Seamlessly connect with leading AI and machine learning platforms. Start a free cloud trial to explore Elastic’s gen AI capabilities or try it on your machine now.
In our previous blog in this series we introduced the concept of semantic reranking. In this blog, we're going to discuss the Elastic re-ranker, which we've trained and are releasing in technical preview.
Elastic Rerank introduction
One of our purposes at Elastic is lowering the bar to achieve high quality text search. Building on top of Lucene, Elasticsearch provides a rich set of scalable well optimized full-text retrieval primitives including lexical retrieval with BM25 scoring, learned sparse retrieval and a vector database. We've recently introduced the concept of retrievers to the search API, which allow for composable operations including semantic reranking. We're also working towards introducing advanced search pipelines to ES|QL.
Starting with our serverless offering, we're releasing in technical preview the Elastic Rerank model. This is a cross-encoder reranking model. Over time we plan to integrate it with our full product suite and provide optimized versions to run on ML nodes in any cluster; exactly as we do for our retrieval model. We've also been working on some exciting new inference capabilities, which will be ideally suited to reranking workloads, so expect further announcements.
This first version targets English text reranking and provides some significant advantages in terms of quality as a function of inference cost compared to the other models we evaluated. In this blog post we will discuss some aspects of its architecture and training. But first…
Elastic Rerank vs. other models: How does it compare?
In our last blog, we discussed how lexical retrieval with BM25 scoring or (BM25 for short) represents an attractive option in cases where the indexing costs using sparse or dense models would be very high. However, newer methodologies tend to give very significant relevance improvements compared to BM25, particularly for more complex natural language queries.
As we've discussed before, the BEIR suite is a high quality and widely used benchmark for English retrieval. It is also used by the MTEB benchmark to assess retrieval quality of text embeddings. It includes various tasks, including open-domain Question Answering (QA) where BM25 typically struggles. Since BM25 represents a cost effective first stage retriever, it is interesting to understand to what extent we can use reranking to “fix up” its relevance as measured by BEIR.
In our next blog, we're going to present a detailed analysis of the different high quality re-rankers we include in the table below. This includes more qualitative analysis of their behavior as well as some additional insights into their cost-relevance trade-offs. Here, we follow prior art and describe their effectiveness reranking the top 100 results from BM25 retrieval. This is fairly deep reranking and not something we would necessarily recommend for inference on CPU. However, as we'll show in our next blog, it provides a reasonable approximation of the uplift in relevance you can achieve from reranking.
| Model | Parameter Count | Average nDCG@10 |
|---|---|---|
| BM25 | - | 0.426 |
| MiniLM-L-12-v2 | 33M | 0.487 |
| mxbai-rerank-base-v1 | 184M | 0.48 |
| monoT5-large | 770M | 0.514 |
| Cohere v3 | n/a | 0.529 |
| bge-re-ranker-v2-gemma | 2B | 0.568 |
| Elastic | 184M | 0.565 |
Average nDCG@10 for the BEIR reranking the top 100 BM25 retrieved documents
To give a sense of the relative cost-relevance trade-off of the different models we've plotted this table below.
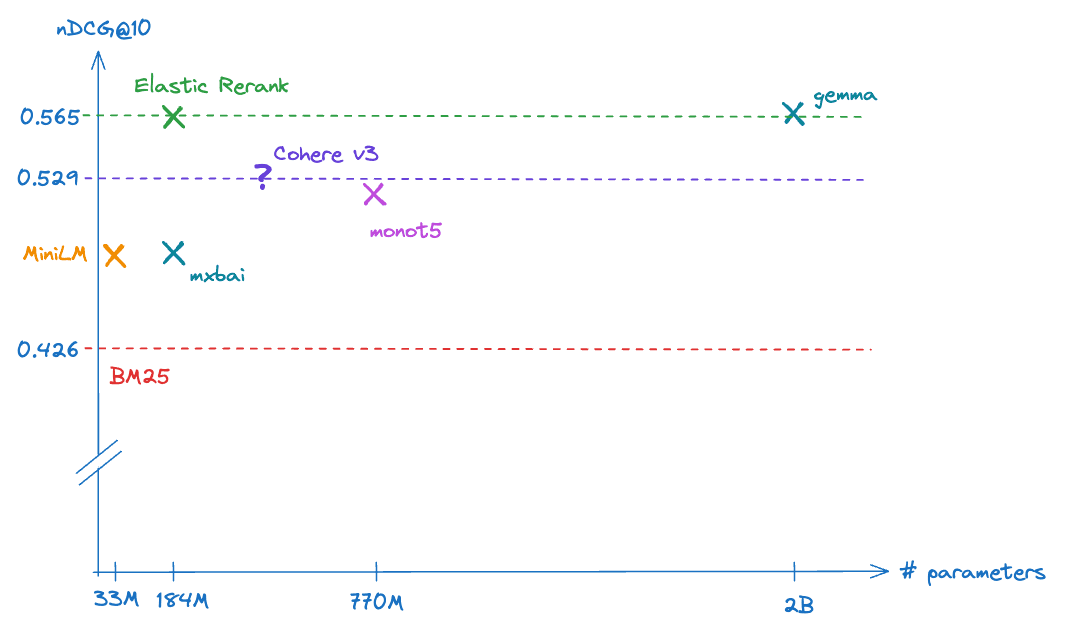
Average nDCG@10 for the BEIR reranking the top 100 BM25 retrieved documents. Up and to the left is better
For completeness we also show the individual dataset results for Elastic Rerank below. This represents an average improvement of 39% across the full suite. At the time of writing, this puts reranked BM25 around position 20 of all methods on the MTEB leaderboard. All more effective models use large embeddings, with at least 1024 dimensions, and significantly larger models (on average 30⨉ larger than Elastic Rerank).
| Dataset | BM25 nDCG@10 | Reranked nDCG@10 | Improvement |
|---|---|---|---|
| AguAna | 0.47 | 0.68 | 44% |
| Climate-FEVER | 0.19 | 0.33 | 80% |
| DBPedia | 0.32 | 0.45 | 40% |
| FEVER | 0.69 | 0.89 | 37% |
| FiQA-2018 | 0.25 | 0.45 | 76% |
| HotpotQA | 0.6 | 0.77 | 28% |
| Natural Questions | 0.33 | 0.62 | 90% |
| NFCorpus | 0.33 | 0.37 | 12% |
| Quora | 0.81 | 0.88 | 9% |
| SCIDOCS | 0.16 | 0.20 | 23% |
| Scifact | 0.69 | 0.77 | 12% |
| Touche-2020 | 0.35 | 0.36 | 4% |
| TREC-COVID | 0.69 | 0.86 | 25% |
| MS MARCO | 0.23 | 0.42 | 85% |
| CQADupstack (avg) | 0.33 | 0.41 | 27% |
*nDCG@10 per dataset for the BEIR reranking the top 100 BM25 retrieved documents using the Elastic Rerank model.
Re-ranker architecture
As we've discussed before, language models are typically trained in multiple steps. The first stage training takes randomly initialized model weights and trains on a variety of different unsupervised tasks such as masked token prediction. These pretrained models are then trained on further downstream tasks, such as text retrieval, in a process called fine-tuning. There is extensive empirical evidence that the pre-training process generates useful features which can be repurposed for new tasks in a process called transfer learning. The resulting models display significantly better performance and significantly reduced train time compared to training the downstream task alone. This technique underpins a lot of the post BERT successes of transformer based NLP.
The exact pre-training methods and the model architecture affect downstream task performance as well. For our re-ranker we've chosen to train from a DeBERTa v3 checkpoint. This combines various successful ideas from the pre-training literature and has provided state-of-the-art performance as a function of model size on a variety of NLP benchmarks when fine-tuned.
To very briefly summarize this model:
- DeBERTa introduced a disentangled positional and content encoding mechanism that allows it to learn more nuanced relationships between hidden representations of the content and position of other tokens in the sequence. We conjecture this is particularly important for reranking since matching words in the query and document text and comparing their semantics is presumably a key ingredient.
- DeBERTa v3 adopts the ELECTRA pre-training objective which, GAN style, tries to simultaneously train a model to supply effective fake tokens and learn to recognize those fakes. They also propose a small improvement to parameterisation of this process.
If you're interested you can find the details here.
For the first version, we trained the base variant of this model family. This has 184M parameters, but since its vocabulary is around 4⨉ the size of BERT's, the backbone is only 86M parameters, with 98M parameters used for the input embedding layer. This means the inference cost is comparable to BERT base. In our next blog we explore optimal strategies for budget constrained reranking. Without going into the details suffice to say we plan to train a smaller version of this model via distillation.
Data sets and training for Elastic Reranker
Whenever you train a new task on a model there is always a risk that it forgets important information. Our first step training the Elastic Reranker was therefore to make the best attempt to extract relevance judgments from DeBERTa as it is. We use a standard pooling approach; in particular, we add a head that:
- Computes where is a GeLU activation, is a dropout layer and is a linear layer. In pre-training the token representation, , is used for a next sentence classification task. This is well aligned with relevance assessment so its a natural choice to use as the input to the head,
- Computes the weighted average of the output activations to score the query-document pair.
We train the head parameters to convergence, freezing the rest of the model, on a subset of our full training data. This step updates the head to read out what useful information it can for relevance judgments from the pre-trained token representation. Performing a two step fine-tune like this yielded around a 2% improvement in the final nDCG@10 on BEIR.
It is typical to train ranking tasks with contrastive methods. Specifically, a query is compared to one relevant (or positive) and one or more irrelevant (or negative) documents and the model is trained to prefer the relevant one. Rather than using a purely contrastive loss, like maximizing the log probability of the positive document, a strong teacher model can be used to provide ground truth assessment of the relevance of the documents. This choice handles issues such as mislabeling of negative examples. It also provides significantly more information per query than just maximizing the log probability of the relevant document.
To train our cross-encoder we use a teacher to supply a set of scores from which we compute a reference probability distribution of the positive and negative documents for each query using the softmax function as follows:
Here, is the query text, is the positive text, is the set of negative texts, and the function is the output of the cross-encoder.
We minimize the cross-entropy of our cross-encoder scores with this reference distribution. We also tried Margin-MSE loss, which worked well training ELSER, but found cross-entropy was more effective for the reranking task.
This whole formulation follows because it is natural to interpret pointwise ranking as assessing the probability that each document is relevant to the query. In this case, minimizing cross-entropy amounts to fitting a probability model by maximum likelihood with the nice properties such an estimator confers. Compared to Margin-MSE, we also think we get gains because cross-entropy allows us to learn something about the relationship between all scores, since it is minimized by exactly matching the reference distribution. This is relevant because, as we discuss below, we train with more than one negative.
For the teacher, we use a weighted average ensemble of a strong bi-encoder model and a strong cross-encoder model. We found the bi-encoder provides a more nuanced assessment of the negative examples, which we hypothesize is due to large batch training that contrasts millions of distinct texts per batch. However, the cross-encoder was better at differentiating the positive and negative examples. In fact, we expect there are further improvements to be made in this area. Specifically, for model selection we use a small but effective proxy to a diverse retrieval task and we plan to explore if it is beneficial to use black box optimization of our teacher on this task.
The training dataset and negative sampling are critical for model quality.
Our training dataset comprises a mixture of open QA datasets and datasets with natural pairs, like article heading and summary. We apply some basic cleaning and fuzzy deduplication to these. Using an open source LLM, we also generated around 180 thousand pairs of synthetic queries and passages with varying degrees of relevance. We used a multi-stage prompting strategy to ensure this dataset covers diverse topics and a variety of query types, such as keyword search, exact phrase matching and short and long natural language questions. In total, our training dataset contains around 3 million queries.
It has been generally observed that quality can degrade with the reranking depth. Typically hard negative mining uses shallow sampling of retrieval results: it searches out the hardest negatives for each query. Document diversity increases with retrieval depth and we believe that typical hard negative mining therefore doesn't present the re-ranker with sufficient diversity. In particular, training must demonstrate adequate diversity in the relationship between the query and the negative documents.
This flaw isn't solved by increasing overall query and document diversity; training must include negative documents from the deep tail of retrieval results. For this reason, we extract the top 128 documents for each query using multiple methods. We then sample five negatives from this pool of candidates using a probability distribution shaped by their scores. Using this many negatives per query is not typical; however, we found increasing the number of sampled negatives gave us a significant bump in final quality.
A nice side effect of using a large and diverse negative set for each query is it should help model calibration. This is a process by which the model scores are mapped to a meaningful scale, such as an estimate of relevance probability. Well calibrated scores provide useful information for downstream processing or directly to the user. They also help with other tasks such as selecting a cutoff at which to drop results. We plan to release some work we've done studying calibration strategies and how effectively they can be supplied to different retrieval and reranking models in a separate blog.
Training language models has traditionally required learn rate scheduling to achieve the best possible results. This is the process whereby the multiplier of the step size used for gradient descent is changed as training progresses. It presents some challenges: the total number of training steps must be known in advance; also it introduces multiple additional hyperparameters to tune.
Some recent interesting work demonstrated that it is possible to drop learn rate scheduling if you adopt a new weight update scheme that includes averaging of the parameters along the optimization trajectory. We adopted this scheme, using AdamW as the base optimizer, and found it produced excellent results as well as being easy to tune.
Summary
In this blog, we've introduced our new Elastic Rerank model. It is fine-tuned from the DeBERTa v3 base model on a carefully prepared data set using distillation from an ensemble of a bi-encoder and cross-encoder model.
We showed that it provides state-of-the-art relevance reranking lexical retrieval results. Furthermore, it does so using dramatically fewer parameters than competitive models. In our next blog post, we study its behavior in much more detail and revisit the other high quality models with which we've compared it here. As a result, we're going to provide some additional insights into model and reranking depth selection.
Frequently Asked Questions
What is the Elastic Rerank model?
Elastic Rerank is a cross-encoder reranking model.
How was the Elastic Rerank model fine-tuned?
The Elastic Rerank model was fine-tuned from the DeBERTa v3 base model on a carefully prepared data set using distillation from an ensemble of a bi-encoder and cross-encoder model.