Free yourself from operations with Elastic Cloud Serverless. Scale automatically, handle load spikes, and focus on building—start a 14-day free trial to test it out yourself!
You can follow these guides to build an AI-Powered search experience or search across business systems and software.
Elasticsearch Serverless is now generally available. We’ve re-architected Elastisearch as a fully managed service that autoscales with your data, usage, and performance needs. It has the power and flexibility of Elasticsearch without operational overhead.
Since its technical preview this spring, we’ve introduced new capabilities to help developers build and manage applications faster. Whether you’re implementing semantic search, keyword search, or even image search, Elasticsearch Serverless simplifies the process, allowing you to focus on innovation instead of infrastructure.
Designed to eliminate the complexity of managing resources, Elasticsearch Serverless makes it easier to run search, RAG, and AI-powered applications while maintaining the speed, relevance, and versatility Elasticsearch is known for.
In this post, we’ll share how Elasticsearch Serverless simplifies building search applications with its modern architecture and developer-friendly features.
Elasticsearch is the backbone of search experience
Elasticsearch has long been the trusted engine for developers, data scientists, and full-stack engineers seeking high-performance, scalable search, and vector database capabilities. Its powerful relevance features and flexibility have made it the backbone for countless search-driven applications.
Elasticsearch’s innovations in query speed and vector quantization have positioned it as a leading vector database, supporting scalable AI-driven use cases like semantic and hybrid search.
Today, Elasticsearch continues to set the gold standard for search by combining:
- High speed and relevance for text search.
- Flexible query capabilities to tailor search workflows.
- Seamless handling of hybrid queries, combining vector and lexical search.
- An open-source core, rooted in Lucene, with continuous optimizations that push the boundaries of search technology.
As search use cases evolve—incorporating hybrid search, AI and inference, and dynamic workloads—teams have more options than ever for scaling and managing infrastructure to meet their unique needs. These evolving demands present an exciting opportunity to rethink how we design for scale.
Elasticsearch with serverless speed and simplicity
Elasticsearch Serverless builds on Elasticsearch’s strengths to address the demands of modern workloads, characterized by large datasets, AI search, and unpredictable traffic. Elasticsearch Serverless meets these challenges head-on with a reimagined architecture purpose-built for today’s demands.
Foundationally, Elasticsearch Serverless is built on a decoupled compute and storage model. This is an architectural change that removes the inefficiencies of repeated data transfers and leverages the reliability of object storage. From here, separating critical components enables independent scaling of indexing and search workloads, and resolves the long-standing challenges of balancing performance and cost-efficiency in high-demand scenarios.

Decoupled compute and storage
Elasticsearch Serverless uses object storage for reliable data storage and cost-efficient scalability. By eliminating the need for multiple replicas, indexing costs and data duplication are reduced. This approach ensures that storage is used only for what’s necessary, eliminating waste while maximizing efficiency.
To maintain Elasticsearch’s speed, segment-level query parallelization optimizes data retrieval from object stores like S3, while advanced caching strategies ensure fast access to frequently used data.
Dynamic autoscaling without compromise
The decoupled architecture also enables smarter resource management by separating search and ingest workloads, allowing them to scale independently based on specific demands. This separation ensures that:
- Concurrent updates and searches no longer compete for resources. CPU cycles, memory, and I/O are allocated independently, ensuring consistent performance even during high-ingest operations.
- Ingest-heavy use cases benefit from isolated compute. Ensure fast and reliable search performance, even while indexing massive volumes of data.
- Vector search workflows thrive. Decoupling allows for compute-intensive indexing (like embedding generation) without impacting query speeds.
Resources for ingest, search, and machine learning scale dynamically and independently to accommodate diverse workloads. There’s no need to overprovision for peak loads or worry about downtime during demand spikes.
Read more about our dynamic and load-based ingest and search autoscaling.
High-performance query execution
Elasticsearch Serverless enhances query execution by building on Elasticsearch’s strengths as a vector database. Innovations in query performance and vector quantization ensure fast and efficient search experiences for modern use cases. Highlights include:
- Faster data retrieval via segment-level query parallelization, enabling multiple concurrent requests to fetch data from object storage and significantly reducing latency to ensure faster access even when data isn't cached locally
- Smarter caching through intelligent query results reuse and optimized data structures in Lucene that allow for caching only the utilized portion of indexes,
- Tailored Lucene index structures maximize performance for various data formats, ensuring that each data type is stored and retrieved in the most efficient manner.
- Advanced vector quantization significantly reduces the storage footprint and retrieval latency of high-dimensional data, making AI and vector search more scalable and cost-effective.
This new architecture preserves Elasticsearch’s flexibility—supporting faceting, filtering, aggregations, and diverse data types—while simplifying operations and accelerating performance for modern search needs. For teams seeking a hands-off solution that adapts to changing needs, Elasticsearch Serverless offers all the power and versatility of Elasticsearch without the operational overhead.
Whether you're a developer looking to integrate hybrid search, a data scientist working with high-cardinality datasets, or a full-stack engineer optimizing relevance with AI models, Elasticsearch Serverless empowers you to focus on delivering exceptional search experiences.
Access to the newest search and AI features in Elasticsearch Serverless
Elasticsearch Serverless is more than just a managed service—it’s a platform designed to accelerate development and optimize search experiences. It’s where you can access the latest search and generative AI features:
- Elastic AI Assistant: Quickly access documentation, guidance, and resources to simplify prototyping and implementation.
- ELSER Embedding Model: Enable semantic or hybrid search capabilities, opening new ways to query your data.
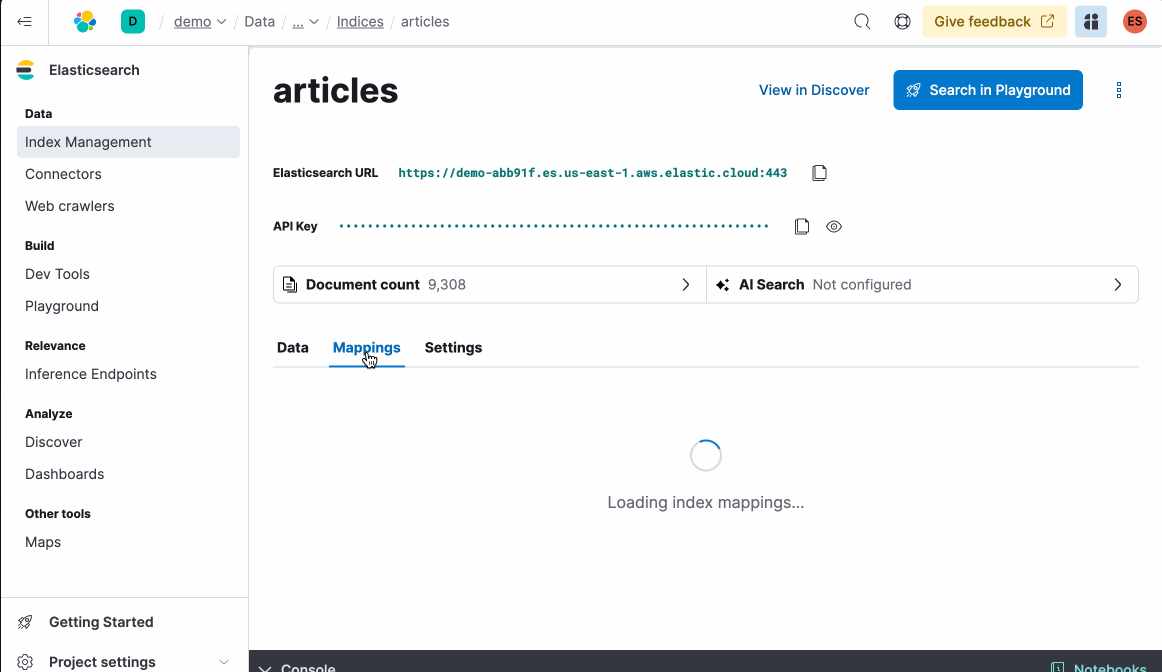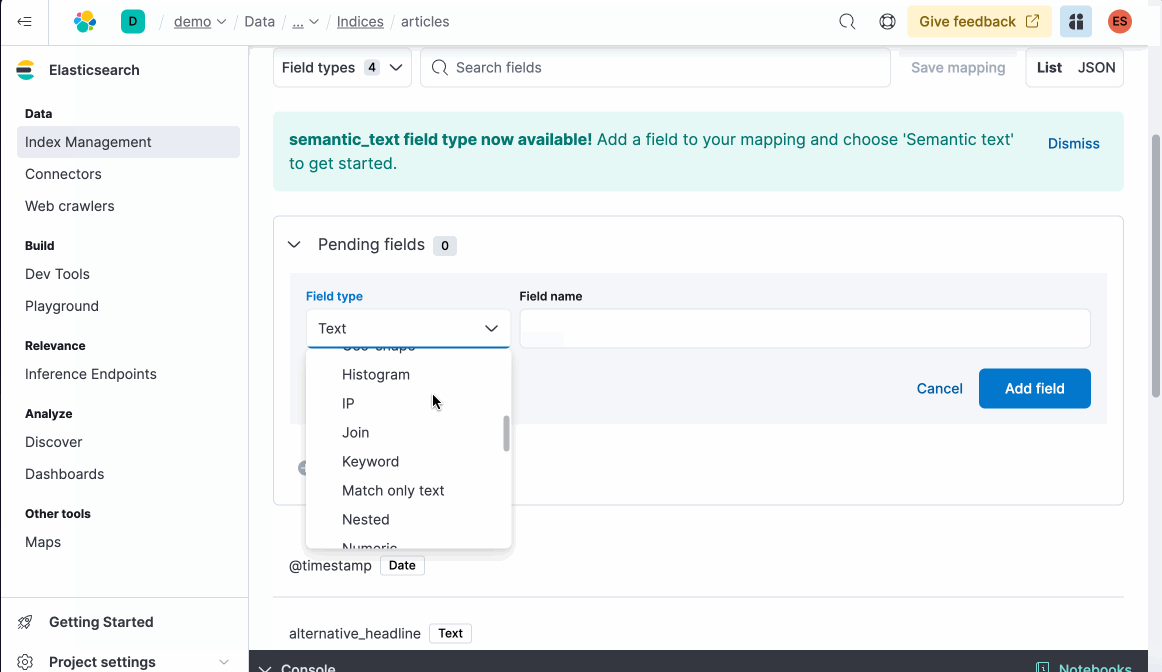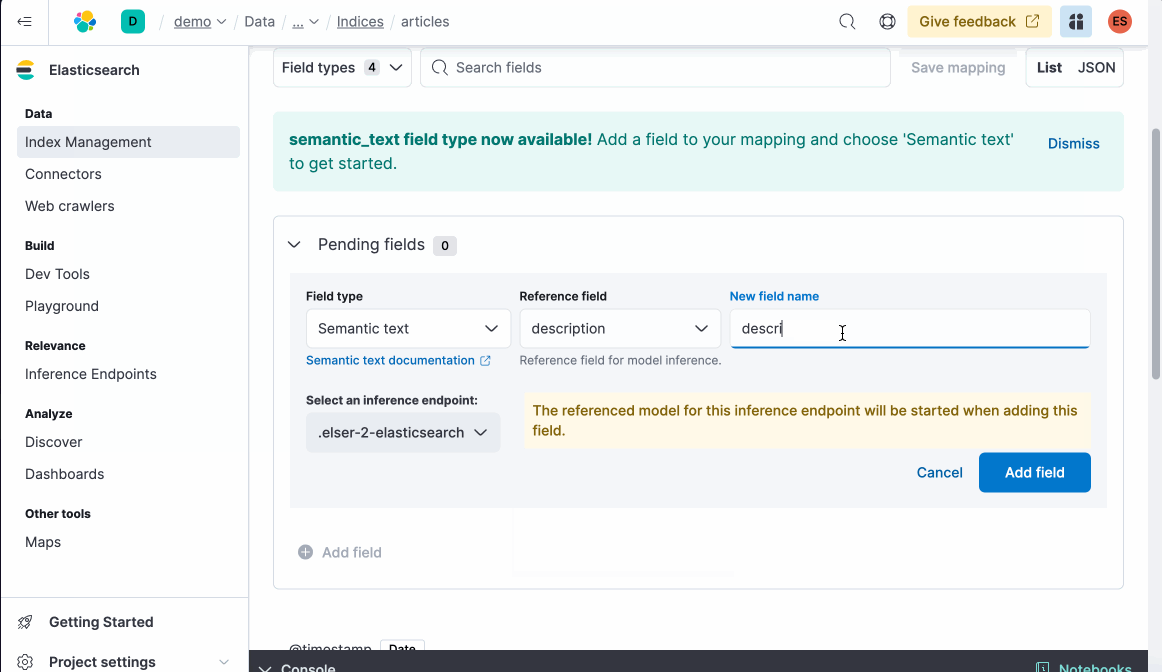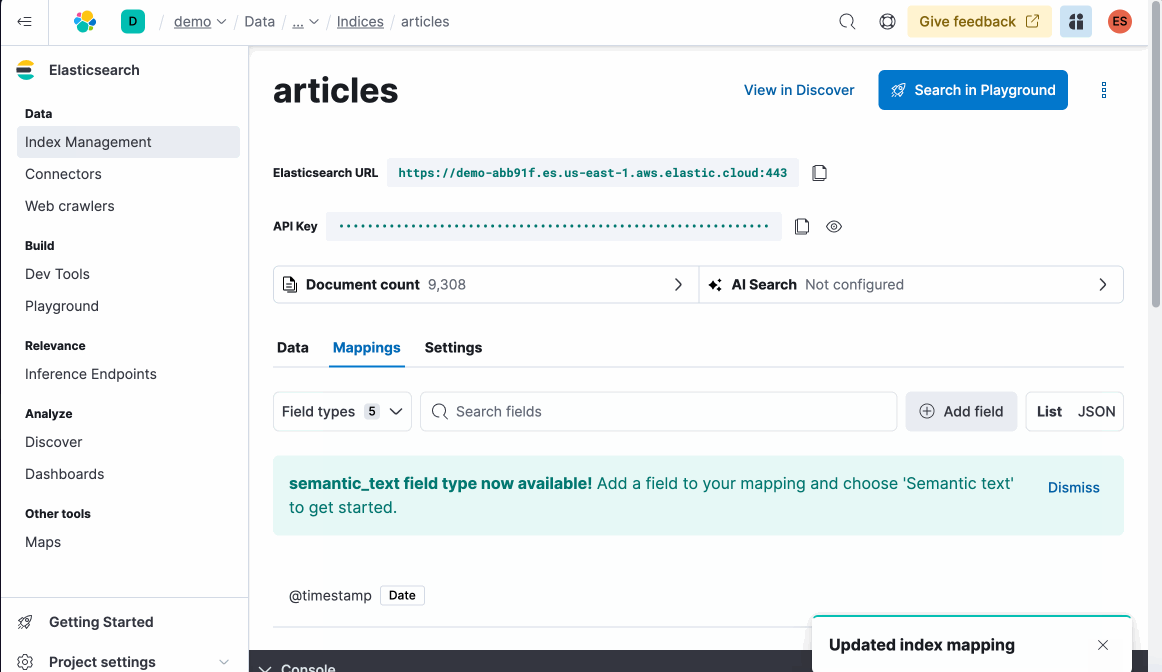
- Semantic Text Field Type: Generate vectors for text fields with ease.
- Better Binary Quantization (BBQ): Optimize vector storage and memory usage without compromising accuracy or performance.
- Elastic Rerank and Reciprocal Rank Fusion (RRF): Improve result relevance with simplified reranking and hybrid scoring capabilities.
- Playground and Developer Console: Experiment with new features, including Gen AI integrations, using a unified interface and API workflows.
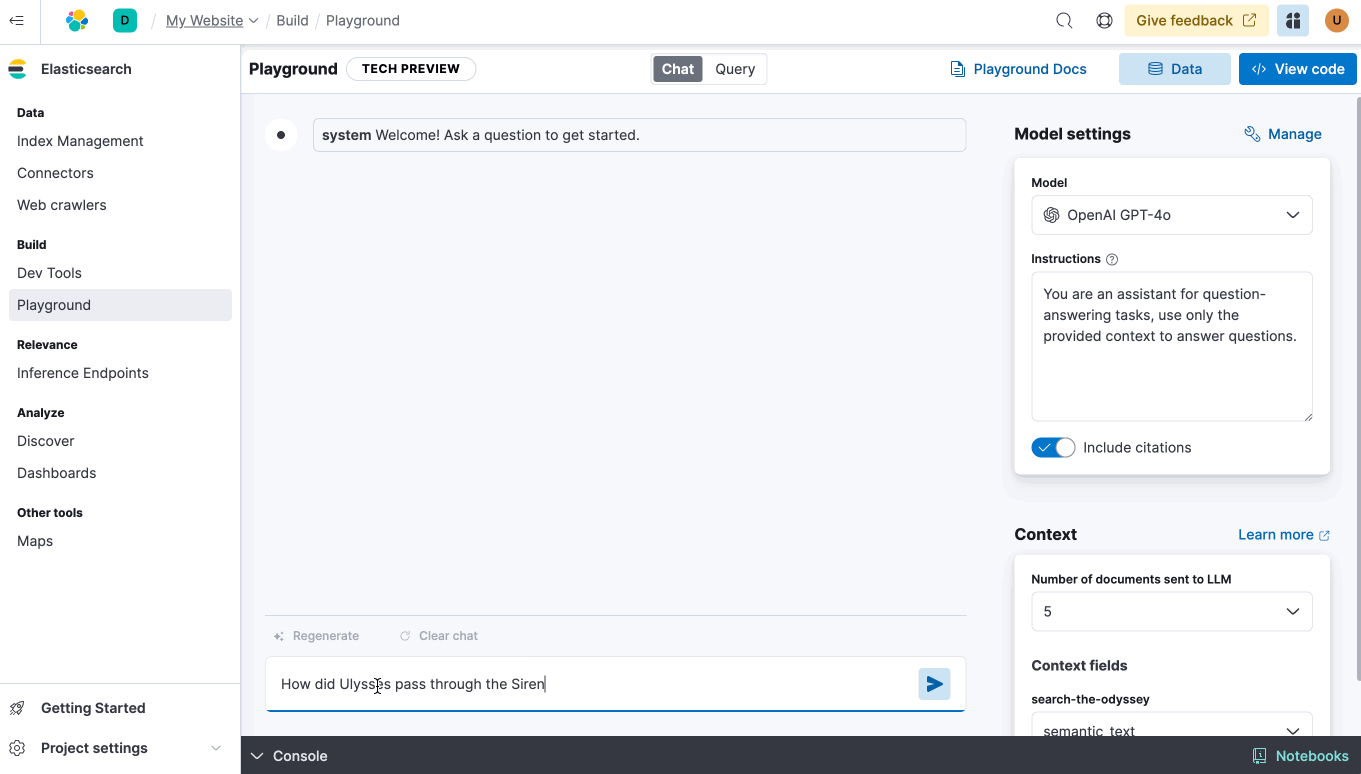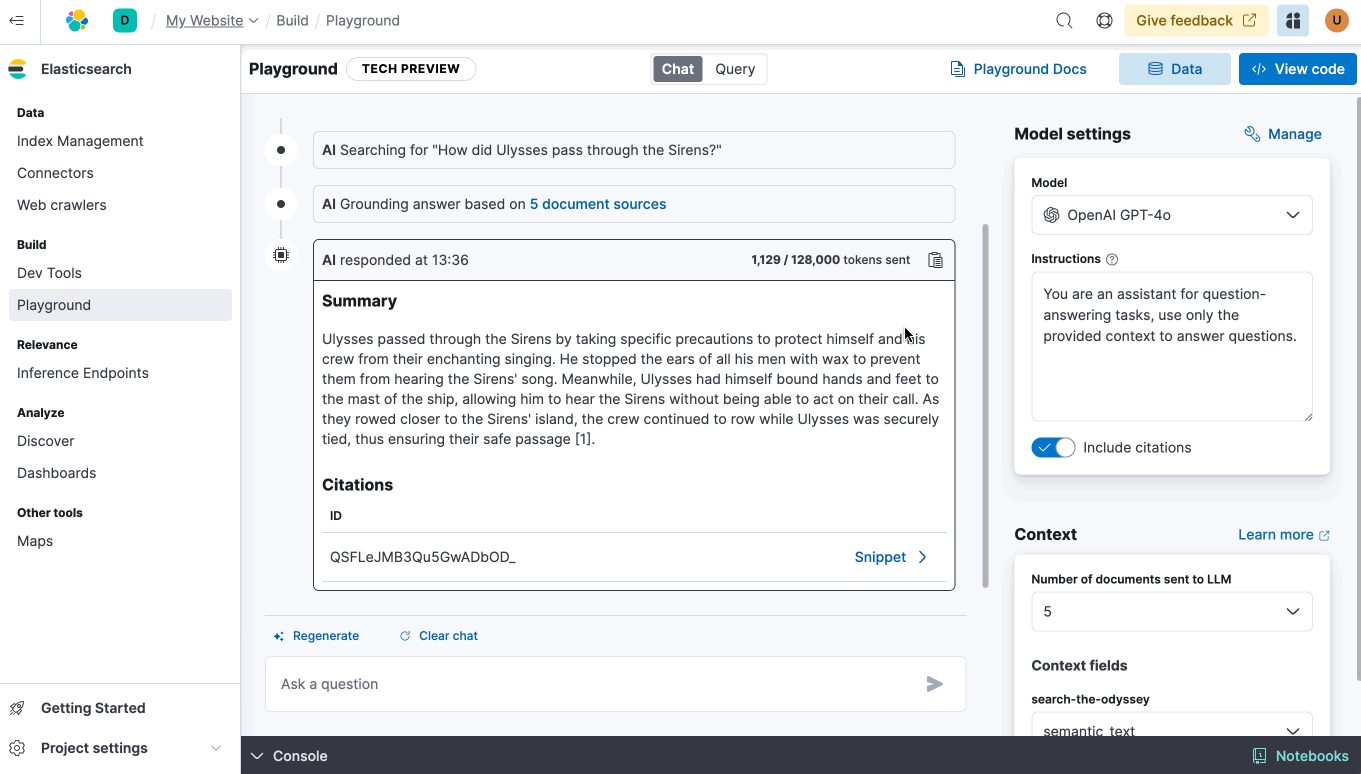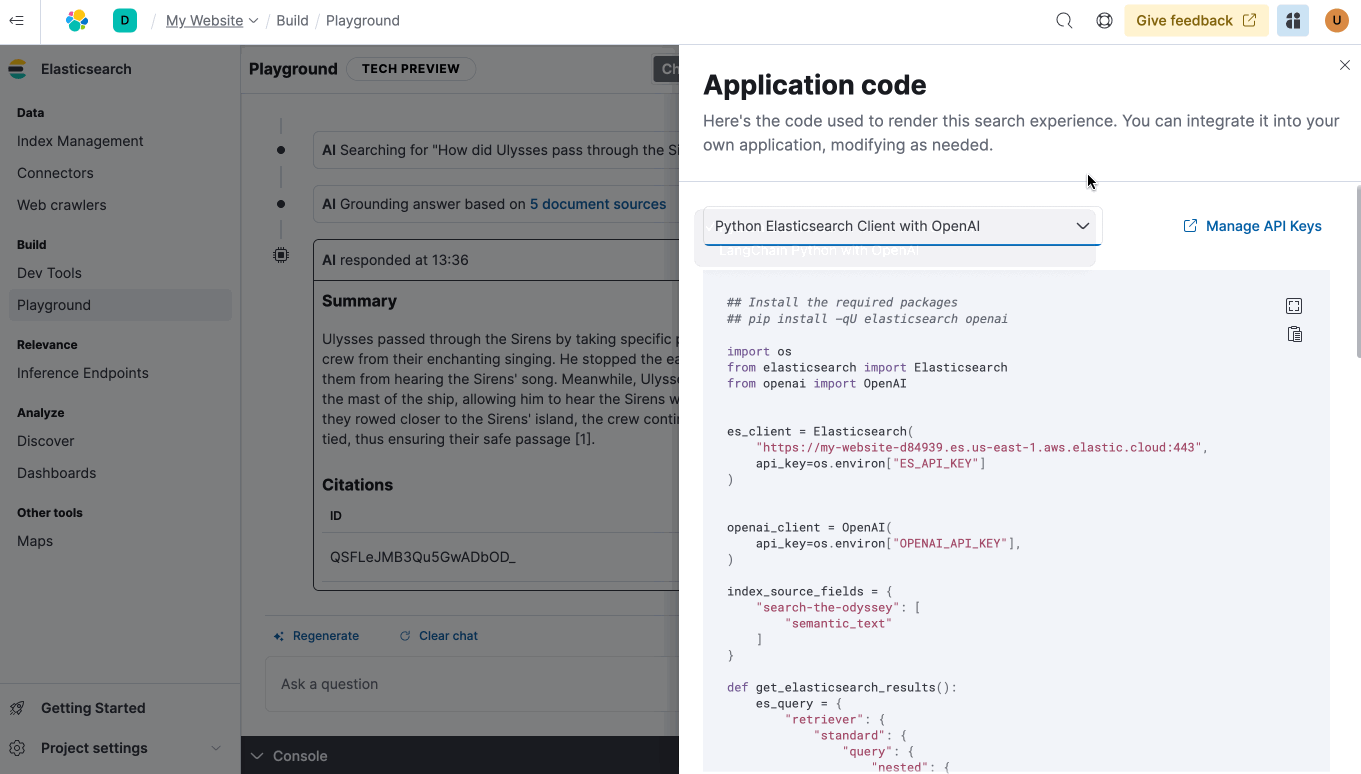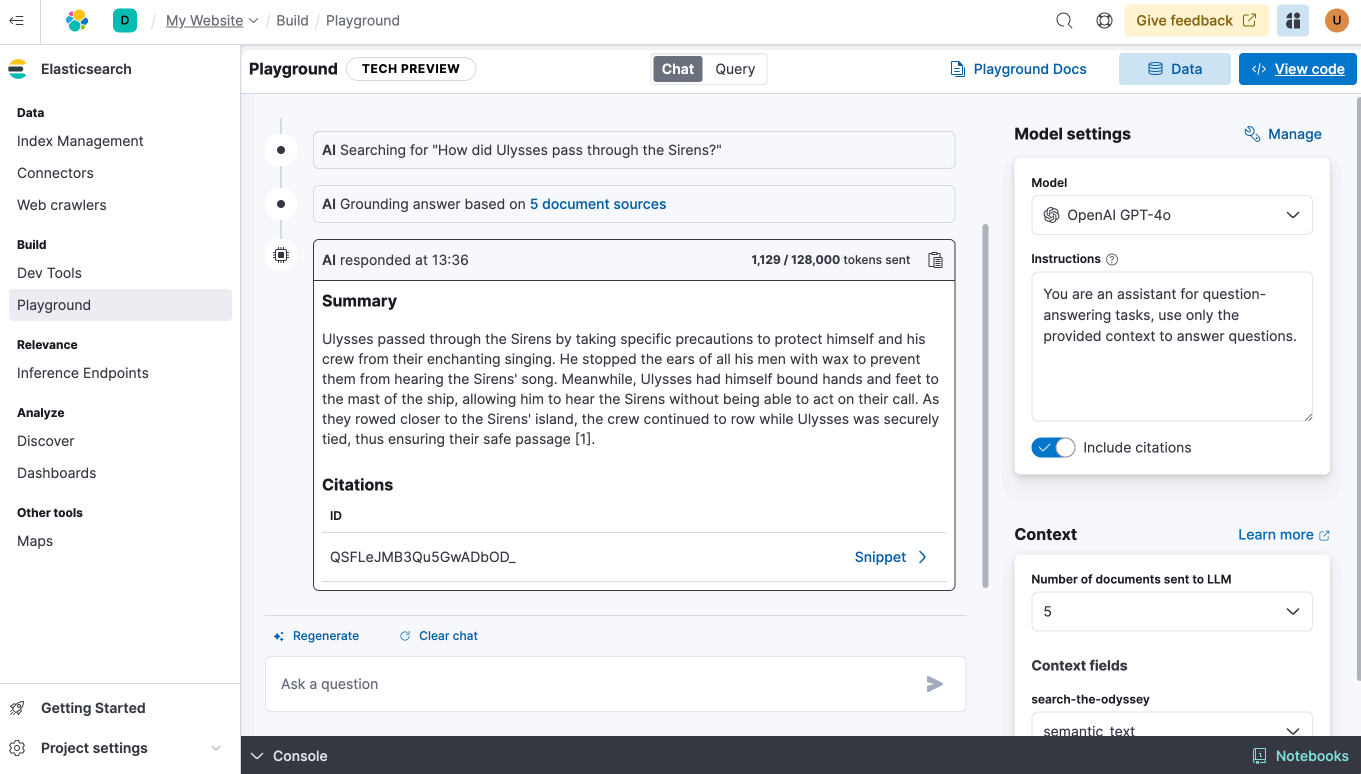
- ES|QL, Elastic’s intuitive command language, fully compatible with Elasticsearch Serverless.
- Usage and Performance Transparency: Manage search speed and costs through the Cloud console with detailed performance insights.
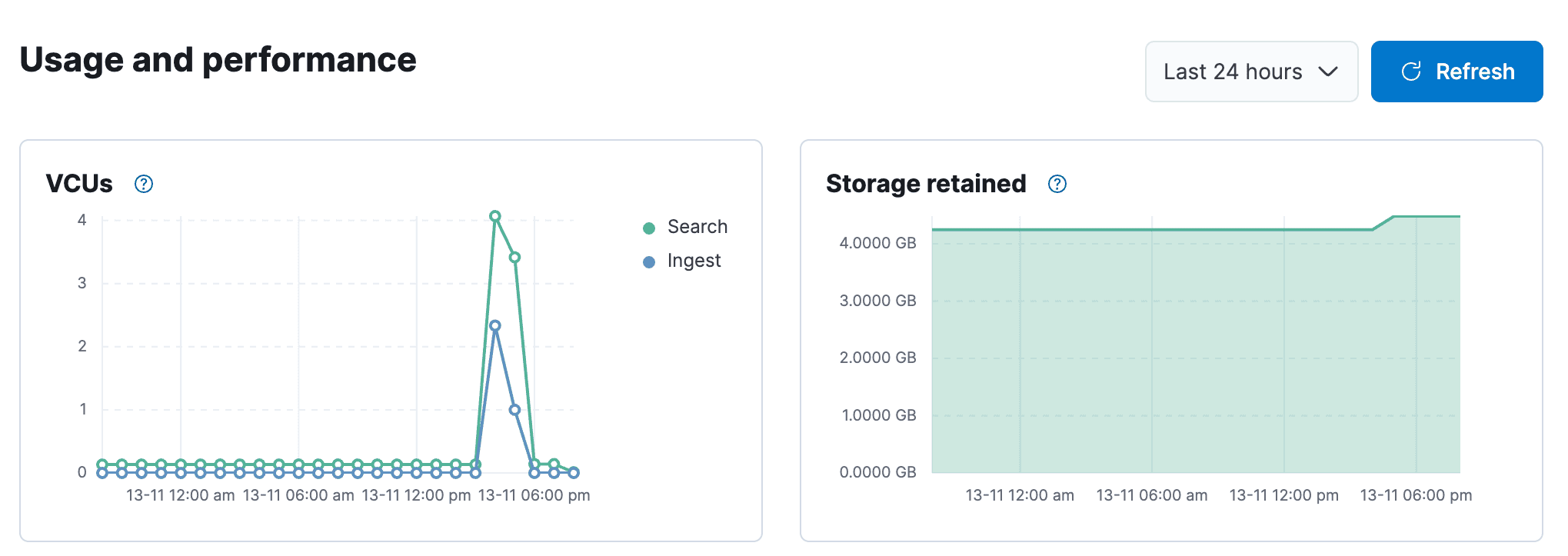
Get started with Elasticsearch Serverless
Ready to start building? Elasticsearch Serverless is available now, and you can try it today with our free trial.
Developers love Elasticsearch for its speed, relevance, and flexibility. With Elasticsearch Serverless, you’ll love it for its simplicity.
Explore Elasticsearch Serverless today and experience search, reimagined. Learn about serverless pricing.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Frequently Asked Questions
Is Elasticsearch Serverless is generally available?
Yes, Elasticsearch Serverless is now generally available and you can try it today with our free trial.
Related Content
January 22, 2026
Agent Builder now GA: Ship context-driven agents in minutes
Agent Builder is now GA. Learn how it allows you to quickly develop context-driven AI agents.

January 14, 2026
Higher throughput and lower latency: Elastic Cloud Serverless on AWS gets a significant performance boost
We've upgraded the AWS infrastructure for Elasticsearch Serverless to newer, faster hardware. Learn how this massive performance boost delivers faster queries, better scaling, and lower costs.

March 4, 2025
The AI Agent to manage Elasticsearch Serverless projects
A natural language-powered AI agent that effortlessly manages Elasticsearch Serverless projects—enabling project creation, deletion, and status checks.

December 10, 2024
Autosharding of data streams in Elasticsearch Serverless
In Elastic Cloud Serverless we spare our users from the need to fiddle with sharding by automatically configuring the optimal number of shards for data streams based on the indexing load.

December 2, 2024
Elastic Cloud Serverless: A deep dive into autoscaling and performance stress testing at scale
Dive into how Elasticsearch Cloud Serverless dynamically scales to handle massive data volumes and complex queries. We explore its performance under real-world conditions and the results from extensive stress testing.