Seamlessly connect with leading AI and machine learning platforms. Start a free cloud trial to explore Elastic’s gen AI capabilities or try it on your machine now.
In this series of blogs we'll introduce Elastic's new semantic reranker. Semantic reranking often improves relevance, particularly in a zero-shot setting. It can also be used to trade-off indexing compute cost for querying compute cost by significantly improving lexical retrieval relevance.
In this first blog we set the scene with some background on semantic reranking and how it can fit into your search and RAG pipelines. In the second installment, we introduce you to Elastic Rerank: Elastic's new semantic re-ranker model we've trained and released in technical preview.
Retrieval
Typically, text search is broken down into multiple stages, which gradually filter the result set into the final list that is presented to a user (or an LLM).
The first stage is called retrieval and must be able to scale to efficiently compare the query text with a very large corpus of candidate matches. This limits the set of approaches that one can consider.
For many years, the only paradigm available for retrieval was lexical. Here documents and queries are treated as bags of words and a statistical model is used to deduce relevance. The most popular option in this camp is BM25. For this choice, the query can be efficiently compared with a huge document corpus using inverted indices together with clever optimisations to prune non-competitive candidates. It remains a useful option since many queries, such as keyword searches and exact phrase matching, are well aligned with this model and it is easy to efficiently apply filtering predicates at the same time. The scoring is also tailored to the corpus characteristics which makes it a strong baseline when no tuning is applied. Finally, it is particularly efficient from an indexing perspective: no model inference needs to run, updating index data structures is very efficient and a lot of state can permanently reside on disk.
In recent years, semantic retrieval has seen a surge in popularity. There are multiple flavors of this approach; for example, dense passage, learned sparse and late interaction retrieval. In summary, they use a transformer model to independently create representations of the query and each document and define a distance function on these representations to capture semantic similarity. For example, the query and document might be both embedded into a high dimensional vector space where queries and their relevant documents have low angular separation. These sorts of approaches have different strengths to BM25: they can find matches that require understanding synonyms, where the context is important to determine word meanings, where there are misspellings and so on. They also allow for wholly new relevance signals, such as embedding images and text in a common vector space.
Queries can be efficiently compared against very large corpuses of documents by dropping the requirement that exact nearest neighbor sets are found. Data structures like HNSW can be used to find most of the best matches in logarithmic complexity in the corpus size. Intelligent compression schemes allow significant amounts of data to reside on disk. However, it is worth noting that model inference must be run on all documents before indexing and these data structures are relatively expensive to build in comparison to inverted indices.
A lot of work has been done to improve the training of general purpose semantic retrieval models and indeed the best models significantly outperform BM25 in benchmarks that try and assess zero shot retrieval quality.
Semantic reranking
So far we have discussed methods that independently create representations of the query and document. This choice is necessary to scale retrieval. However, given the top N results returned by first stage retrieval we don't have the same constraint. The work that must be done to compare the query and these top N results is naturally much smaller, so we can consider new approaches for reordering them in order to improve relevance of the final result. This task is called reranking.
We define semantic reranking as using a model to assess the semantic similarity of a query and one (or more) document text(s). This is to distinguish it from other reranking methods such as learn to rank, which typically use a variety of features to model user preference. Note that what constitutes semantic similarity can vary from task to task: for example, finding similar documents requires assessing similarity of two texts, whereas answering a question requires understanding if the necessary information is contained in the document text.
In principle, any semantic first stage retrieval method can be used for reranking. For example, ELSER could be used to rerank the top results of a BM25 search. Keep in mind though that there may be blindspots in BM25 retrieval, which tends to have lower recall than semantic retrieval, and no reranking method will be able to fix these. It is therefore important to evaluate setups like these on your own data.
From a performance standpoint, one is trading indexing compute cost for querying compute cost and possibly latency. Compared to semantic retrieval, in addition to the cost of embedding the query, you must also embed each document you want to rerank. This can be a good cost trade-off if you have a very large corpus and/or one which is frequently updated and relatively few queries per second. Furthermore, for GPUs the extra cost is partly amortized by the fact that the document inferences can be processed as a batch, which allows for better utilization. However, there is little cost benefit compared to a model which gets to see the query and the document at the same time. This approach is called cross-encoding, as opposed to bi-encoding which is used for semantic retrieval, and can bring significant benefits.
Cross-encoders
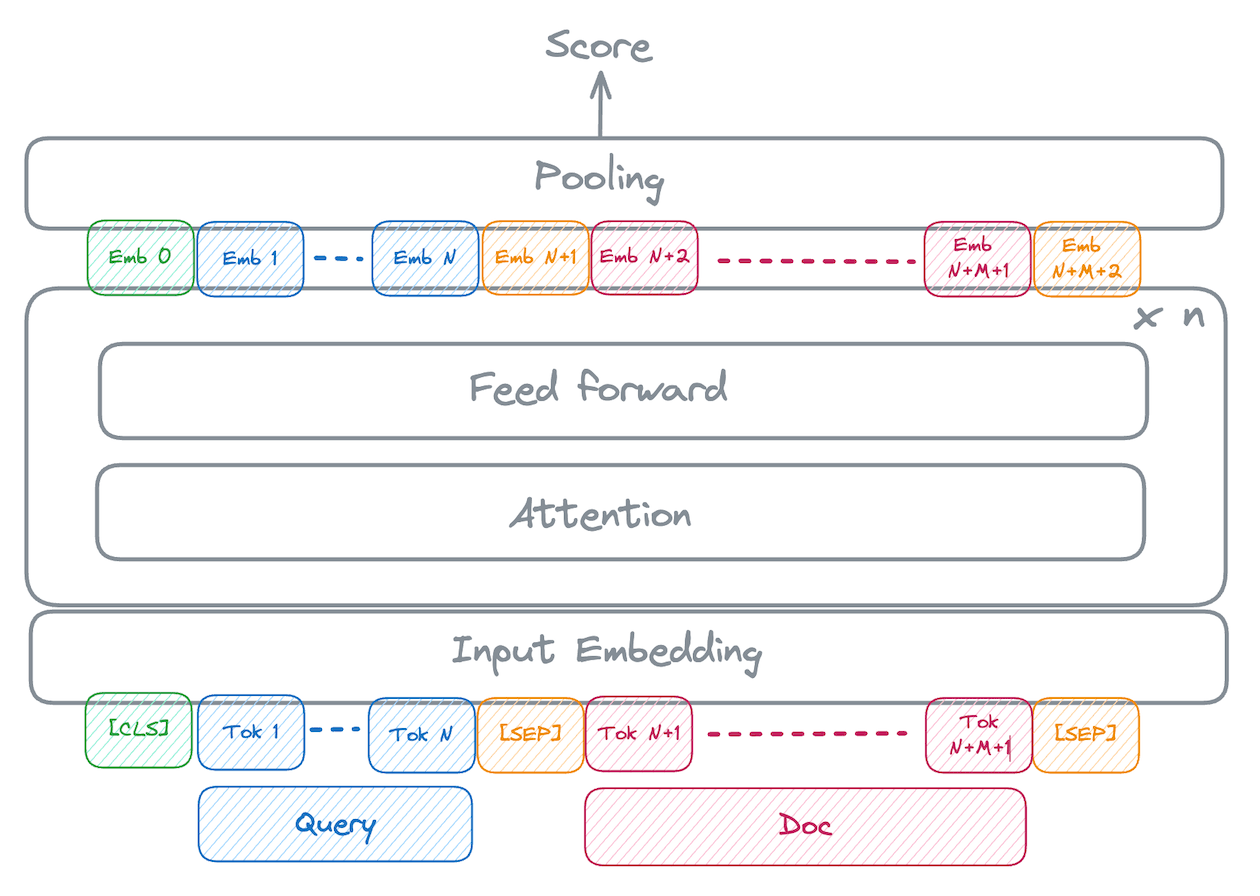
For cross-encoders both the query and a document text are presented together to the model concatenated with a special separation token. The model itself returns a similarity score. Schematically, the text is modeled something like the following:
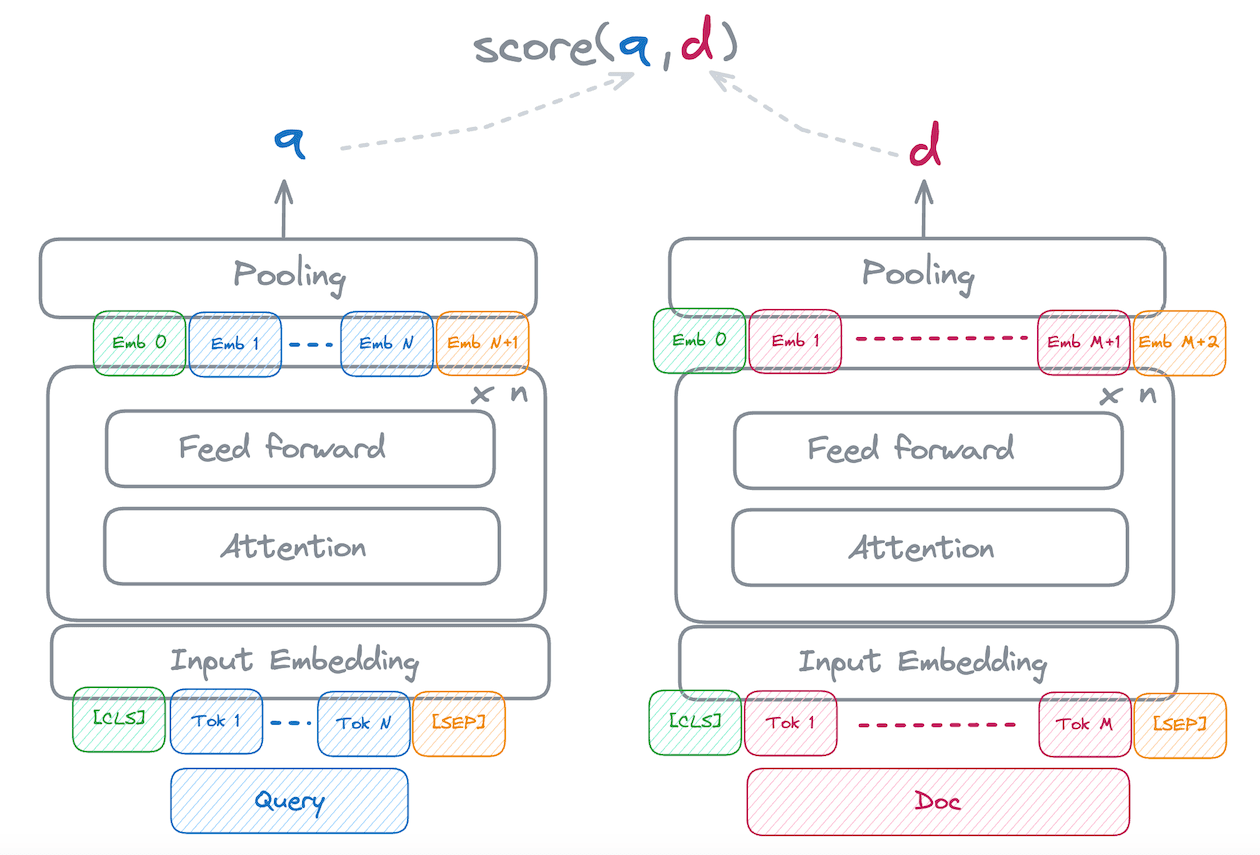
In a bi-encoder the query and the document are first embedded individually and then compared using a simple similarity function. Schematically, the text is modeled something like the following:
Reranking for a fixed query with a cross-encoder is framed as a regression problem. The model outputs a numerical scores for each query-document pair. Then the documents are sorted in descending score order. We will return to the process by which this model is trained in the second blog in this series. Conceptually, it is useful to realize that this allows the model to attend to different parts of the query and document text and learn rich features for assessing relevance.
It has been observed that this process allows the model to learn more robust representations for generally assessing relevance. It also potentially allows the model to capture more nuanced semantics. For example, bi-encoder models struggle with things like negation and instead tend to pick up on matches for the majority concepts in the text, independent of whether the query wants to include or exclude them. Cross-encoder models have the capacity to learn how negation should affect relevance judgments. Finally, cross-encoder scores are often better calibrated across a diverse range of query types and topics. This makes choosing a score at which to drop documents significantly more reliable.
Connection with RAG
Improving the content supplied to an LLM improves the quality of RAG. Indeed search quality is often the bottleneck for RAG performance. For example, if the information needed to respond correctly to a question is contained exclusively in a specific document, that document must be provided in the LLM context window. Furthermore, whilst the current generation of long context models are excellent at extracting information from long contexts, the cost to process the extra input tokens is significant and money spent on search typically yields large overall cost efficiencies. RAG use cases generally also have looser latency constraints, so some extra time spent in reranking is less of an issue. Indeed, the latency can also be offset by reducing the generation time if fewer passages need to be supplied in the prompt to achieve the same recall. This makes semantic reranking especially well suited to be applied in RAG scenarios.
Wrapping Up
In this post we introduced the concept of semantic reranking and discussed how model architecture can be tailored to this use case to improve relevance, particularly in a zero shot setting. We discussed the performance trade-offs associated with semantic reranking as opposed to semantic retrieval. A crucial choice when discussing performance in this context is how many documents to rerank, which critically affects the trade-off between performance and relevance of reranking methods. We will pick up this topic again when we discuss how to evaluate reranking models and survey some state of the art open and closed reranking models.
In the second installment of this series, we introduce you to Elastic Rerank: Elastic's new semantic re-ranker model we've trained and released in technical preview.
Related Content

February 20, 2026
Ensuring semantic precision with minimum score
Improve semantic precision by employing minimum score thresholds. The article includes concrete examples for semantic and hybrid search.

February 17, 2026
An open‑source Hebrew analyzer for Elasticsearch lemmatization
An open-source Elasticsearch 9.x analyzer plugin that improves Hebrew search by lemmatizing tokens in the analysis chain for better recall across Hebrew morphology.
January 30, 2026
Query rewriting strategies for LLMs and search engines to improve results
Exploring query rewriting strategies and explaining how to use the LLM's output to boost the original query's results and maximize search relevance and recall.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.

January 8, 2026
Hybrid search and multistage retrieval in ES|QL
Explore the multistage retrieval capabilities of ES|QL, using FORK and FUSE commands to integrate hybrid search with semantic reranking and native LLM completions.