Seamlessly connect with leading AI and machine learning platforms. Start a free cloud trial to explore Elastic’s gen AI capabilities or try it on your machine now.
Take your search experiences up to level 11 with our new state-of-the-art cross-encoder Elastic Rerank model (in Tech Preview). Reranking models provide a semantic boost to any search experience, without requiring you to change the schema of your data, giving you room to explore other relevance tools for semantic relevance on your own time and within your budget.
Semantic boost your keyword search: Regardless of where or how your data is stored, indexed or searched today, semantic reranking is an easy additional step that allows you to boost your existing search results with semantic understanding. You have the flexibility to apply this as needed– without requiring changes to your existing data or indexing pipelines and you can do this with an Elastic foundational model as your easy first choice.
Flexibility of choice for any budget: All search experiences can be improved with the addition of semantic meaning which is typically applied by utilizing a dense or sparse vector model such as ELSER. However, achieving your relevance goals doesn’t require a one-size-fits-all solution, it’s about mixing and matching tools to balance performance and cost. Hybrid search is one such option, improving relevance by combining semantic search with keyword search using reciprocal rank fusion (RRF) in Elasticsearch. The Elastic Rerank model is now an additional lever to enhance search relevance in place of semantic search, giving you the flexibility to optimize for both relevance and budget.
First made available on serverless, but now available in tech preview in 8.17 for Elasticsearch, the benefits of our model exceed those of other models in the market today.
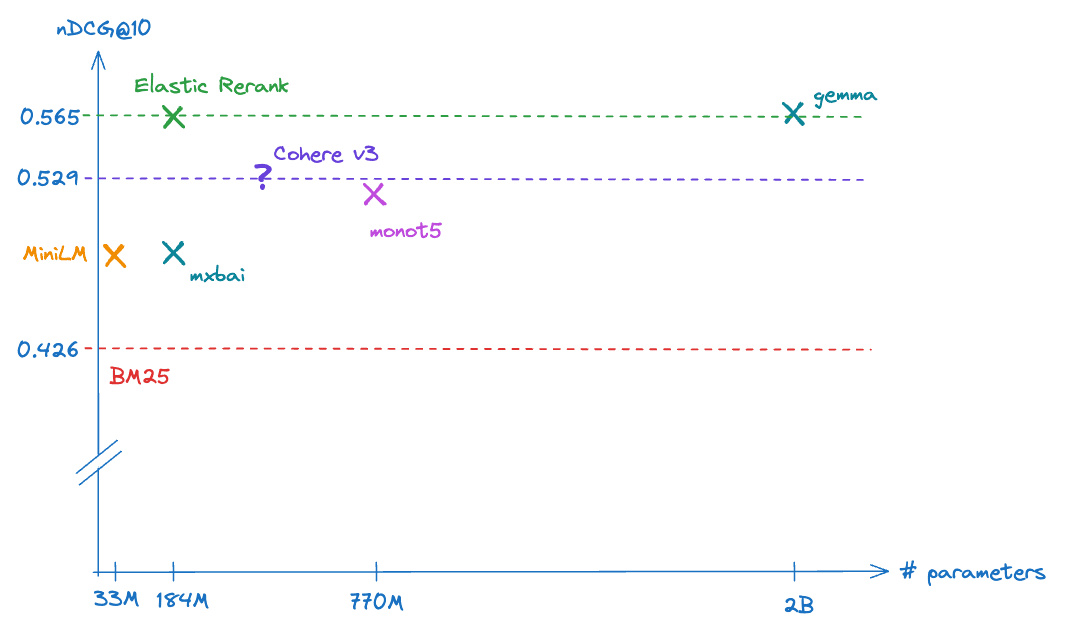
Performant and efficient: The Elastic Rerank model outperforms other significantly larger reranking models. Built on the DeBERTa v3 architecture, it has been fine-tuned by distillation on a diverse dataset. Our detailed testing shows a 40% uplift on a broad range of retrieval tasks and up to 90% on question answering data sets.
As a comparison, the Elastic Rerank model is significantly better or comparable in terms of relevance even with much larger models. In our testing a few models, such as bge-re-ranker-v2-gemma, came closest in relevance but are an order of magnitude larger in terms of parameter count. That being said, we provide integrations in our Open Inference API to enable access to other third-party rerankers, so you can easily test and see for yourself.
Using the Elastic Rerank model
Not only are the performance and cost characteristics of the Elastic Rerank model great, we have also made it really easy to use to improve the relevance for lexical search. We want to provide easy to use primitives that help you build effective search, quickly, and without having to make lots of decisions; from which models to use, to how to use them in your search pipeline. We make it easy to get started and to scale.
You can now use Elastic Rerank using the Inference API with the text_similiarity_reranker retriever. Once downloaded and deployed each search request can handle a full hybrid search query and rerank the resulting set in one simple _search query.
It’s really easy to integrate the Elastic Rerank model in your code, to combine different retrievers to combine hybrid search with reranking. Here is an example that uses ELSER for semantic search, RRF for hybrid search and the reranker to rank the results.
If you have a fun dataset like mine that combines the love of AI with Cobrai Kai you will get something meaningful.
Summary: The Elastic Rerank Model
- English only cross-encoder model
- Semantic Boost your Keyword Search with little to no changes how data is indexed and searched already
- More control and flexibility over the cost of semantic boosting decoupled from indexing and search
- Reuse the data you already have in Elasticsearch
- Delivers significant improvements in relevance and performance (40% better on average for a large range of retrieval tasks and up to 90% better on question answering tasks as compared to significantly larger models, tested with over 21 datasets with an average of +13 points nDCG@10 improvement)
- Easy-to-use, out-of-the-box; built into the Elastic Inference API, easy to load and use in search pipelines
- Available in technical preview on across our product suite, easiest way to get started is on Elasticsearch Serverless
If you want to read all the details of how we built this, head over to our blog on Search Labs.
Frequently Asked Questions
What are the benefits of using a reranking model?
Reranking models provide a semantic boost to any search experience, without requiring you to change the schema of your data, giving you room to explore other relevance tools for semantic relevance on your own time and within your budget.
Related Content

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.

January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.

January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.