Faça buscas diretamente no S3 com a nova camada frozen
Temos a satisfação de anunciar a prévia técnica da camada frozen na versão 7.12, permitindo que você desassocie completamente a computação do armazenamento e faça buscas diretamente em armazenamentos de objetos como AWS S3, Microsoft Azure Storage e Google Cloud Storage. O próximo marco importante em nossa jornada pela camada de dados, a camada frozen expande significativamente o alcance de seus dados, armazenando grandes quantidades de dados para longa duração a um custo muito mais baixo, mantendo-os totalmente ativos e buscáveis.
Faz muito tempo que oferecemos suporte para várias camadas de dados na gestão do ciclo de vida dos dados, sendo a hot para alta velocidade e a warm com custo e desempenho mais baixos. Ambos aproveitam o hardware local para armazenar seus dados principais e cópias redundantes. Mais recentemente, apresentamos a camada cold, que permite armazenar até duas vezes os dados na mesma quantidade de hardware em relação à camada warm, eliminando a necessidade de armazenar as suas cópias redundantes localmente. Embora os dados principais ainda sejam locais para se obter um desempenho ideal, os índices na camada cold são respaldados por snapshots buscáveis do seu armazenamento de objetos para redundância.

A camada frozen dá um grande passo adiante ao eliminar a necessidade de armazenar dados localmente. Em vez disso, ela usa snapshots buscáveis para busca direta em dados no armazenamento de objetos, sem a necessidade de reidratá-los primeiro. Um cache local armazena dados consultados recentemente para proporcionar desempenho ideal em buscas repetidas. Como resultado, os custos de armazenamento caem significativamente — até 90% em relação às camadas hot ou warm e até 80% em relação à camada cold. O ciclo de vida totalmente automatizado dos seus dados agora está completo — de hot para warm, cold e depois frozen, tudo garantindo que você tenha o acesso e o desempenho necessários na busca, com o menor custo de armazenamento possível.
Bons dados nunca são demais
Seja para observabilidade, segurança ou busca empresarial, seus dados de TI podem continuar crescendo a uma taxa exponencial. É comum que as organizações façam a ingestão e busca de muitos terabytes por dia. Esses dados são essenciais não apenas para o sucesso do dia a dia, mas também para referência histórica. Lookback ilimitado para investigações de segurança, exploração de anos de dados de APM para identificação de tendências ou a descoberta ocasional para conformidade regulatória são todos casos de uso importantes para manter seus dados disponíveis e acessíveis por mais tempo. No entanto, satisfazer esses casos de uso poderá rapidamente se tornar muito caro se você não tiver as ferramentas ou a tecnologia certas para armazenar os dados e, ao mesmo tempo, possibilitar buscas com facilidade.
É aí que entra em cena a camada frozen. Ela abre a porta para todos esses casos de uso, pois torna mais econômico armazenar anos de dados a um custo comparável ao do arquivamento de dados no S3 ou em outro armazenamento de objetos. A principal diferença é que, com a camada frozen, os dados permanecem totalmente buscáveis no Elasticsearch, e todos os seus dashboards do Kibana vão funcionar extraindo dados da camada frozen. Já se foi o tempo em que era necessário encontrar e extrair manualmente os dados do arquivo, restaurá-los e depois disponibilizá-los para busca. Também não precisamos mais ficar pensando em quais dados reter e quais excluir. Tudo se torna fácil e perfeito agora com a camada frozen.
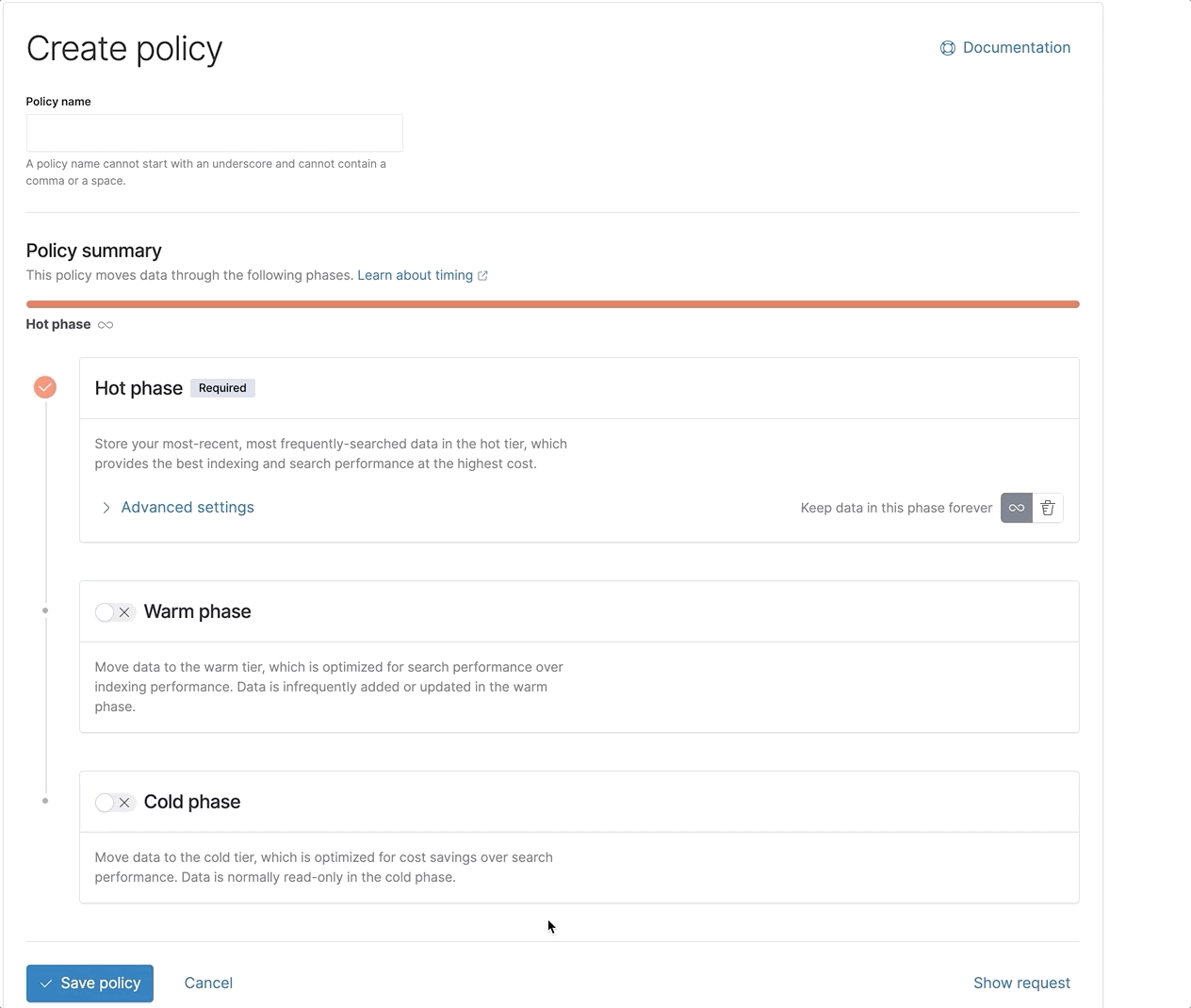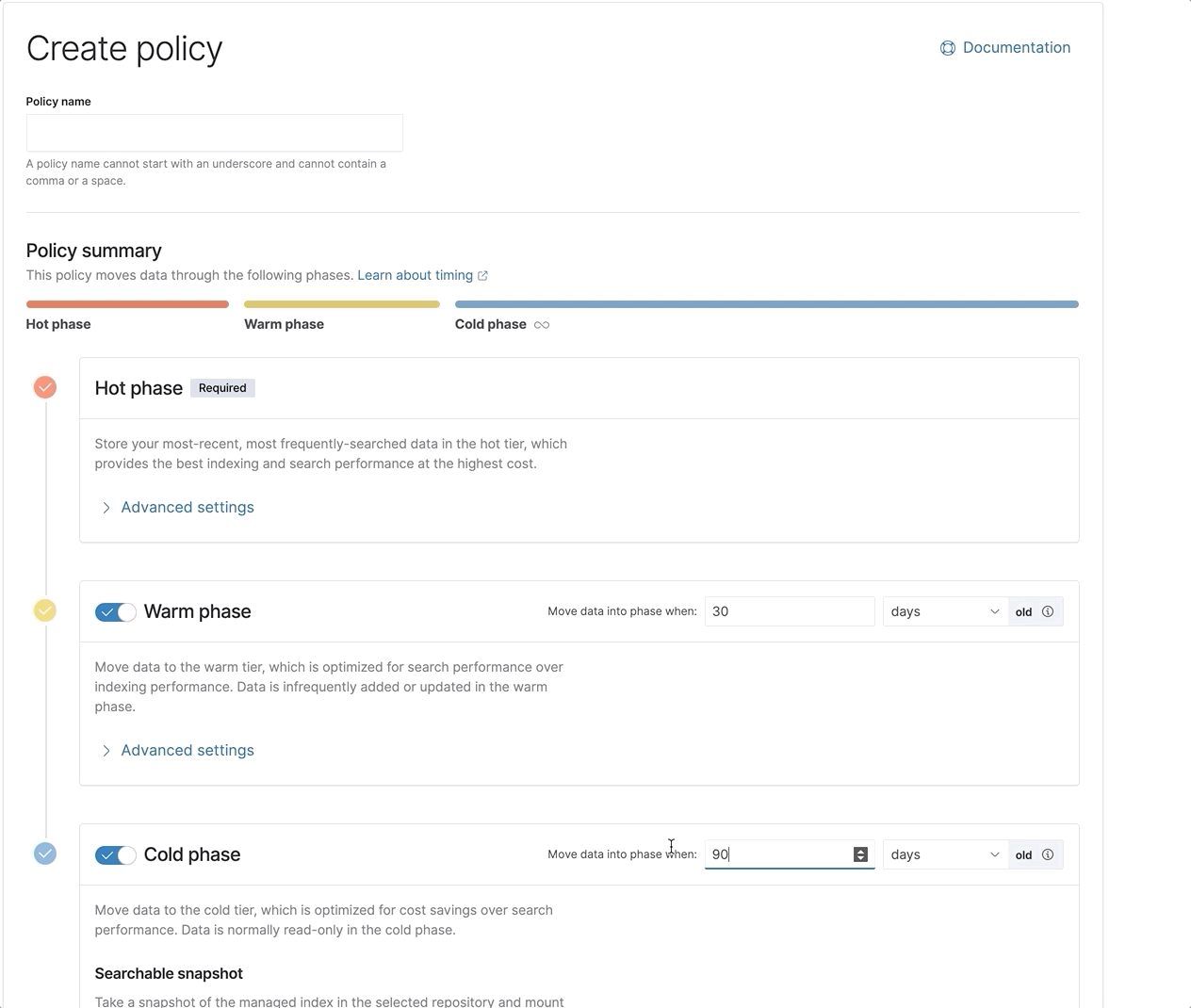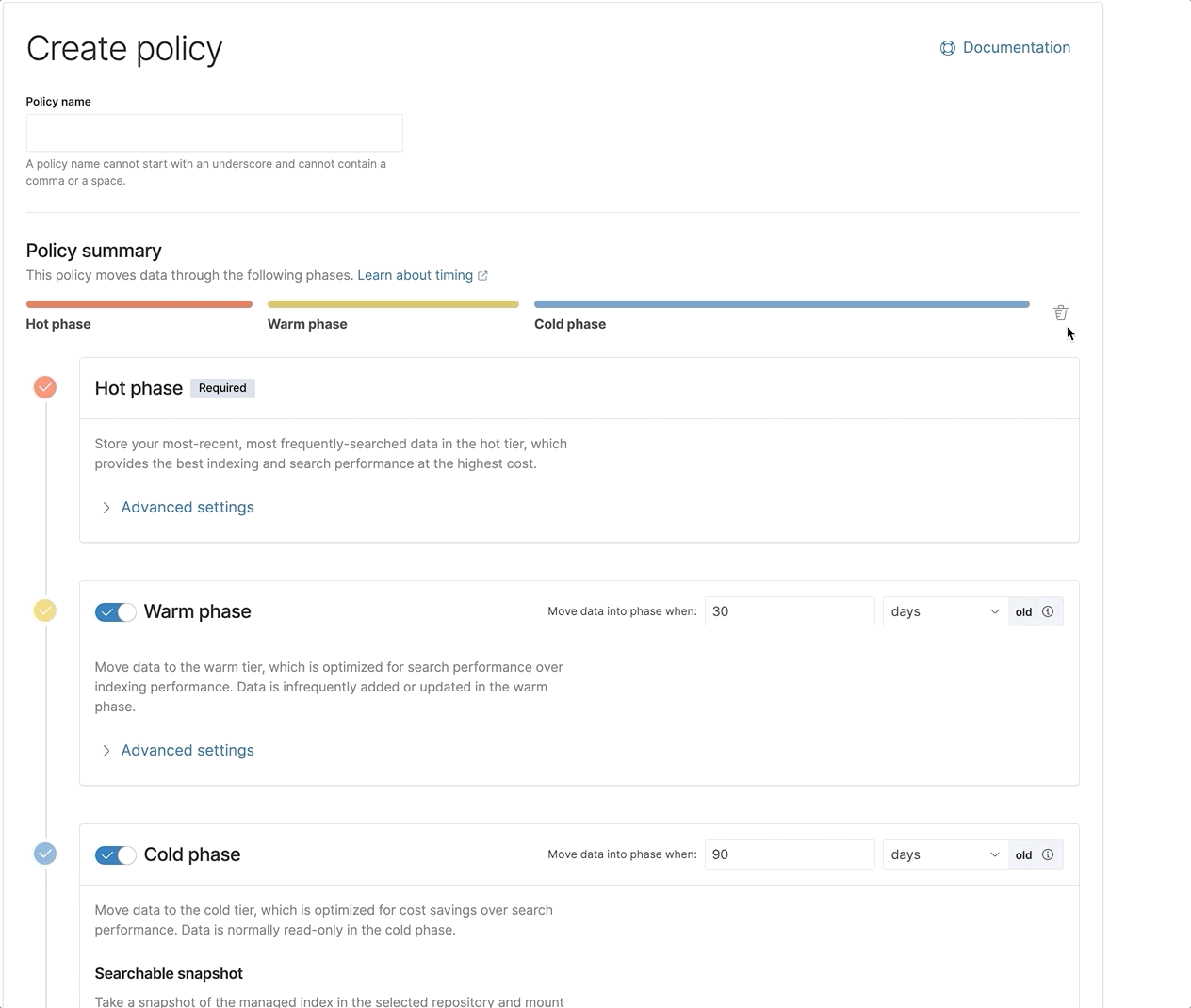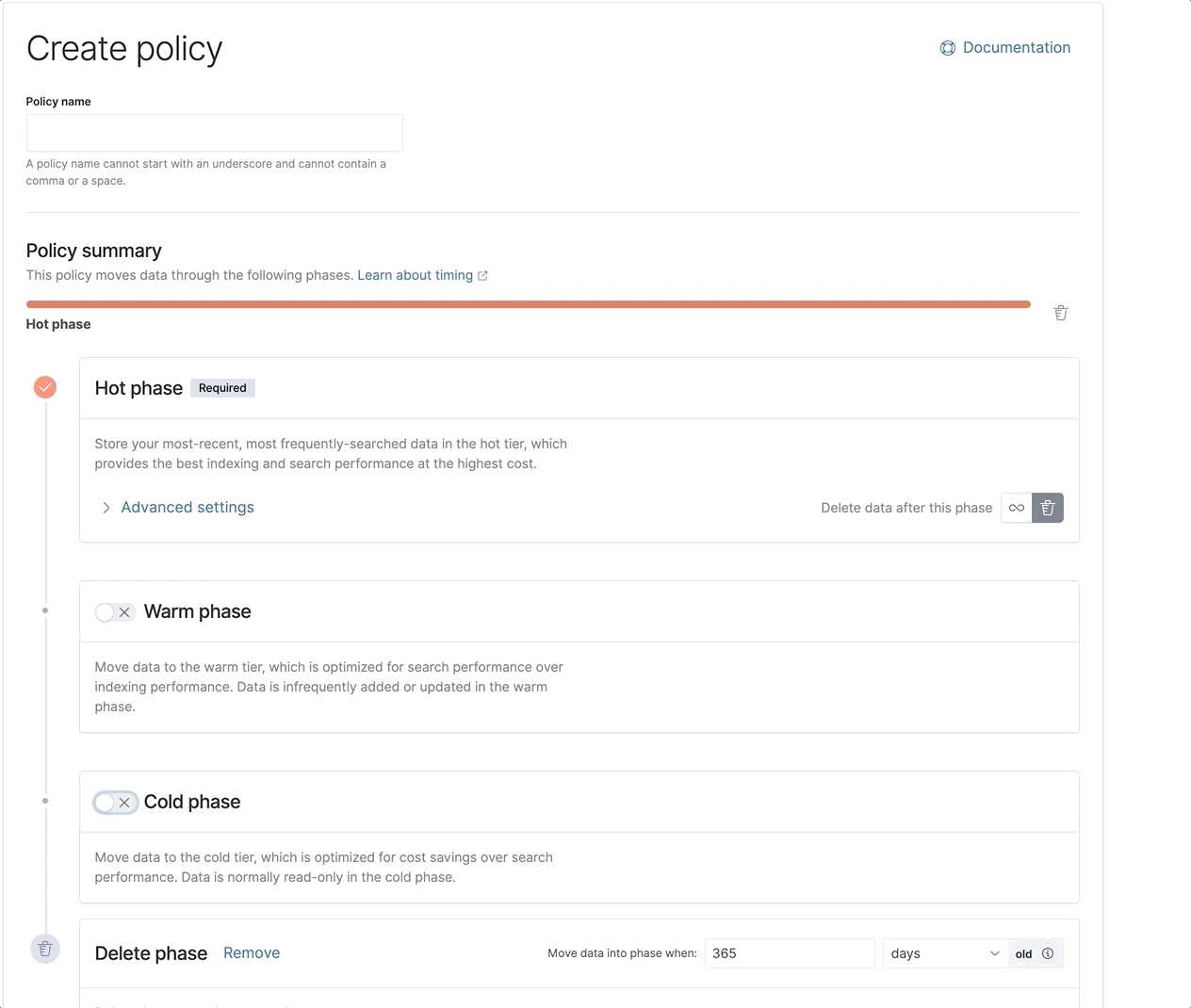
Como funciona
A camada frozen utiliza os snapshots buscáveis para desassociar a computação do armazenamento. Conforme os dados migram da camada warm ou cold para a frozen com base na sua política de gestão do ciclo de vida de índices (ILM), seus índices em nós locais são migrados para o S3 ou um armazenamento de objetos de sua escolha. A camada cold migra os índices para o armazenamento de objetos, mas ainda retém uma única cópia completa dos dados nos nós locais para garantir buscas rápidas e consistentes. A camada frozen, por outro lado, elimina totalmente a cópia local e busca os dados diretamente no armazenamento de objetos. Ela cria um cache local de dados consultados recentemente para agilizar buscas repetidas, mas o tamanho do cache precisa ser apenas uma fração do tamanho total dos dados armazenados na camada frozen.
Com um tamanho de cache local típico de 10%, isso significa que você só precisa de alguns nós da camada local para lidar com centenas de terabytes de dados da camada frozen. Aqui está uma comparação simples: se o seu nó da camada warm típico com 64 GB de RAM gerencia 10 TB, um nó da camada cold será capaz de lidar com cerca de duas vezes mais, ou 20 TB, e um nó da camada frozen saltará para 100 TB. Isso equivale a uma proporção de 1 para 1.500 de RAM para armazenamento, e essa é apenas uma estimativa conservadora.
Preço versus desempenho
Então, qual é a compensação? Bem, para nenhuma surpresa, é o desempenho. É por isso que oferecemos essas várias camadas de dados, para que você tenha a flexibilidade de definir as políticas de ILM apropriadas para a sua organização e determinar por quanto tempo e quantos dados devem residir nas camadas hot, warm, cold e frozen. Os dados armazenados na camada frozen devem ser buscados ocasionalmente e não precisam oferecer o desempenho das outras camadas.
Também fizemos um grande progresso na otimização para a melhor experiência possível do usuário com buscas de execução mais lenta. Desenvolvemos a busca assíncrona no Elasticsearch, que nos possibilita fornecer uma experiência natural no Kibana, permitindo processar dashboards em segundo plano e recuperá-los mais tarde. Também introduzimos uma série de melhorias na eficiência das consultas para acelerar as consultas de execução lenta, inclusive pulando índices sem correspondência na pré-filtragem, saindo das buscas mais cedo onde possível, usando block-max WAND para busca de texto e assim por diante.
Como todos os dados são indexados por padrão no Elasticsearch, a busca de dados na camada frozen é especialmente eficiente porque podemos aproveitar as estruturas de índice concisas para retornar resultados em grandes conjuntos de dados muito rapidamente, sem ter de fazer varreduras nos próprios dados. Além disso, uma das coisas mais legais que fizemos com os snapshots buscáveis é usar o nosso profundo conhecimento em Lucene para extrair apenas aqueles subconjuntos do índice realmente necessários para responder a uma consulta.
Juntas, todas essas otimizações garantem a melhor e mais rápida experiência possível ao fazer buscas na camada frozen. Junto com uma UI de ILM redesenhada para tornar muito mais fácil definir e configurar suas políticas de ILM, agora você tem todas as ferramentas de que precisa para começar de forma rápida e eficaz com o conjunto completo de camadas de dados da Elastic.
Armazenamento público ou privado, você escolhe
Nossa abordagem na Elastic sempre foi oferecer a você a maior flexibilidade possível com o mínimo de interrupção. Além do suporte oficial que temos para AWS S3, Azure Cloud Storage, Google Cloud Storage e MinIO, agora estamos lançando um kit de teste de repositório para testar e validar qualquer armazenamento de objetos compatível com S3 para trabalhar com snapshots buscáveis, com a camada cold e com a camada frozen.
Disponível como uma API facilmente consumível, o kit de teste permite que você execute uma série de testes rápidos em seu próprio armazenamento de objetos compatível com S3. Se eles forem bem-sucedidos, você poderá usá-lo para armazenamento e busca dos seus snapshots, além de habilitá-lo como armazenamento de objetos para as camadas cold e frozen. Como esse é um kit de teste de validação, é importante observar que isso não significa que estamos oficialmente dando suporte a qualquer armazenamento compatível com S3 que passe na validação. Se um problema for encontrado, ele precisará ser reproduzível em dispositivos S3 compatíveis para que possamos corrigi-lo.
Linha do tempo
A camada frozen está sendo introduzida como uma prévia técnica no Elastic 7.12. As camadas hot, warm e cold já estão com disponibilidade geral, assim como o recurso subjacente de snapshots buscáveis que dá suporte às camadas cold e frozen. A camada frozen também está disponível no Elastic Cloud a partir da versão 7.12, com um controle deslizante mais simples e pronto para uso que será lançado em breve.
Comece hoje mesmo
Para começar a usar a camada frozen, prepare um cluster no Elastic Cloud ou instale a versão mais recente do Elastic Stack. Já tem o Elasticsearch em execução? Basta atualizar seus clusters para a versão 7.12 e experimentar. Se quiser experimentar no Elastic Cloud, os detalhes estão disponíveis na documentação do Elastic Cloud. Essas etapas desaparecerão assim que o controle deslizante da camada frozen se tornar disponível. Se quiser saber mais sobre a camada frozen, leia o post do blog sobre snapshots buscáveis, a documentação do produto sobre snapshots buscáveis ou a documentação do produto sobre camadas de dados.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste documento permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.