema de maneira eficaz, ajuda os DevOps a garantir implantações de qualidade e fornece aos caçadores de ameaças ferramentas para discernir rapidamente possíveis ameaças à segurança. Sua integração direta com dashboards, a edição de visualização em linha, as funcionalidades de alerta e recursos como comandos de enriquecimento proporcionam um fluxo de trabalho contínuo e eficiente. A interface da ES|QL combina recursos avançados e facilidade de uso, permitindo que os usuários se aprofundem em seus dados e tornando sua análise mais simples e esclarecedora. O lançamento da ES|QL é apenas uma continuação da jornada da Elastic para aprimorar as experiências de exploração de dados e atender às necessidades crescentes da nossa comunidade de usuários.
Você pode testar todos os recursos da ES|QL hoje mesmo! Para fazer isso, crie uma conta de avaliação da Elastic ou teste-a em nosso ambiente de demonstração público .
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste post permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir