Como importar dados de CSV e de log para o Elasticsearch com o File Data Visualizer
No Elastic Stack 6.5, introduzimos o novo recurso File Data Visualizer. Ele permite que o usuário envie um arquivo contendo textos delimitados (como CSV), NDJSON ou semiestruturados (como arquivos de log), e o novo endpoint de aprendizado de machine learning da Elastic find_file_structure analisará e informará o que descobriu sobre os dados. Isso inclui um pipeline de ingestão sugerida e mapeamentos que podem ser usados para importar o arquivo para o Elasticsearch a partir da UI.
O objetivo desse recurso é permitir que os usuários que queiram explorar seus dados com o Kibana ou o machine learning consigam colocar pequenas quantidades de dados no Elasticsearch sem ter que aprender os pormenores do processo de ingestão.
Um bom exemplo recente é este post de blog, criado por um membro da equipe de Marketing da Elastic que não tem conhecimento de desenvolvedor. Com o File Data Visualizer, ele conseguiu importar dados de terremotos no Elasticsearch para explorar e analisar locais com terremotos usando as visualizações de geo_point no Kibana.
Exemplo: importar um arquivo CSV para o Elasticsearch
A melhor forma de demonstrar essa função é com um exemplo. O exemplo a seguir usará um arquivo CSV contendo dados imaginários de um site de compra de passagens aéreas. Aqui estamos mostrando somente as cinco primeiras linhas do arquivo para dar uma ideia do que são os dados:
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
Configurar a importação do CSV com o File Data Visualizer
O File Data Visualizer pode ser encontrado no Kibana em Machine Learning > Data Visualizer. O usuário vê uma página que permite que ele selecione ou arraste e solte um arquivo. A partir da versão 6.5, estamos com um limite de tamanho de arquivo de 100 MB.
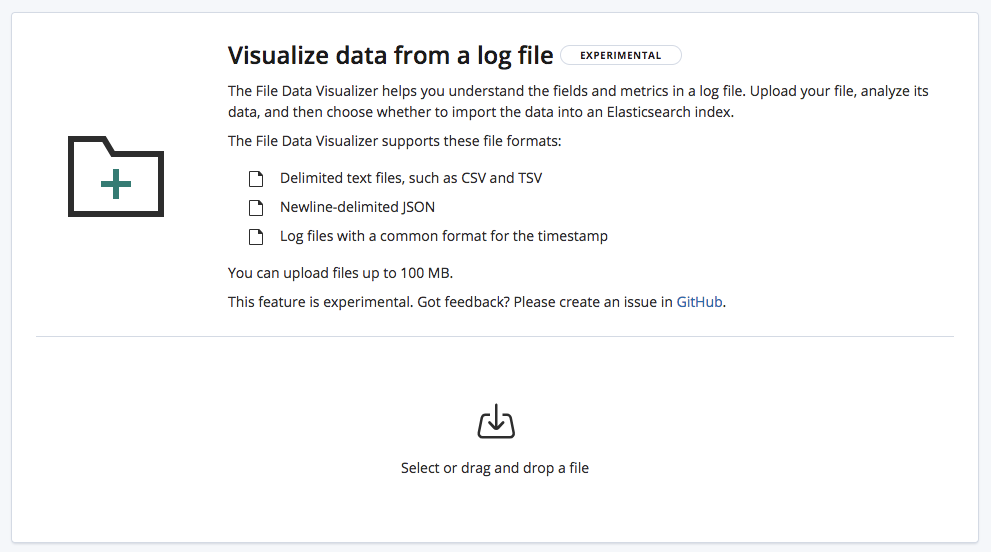
Quando selecionamos o arquivo CSV, a página envia as primeiras 1.000 linhas do arquivo para o endpoint find_file_structure, que executa a sua análise e retorna os resultados. Ao olhar para a seção Summary da UI, podemos ver que foi detectado corretamente que os dados estão em um formato delimitado e que o delimitador é uma vírgula.
O recurso também detectou que existe uma fileira de cabeçalho e usou esse nomes de campos para rotular os dados em cada coluna. A primeira coluna encontrou um formato de data conhecido e por isso está realçada como sendo o Time field.
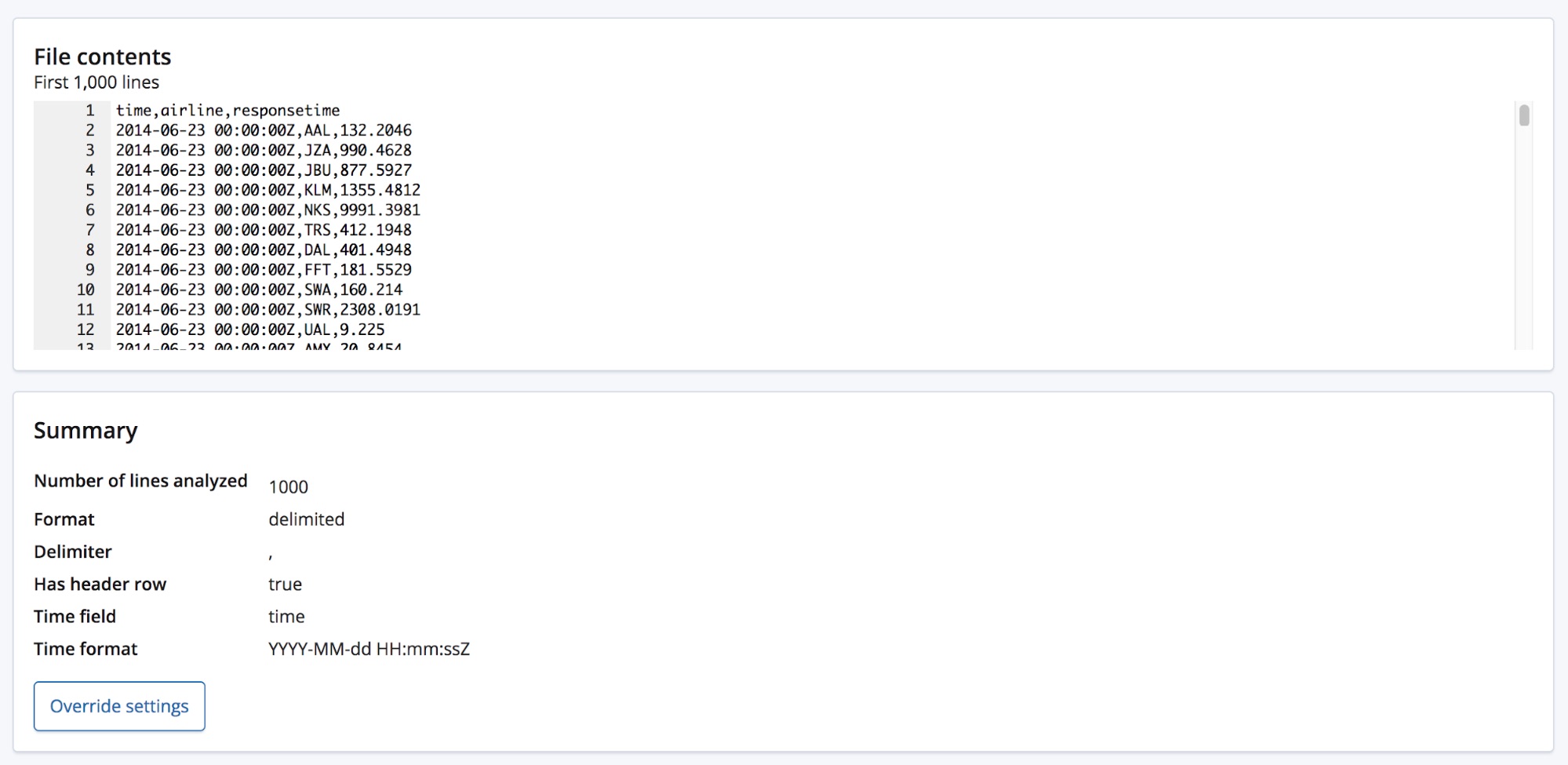
Abaixo da seção Summary fica a seção de campos, que deve ser familiar para quem usava o recurso original do Data Visualizer.
Podemos ver que os tipos dos três campos foram identificados corretamente, com alguma estatística de alto nível listada para cada um. Os 10 valores que mais ocorrem estão listados em cada campo. Para responsetime, que foi identificado como sendo um campo numérico, os valores min, median e max também são exibidos.
Isso funciona bem para um CSV que tenha um cabeçalho, mas e se os dados não contiverem uma fileira de cabeçalho no topo?
Nesse caso, o endpoint find_file_structure usará os nomes do campo temporários. Podemos demonstrar isso ao remover a primeira linha do arquivo de exemplo e enviá-lo de novo. Agora os campos estão com os nomes gerais column1, column2 e column3.
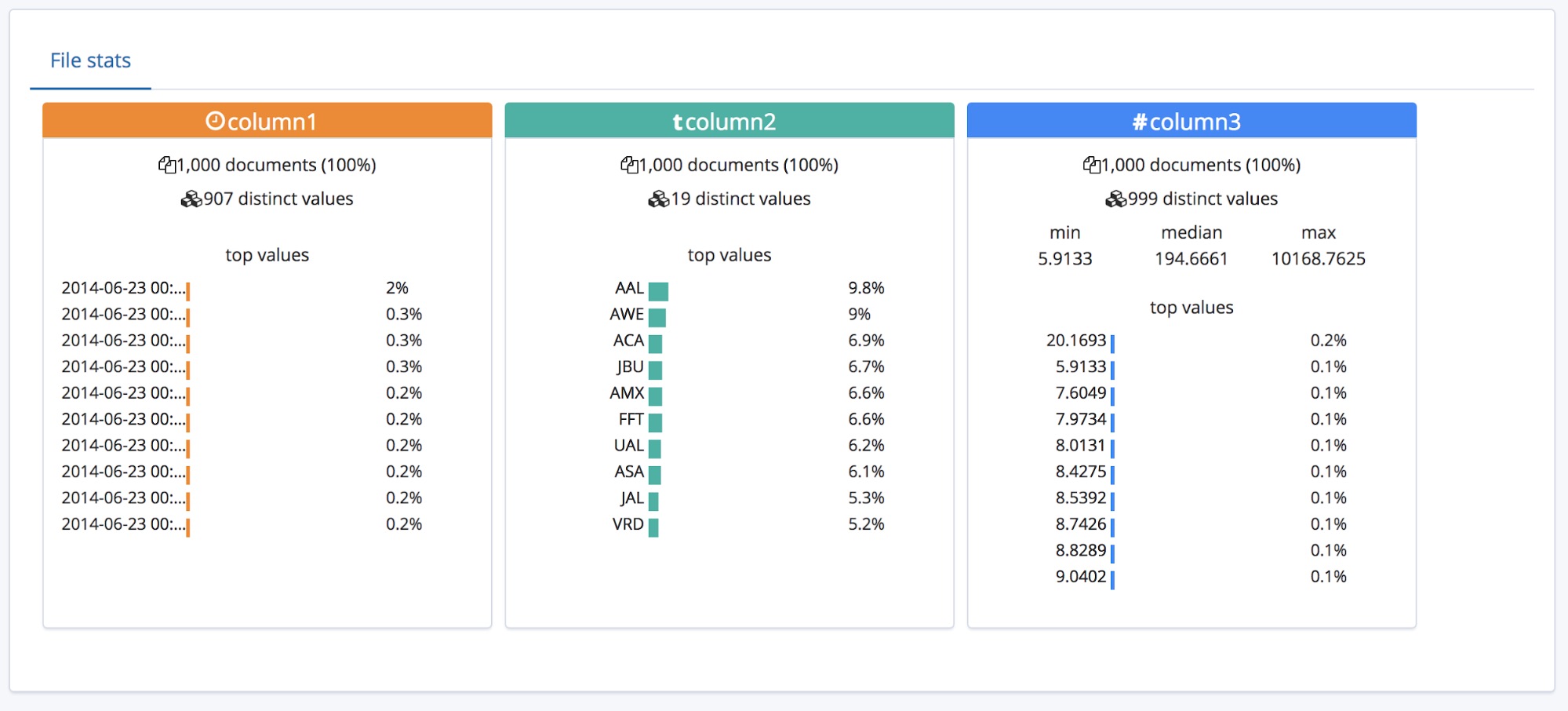
O usuário que tiver algum conhecimento poderá querer renomear esses campos para algo melhor com o botão Override settings.
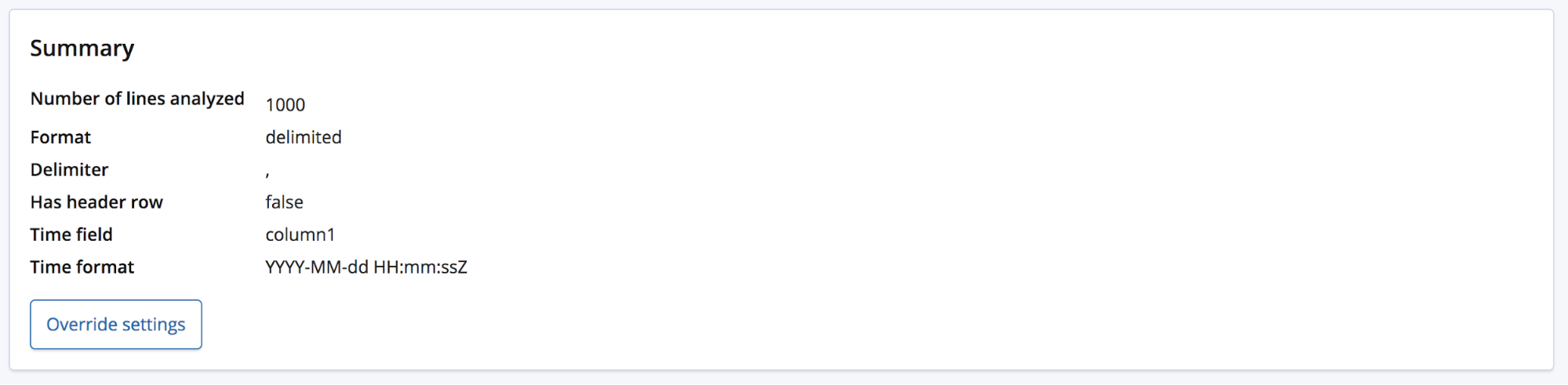
Além de renomear esses campos, o usuário também consegue mexer em outras configurações como Data format, Delimiter e Quote character. Essa seção oferece uma forma de corrigir a suposição do endpoint find_file_structure a respeito dos dados. Você pode ter diversos campos de dados e ter escolhido o primeiro. Ou pode querer alterar completamente os nomes dos campos mesmo que o arquivo contenha uma linha de cabeçalho.
Depois que estiver tudo configurado, podemos usar o botão Import no canto inferior esquerdo da página.
Importar os dados CSV para o Elasticsearch
Isso nos leva para a página de importação onde podemos importar os dados para o Elasticsearch. Observe que esse recurso não foi feito para uso em um processo de produção repetida, mas somente para a exploração inicial dos dados. O principal motivo é a falta de opções de automação, mas o recurso também é experimental ainda.
Existem dois modos de importação. Simples, no qual o usuário só precisa informar um novo nome exclusivo para o índice e escolher se também quer criar um padrão de índice.
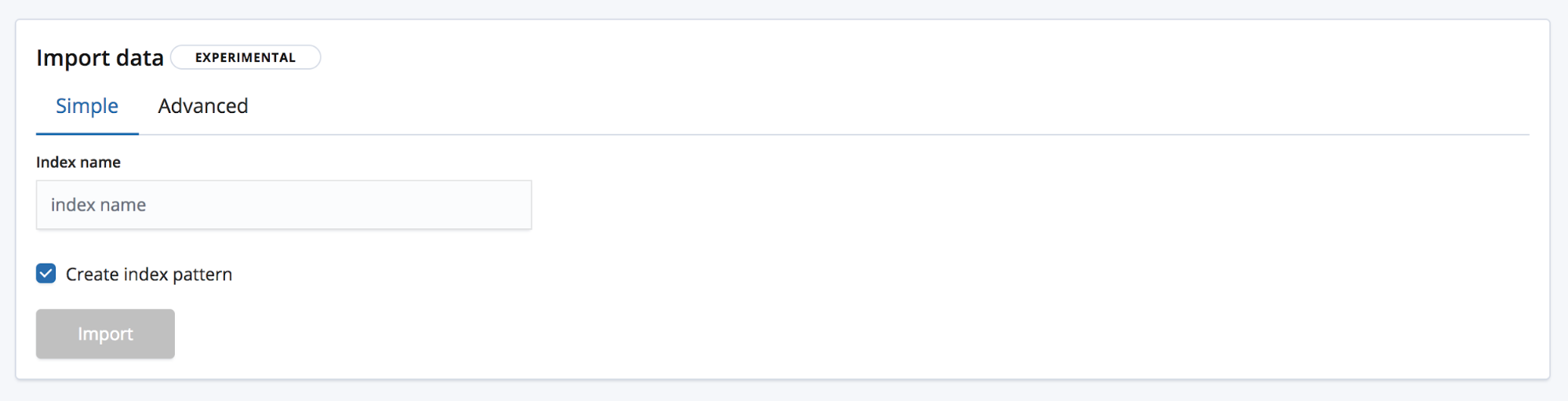
E Advanced, no qual o usuário tem um controle mais granular sobre as configurações que serão usadas para criar o índice.
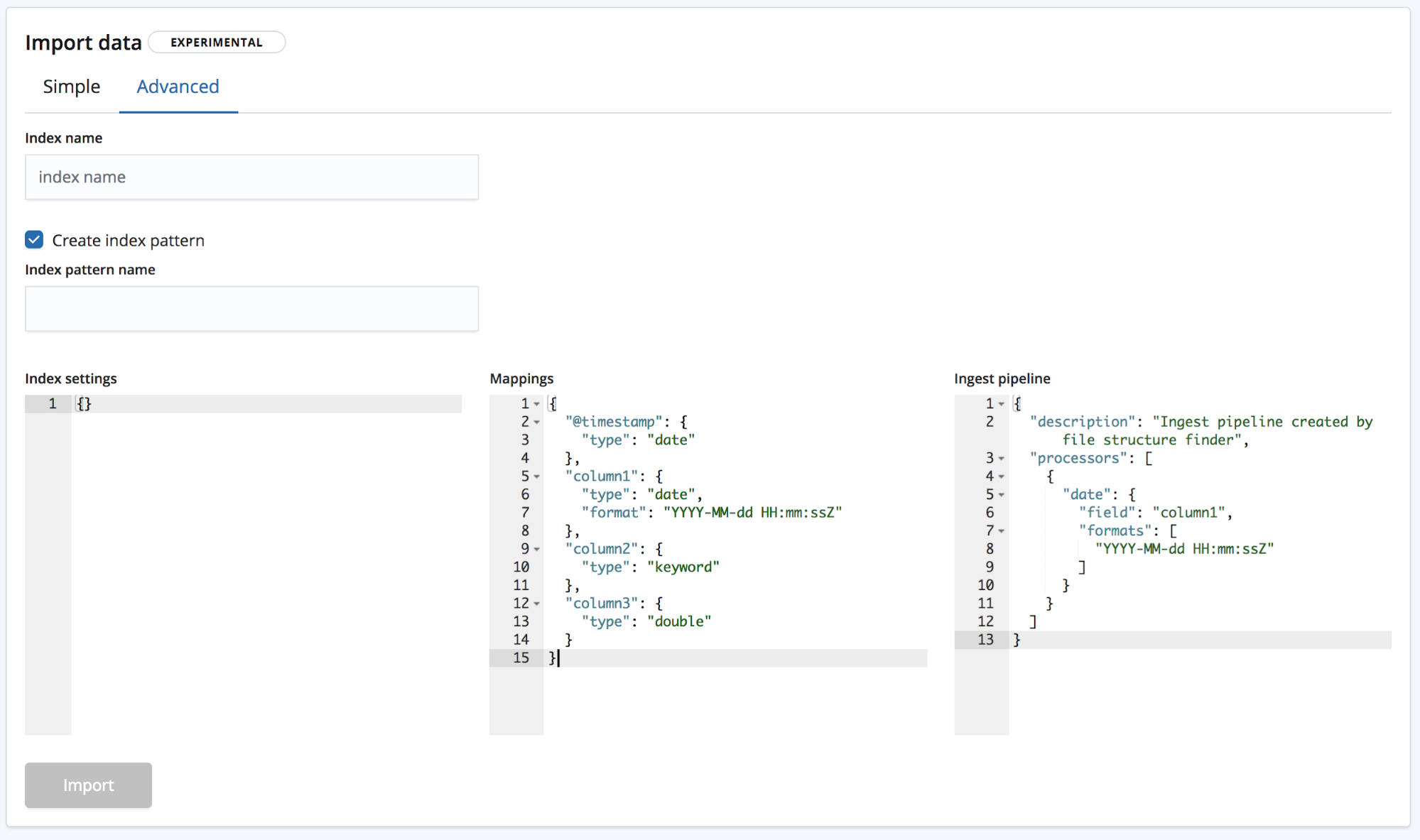
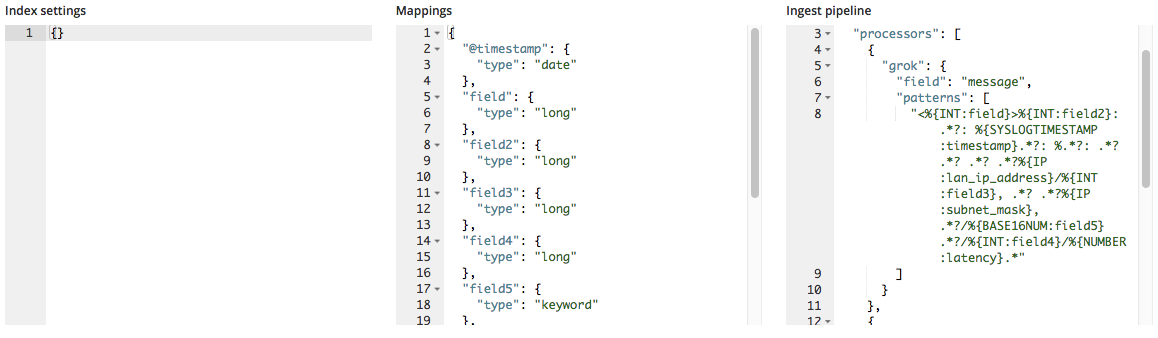
- Index settings — Por padrão, não são necessárias outras configurações para a criação do índice e a importação, mas a opção de personalizar as configurações do índice ainda existe.
- Mapeamentos — O
find_file_structureoferece um objeto de mapeamento baseado nos campos e nos tipos que foram identificados. Para uma lista de mapeamentos possíveis, consulte a documentação de mapeamento do Elasticsearch. - Ingest pipeline — O
find_file_structureoferece um objeto de pipeline de ingestão padrão. Ele será usado no momento da ingestão de dados e pode ser usado para o envio de dados adicionais.
Dentro do 6.5, só permitimos a criação de novos índices e não a adição de dados a um índice existente para reduzir o risco de danificar o índice.
Clicar no botão de importação inicia o processo de importação. Ele consiste em diversas etapas numeradas:
- Processing file — Transformar os dados em documentos NDJSON para que possam ser ingeridos com a API em lote.
- Creating index — Criar o índice usando as configurações e os objetos de mapeamento.
- Creating ingest pipeline — Criar o pipeline de ingestão com o objeto ingest pipeline.
- Uploading the data — Carregar os dados no índice do Elasticsearch.
- Creating index pattern — Criar um padrão de índice do Kibana (se o usuário tiver optado por isso).

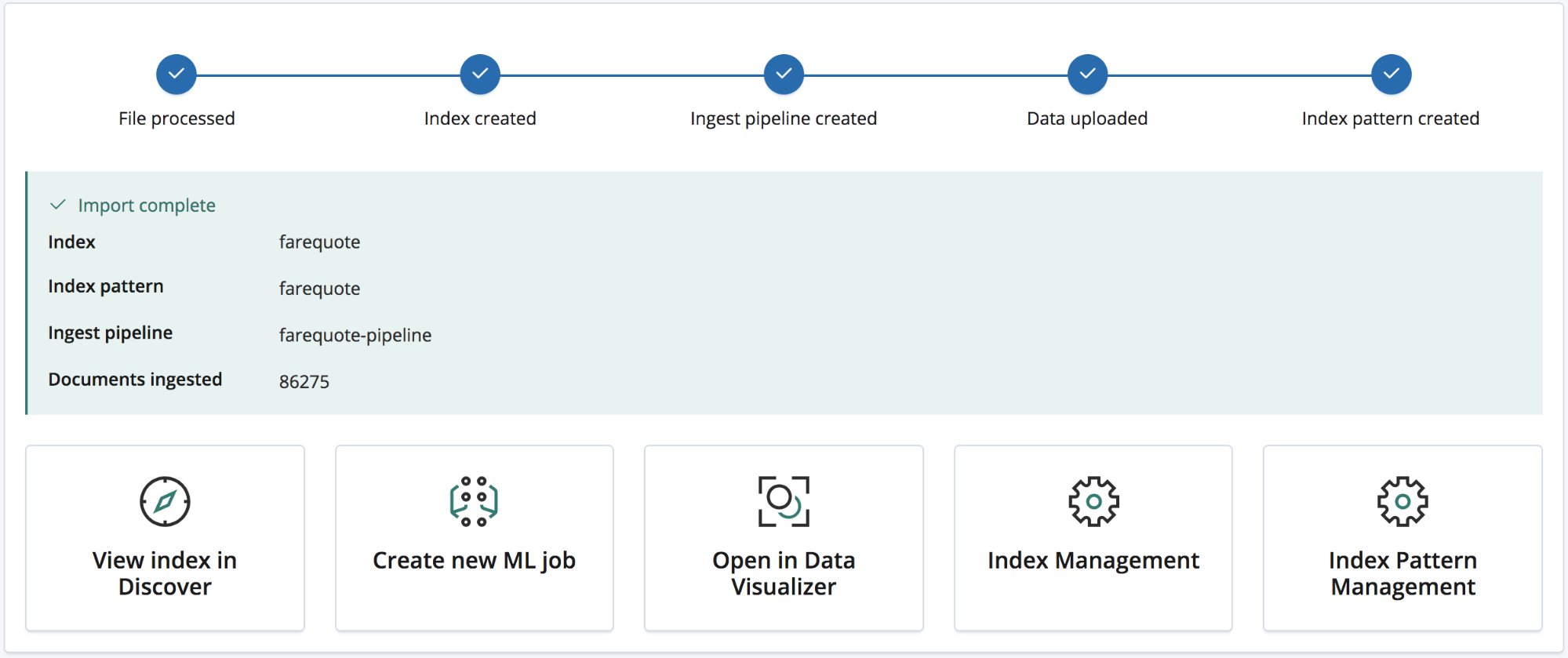
Depois que a importação estiver completa, o usuário verá um resumo com os nomes do índice, o padrão do índice e um pipeline de ingestão que terão sido criados assim como o número de documentos ingeridos.
Além de uma série de links do Kibana para explorar os novos dados importados. Os usuários das assinaturas Platinum e de teste também receberão um link para criar rapidamente um trabalho de machine learning com os dados.
Exemplo: importar arquivos de log e outros de textos semiestruturados para o Elasticsearch
Até agora, falamos de dados de CSV (e NDJSON é até mais simples com pouco processamento necessário na importação), mas e arquivos de texto semiestruturado? Vamos ver como a análise da dados CSV difere dos dados de log típicos, ou seja, de texto semiestruturado.
Abaixo, temos três linhas de um arquivo de log gerado por um roteador.
<190>38377: GOW45-AR002: Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378: GOW45-AR002: Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379: GOW45-AR002: Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
Quando analisado pelo endpoint find_file_structure, ele reconhece corretamente que o formato é de texto semiestruturado e cria um padrão grok para extrair os campos e seus tipos de cada linha. Desses campos, ele também reconhece qual é o campo do tempo e seu formato.
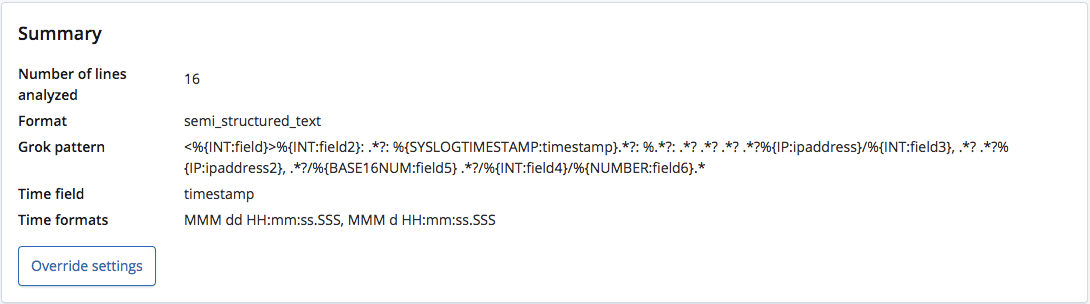
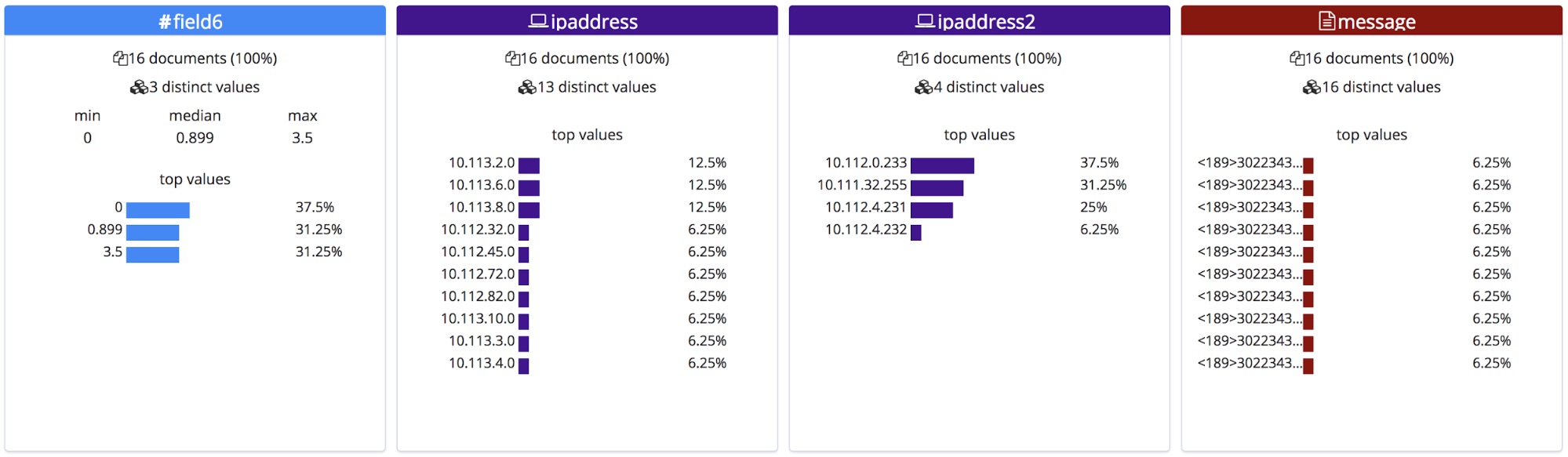
Diferentemente de um arquivo CSV com cabeçalho ou de um arquivo NDJSON, não há como saber os nomes corretos para esses campos, por isso o endpoint dá a eles nomes gerais com base em seus tipos.
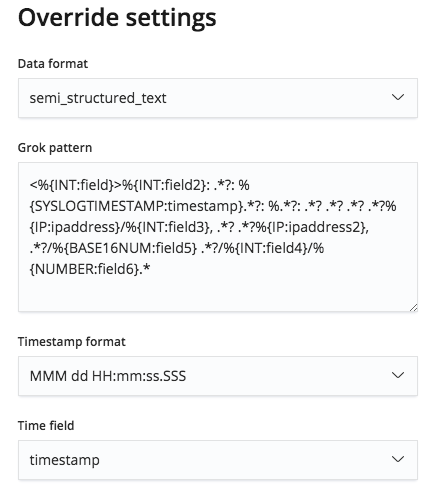
No entanto, esse padrão grok é editável pelo menu Override settings e, por isso, temos como corrigir os nomes dos campos e seus tipos.
Esses nomes de campo corrigidos serão exibidos na seção de estatísticas do File. Observe que eles estão em ordem alfabética e por isso mudaram um pouco de ordem.
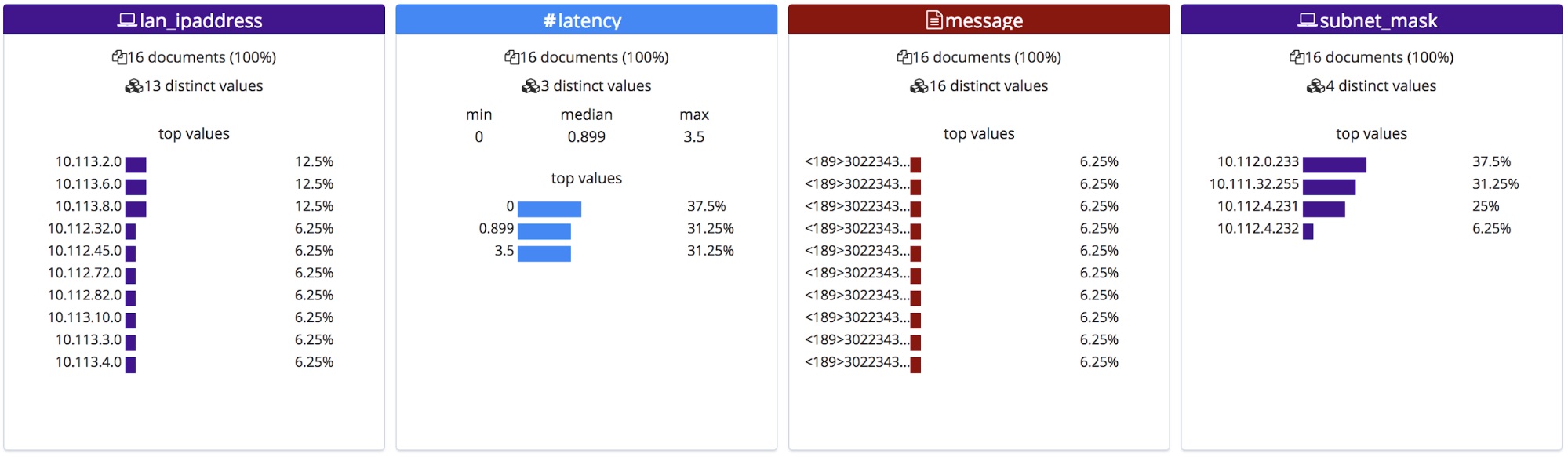
Ao serem importados, esses nomes de campos novos são adicionados ao objeto de mapeamento e o padrão grok é adicionado à lista de processadores no pipeline de ingestão.
Resumo
Esperamos que esse post tenha deixado você com vontade de experimentar o novo File Data Visualizer na versão 6.5. Esse ainda é um recurso experimental na versão 6.5 e por isso pode não ser compatível com todos os formatos, mas experimente e conte para nós o que achou. Seu feedback vai nos ajudar a deixar esse recurso com disponibilidade geral (GA) em breve.