From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
We in the Elastic Engineering org have been busy optimizing vector database performance for a while now. Our mission: making Lucene and Elasticsearch the best vector database. Through hardware accelerated CPU SIMD instructions, introducing new vector data compression innovations (Better Binary Quantization a.k.a BBQ), and then exceeding expectations by updating the algorithmic approach to BBQ for even more benefits, and also making Filtered HNSW faster. You get the gist—we’re building a faster, better, efficient(er?) vector database for the developers as they solve those RAG-gedy problems!
As part of our mission to leave no efficiencies behind, we are exploring acceleration opportunities with these curious computer chips, which you may have heard of—NVIDIA GPUs! (Seriously, have you not?).
When obsessing over performance, we have several problem spaces to explore—how to index exponentially more data, how to retrieve insights from it, and how to do it when your ML models are involved. You should be able to eke out every last benefit available when you have GPUs.
In this post, we dive into our collaboration with the NVIDIA vector search team as we explore GPU-accelerated vector search in Elasticsearch. This work paves the way for use cases where developers could use a mix of GPUs and CPUs for real-world Elasticsearch-powered apps. Exciting times!
Elasticsearch GPUs
We are excited to share that the Elasticsearch engineering team is helping build the open-source cuVS Java API experience for developers, which exposes bindings for vector search algorithms. This work leverages our previous experience with Panama FFI. Elasticsearch and Apache Lucene use the NVIDIA cuVS API to build the graph during indexing. Okay, we are jumping ahead; let’s rewind a bit.
NVIDIA cuVS, an open-source C++ library, is at the heart of this collaboration. It aims to bring GPU acceleration to vector search by providing higher throughput, lower latency, and faster index build times. But Elasticsearch and Apache Lucene are written in Java; how will this work?
Enter lucene-cuvs and the Elastic-NVIDIA-SearchScale collaboration to bring it into the Lucene ecosystem to explore GPU-accelerated vector search in Elasticsearch. In the recent NVIDIA cuVS 25.02 release, we added a Java API for cuVS. The new API is experimental and will continue to evolve, but it’s currently available for use. The question may arise: aren’t Java to native function calls slow? Not anymore! We’re using the new Panama FFI (Foreign Function Interface) for the bindings, which has minimal overhead for Java to native downcalls.
We’ve been using Panama FFI in Elasticsearch and Lucene for a while now. It’s awesome! But... there is always a “but”, isn’t there? FFI has availability challenges across Java versions. We overcame this by compiling the cuVS API to Java 21 and encapsulating the implementation within a multi-release jar targeting Java 22. This allows the use of cuVS Java directly in Lucene and Elasticsearch.
Ok, now that we have the cuVS Java API, what else would we need?
A tale of two algorithms for CPU
Elasticsearch supports the HNSW algorithm for scalable approximate KNN search. However, to get the most out of the GPU, we use a different algorithm, CAGRA [CUDA ANN GRAph], which has been specifically designed for the high levels of parallelism offered by the GPU.
Before we get into how we look to add support for CAGRA, let’s look at how Elasticsearch and Lucene access index data through a “codec format”. This consists of
- the on-disk representation,
- the interfaces for reading and writing data,
- and the machinery for dealing with Lucene’s segment-based architecture.
We are implementing a new KNN (k-nearest neighbors) vector format that internally uses the cuVS Java API to index and search on the GPU. From here, we “plumb” this codec type through Elasticsearch’s mappings to a field type in the index. As a result, your existing KNN queries continue to work regardless of whether the backing index is using a CAGRA or HNSW graph. Of course, this glosses over many details, which we plan to cover in a future blog. The following is the high-level architecture for a GPU-accelerated Elasticsearch.
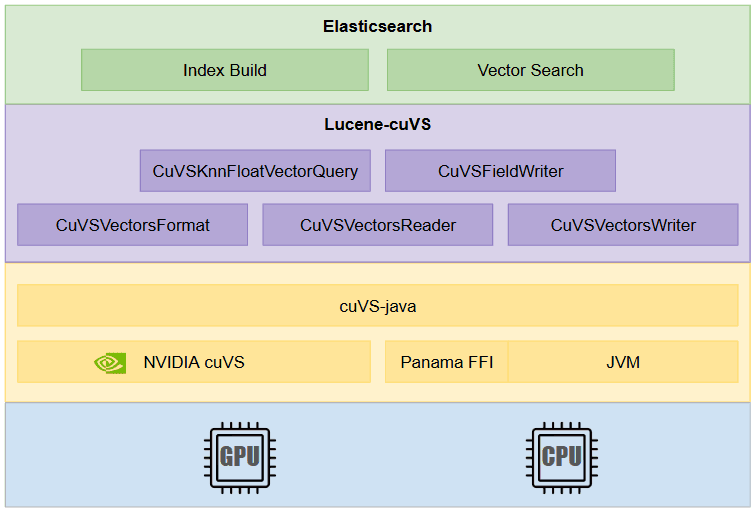
This new codec format defaults to CAGRA. However, it also supports converting a CAGRA graph to an HNSW graph for search on the CPU.
Indexing and searching on the GPU: Making some “core” decisions
With the stateless architecture for Elasticsearch Serverless, which separates indexing and search, there is now a clear delineation of responsibilities. We pick the best hardware profile to fulfill each of these independent responsibilities.
We anticipate users to consider two main deployment strategies:
- Index and search on the GPU: During indexing, build a CAGRA graph and use it during search - ideal when extremely low latency search is required.
- Index on GPU and search on CPU: During indexing, build a CAGRA graph and convert it to an HNSW graph. The HNSW graph is stored in the index, which can later be used on the CPU for searching.
This flexibility provides different deployment models, offering tradeoffs between cost and performance. For example, an indexing service could use GPU to efficiently build and merge graphs in a timely manner while using a lower-powered CPU for searching.
So here is the plan for GPU-accelerated vector search in Elasticsearch
We are looking forward to bringing performance gains and flexibility with deployment strategies to users, offering various knobs to balance cost and performance. Here is the NVIDIA GTC 2025 session where this work was presented in detail.
We’d like to thank the engineering teams at NVIDIA and SearchScale for their fantastic collaboration. In an upcoming blog, we will explore the implementation details and performance analysis in greater depth. Hold on to your curiosity hats 🎩!
Related Content

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.

February 5, 2026
ES|QL dense vector search support
Using ES|QL for vector search on your dense_vector data.

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.