Seamlessly connect with leading AI and machine learning platforms. Start a free cloud trial to explore Elastic’s gen AI capabilities or try it on your machine now.
It is well known that modern transformer based approaches to information retrieval often come with significantly higher resource costs when compared with traditional statistical approaches, such as BM25. This can make it challenging to apply these techniques in production. At large scale, at least as much attention needs to be paid to the resource usage of any retrieval solution as to its relevance in order to produce something practically useful.
In this final two part blog of our series, we discuss some of the work we did for retrieval and inference performance for the release of version 2 of our Elastic Learned Sparse EncodeR model (ELSER), which we introduced in this previous blog post. In 8.11 we are releasing two versions of the model: one portable version which will run on any hardware and one version which is optimized for the x86 family of architectures. We're still making the deployment process easy though, by defaulting to the most appropriate model for your cluster's hardware.
In this first part we focus on inference performance. In the second part we discuss the ongoing work we're doing to improve retrieval performance. However, first we briefly review the relevance we achieve for BEIR with ELSER v2.
Improved relevance for BEIR with ELSER v2
For this release we extended our training data, including around 390k high quality question and answer pairs to our fine tune dataset, and improved the FLOPS regularizer based on insights we discussed in the past. Together these changes gave us a bump in relevance measured with our usual set of BEIR benchmark datasets.
We plan to follow up with a full description of our training data set composition and the innovations we have introduced, such as improvements to cross-encoder distillation and the FLOPS regularizer at a later date. Since this blog post mainly focuses on performance considerations, we simply give the new NDCG@10 for ELSER v2 model in the table below.

NDCG@10 for BEIR data sets for ELSER v1 and v2 (higher is better). The v2 results use the query pruning method described below
Quantization in ELSER v2
Model inference in the Elastic Stack is run on CPUs. There are two principal factors which affect the latency of transformer model inference: the memory bandwidth needed to load the model weights and the number of arithmetic operations it needs to perform.
ELSER v2 was trained from a BERT base checkpoint. This has just over 100M parameters, which amounts to about 418 MB of storage for the weights using 32 bit floating point precision. For production workloads for our cloud deployments we run inference on Intel Cascade Lake processors. A typical midsize machine would have L1 data, L2 and L3 cache sizes of around 64 KiB, 2 MiB and 33 MiB, respectively. This is clearly much smaller than model weight storage (although the number of weights which are actually used for any given inference is a function of text length). So for a single inference call we get cache misses all the way up to RAM. Halving the weight memory means we halve the memory bandwidth we need to serve an inference call.
Modern processors support wide registers which let one perform the same arithmetic operations in parallel on several pieces of data, so called SIMD instructions. The number of parallel operations one can perform is a function of the size of each piece of data. For example, Intel processors allow one to perform 8 bit integer multiplication in 16 bit wide lanes. This means one gets roughly twice as many operations per cycle for int8 versus float32 multiplication and this is the dominant compute cost in an inference call.
It is therefore clear if one were able to perform inference using int8 tensors there are significant performance improvements available. The process of achieving this is called quantization. The basic idea is very simple: clip outliers, scale the resulting numbers into the range 0 to 255 and snap them to the nearest integer. Formally, a floating point number is transformed using . One might imagine that the accuracy lost in this process would significantly reduce the model accuracy. In practice, large transformer model accuracy is fairly resilient to the errors this process introduces.
There is quite a lot of prior art on model quantization. We do not plan to survey the topic in this blog and will focus instead on the approaches we actually used. For background and insights into quantization we recommend these two papers.
For ELSER v2 we decided to use dynamic quantization of the linear layers. By default this uses per tensor symmetric quantization of activations and weights. Unpacking this, it rescales values to lie in an interval that is symmetric around zero - which makes the conversion slightly more compute efficient - before snapping. Furthermore, it uses one such interval for each tensor. With dynamic quantization the interval for each activation tensor is computed on-the-fly from their maximum absolute value. Since we want our model to perform well in a zero-shot setting, this has the advantage that we don't suffer from any mismatch in the data used to calibrate the model quantization and the corpus where it is used for retrieval.
The maximum absolute weight for each tensor is known in advance, so these can be quantized upfront and stored in int8 format. Furthermore, we note that attention is itself built out of linear layers. Therefore, if the matrix multiplications in linear layers are quantized the majority of the arithmetic operations in the model are performed in int8.
Our first attempt at applying dynamic quantization to every linear layer failed: it resulted in up to 20% loss in NDCG@10 for some of our BEIR benchmark data sets. In such cases, it is always worthwhile investigating hybrid quantization schemes. Specifically, one often finds that certain layers introduce disproportionately large errors when converted to int8. Typically, in such cases one performs layer by layer sensitivity analysis and greedily selects the layers to quantize while the model meets accuracy requirements.
There are many configurable parameters for quantization which relate to exact details of how intervals are constructed and how they are scoped. We found it was sufficient to choose between three approaches for each linear layer for ELSER v2:
- Symmetric per tensor quantization,
- Symmetric per channel quantization and
- Float32 precision.
There are a variety of tools which can allow one to observe tensor characteristics which are likely to create problems for quantization. However, ultimately what one always cares about is the model accuracy on the task it performs. In our case, we wanted to know how well the quantized model preserves the text representation we use for retrieval, specifically, the document scores. To this end, we quantized each layer in isolation and calculated the score MAPE of a diverse collection of query relevant document pairs. Since this had to be done on CPU and separately for every linear layer we limited this set to a few hundred examples. The figure below shows the performance and error characteristics for each layer; each point shows the percentage speed up in inference (x-axis) and the score MAPE (y-axis) as a result of quantizing just one layer. We run two experiments per layer: per tensor and per channel quantization.
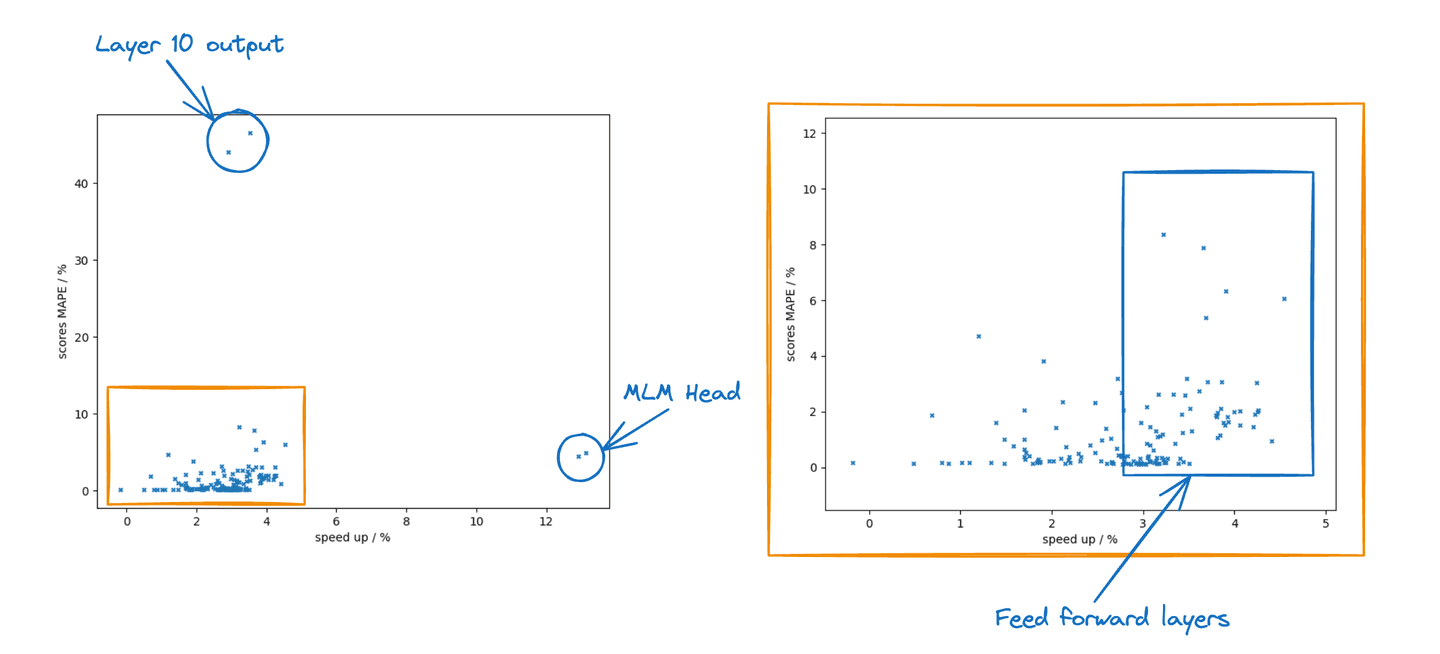
Relevance scores MAPE for layerwise quantization of ELSER v2
Note that the performance gain is not equal for all layers. The feed forward layers that separate attention blocks use larger intermediate representations so we typically gain more by quantizing their weights. The MLM head computes vocabulary token activations. Its output dimension is the vocabulary size or 30522. This is the outlier on the performance axis; quantizing this layer alone increases throughput by nearly 13%.
Regarding accuracy, we see that quantizing the output of the 10
th feed forward module in the attention stack has a dramatic impact and many layers have almost no impact on the scores (< 0.5% MAPE). Interestingly, we also found that the MAPE is larger when quantizing higher feed forward layers. This is consistent with the fact that dropping feed forward layers altogether at the bottom of the attention stack has recently been found to be an effective performance accuracy trade off for BERT. In the end, we chose to disable quantization for around 20% of layers and use per channel quantization for around 15% of layers. This gave us a 0.1% reduction in average NDCG@10 across the BEIR suite and a 2.5% reduction in the worst case.
So what does this yield in terms of performance improvements in the end? Firstly, the model size shrank by a little less than 40%, from 418 MB to 263MB. Secondly, inference sped up by between 40% and 100% depending on the text length. The figure below shows the inference latency on the left axis for the float32 and hybrid int8 model as a function of the input text length. This was calculated from 1000 different texts ranging for around 200 to 2200 characters (which typically translates to around the maximum sequence length of 512 tokens). For the short texts in this set we achieve a latency of around 50 ms or 20 inferences per second single threaded for an Intel Xeon CPU @ 2.80GH. Referring to the right axis, the speed-up for these short texts is a little over 100%. This is important because 200 characters is a long query so we expect similar improvements in query latency. We achieved a little under 50% throughput improvement for the data set as a whole.

Speed up per thread from hybrid int8 dynamic quantisation of ELSER v2 using an Intel Xeon CPU
Block layout of linear layers in ELSER v2
Another avenue we explored was using the Intel Extension for PyTorch (IPEX). Currently, we recommend our users run Elasticsearch inference nodes on Intel hardware and it makes sense to optimize the models we deploy to make best use of it.
As part of this project we rebuilt our inference process to use the IPEX backend. A nice side effect of this was that ELSER inference with float32 is 18% faster in 8.11 and we see increased throughput advantage from hyperthreading. However, the primary motivation was the latest Intel cores have hardware support for bfloat16 format, which makes better performance accuracy tradeoffs for inference than float32. We wanted to understand how this performs. We saw around 3 times speedup using bfloat16, but only with the latest hardware support; so until this is well enough supported in the cloud environment the use of bfloat16 models is impractical. We instead turned our attention to other features of IPEX.
The IPEX library provides several optimizations which can be applied to float32 layers. This is handy because, as discussed, we retain around 20% of the model in float32 precision.
Transformers don't afford simple layer folding opportunities, so the principal optimization is blocking of linear layers. Multi-dimensional arrays are usually stored flat to optimize cache use. Furthermore, to get the most out of SIMD instructions one ideally loads memory from contiguous blocks into the wide registers which implement them. The operations performed on the model weights in inference alter their access patterns. For any given compute graph one can in theory work out the weight layout which maximizes performance. The optimal arrangement also depends on the instruction set available and the memory bandwidth; usually this amounts to reordering weights into blocks for specific tensor dimensions. Fortunately, the IPEX library has implemented the optimal strategy for Intel hardware for a variety of layers, including linear layers.
The figure below shows the effect of applying optimal block layout for float32 linear layers in ELSER v2. The performance was averaged over 5 runs. The effect is small however we verified it is statistically significant (p-value < 0.05). Also, it is consistently slightly larger for longer sequences, so for our representative collection of 1000 texts it translated to a little under 1% increase in throughput.
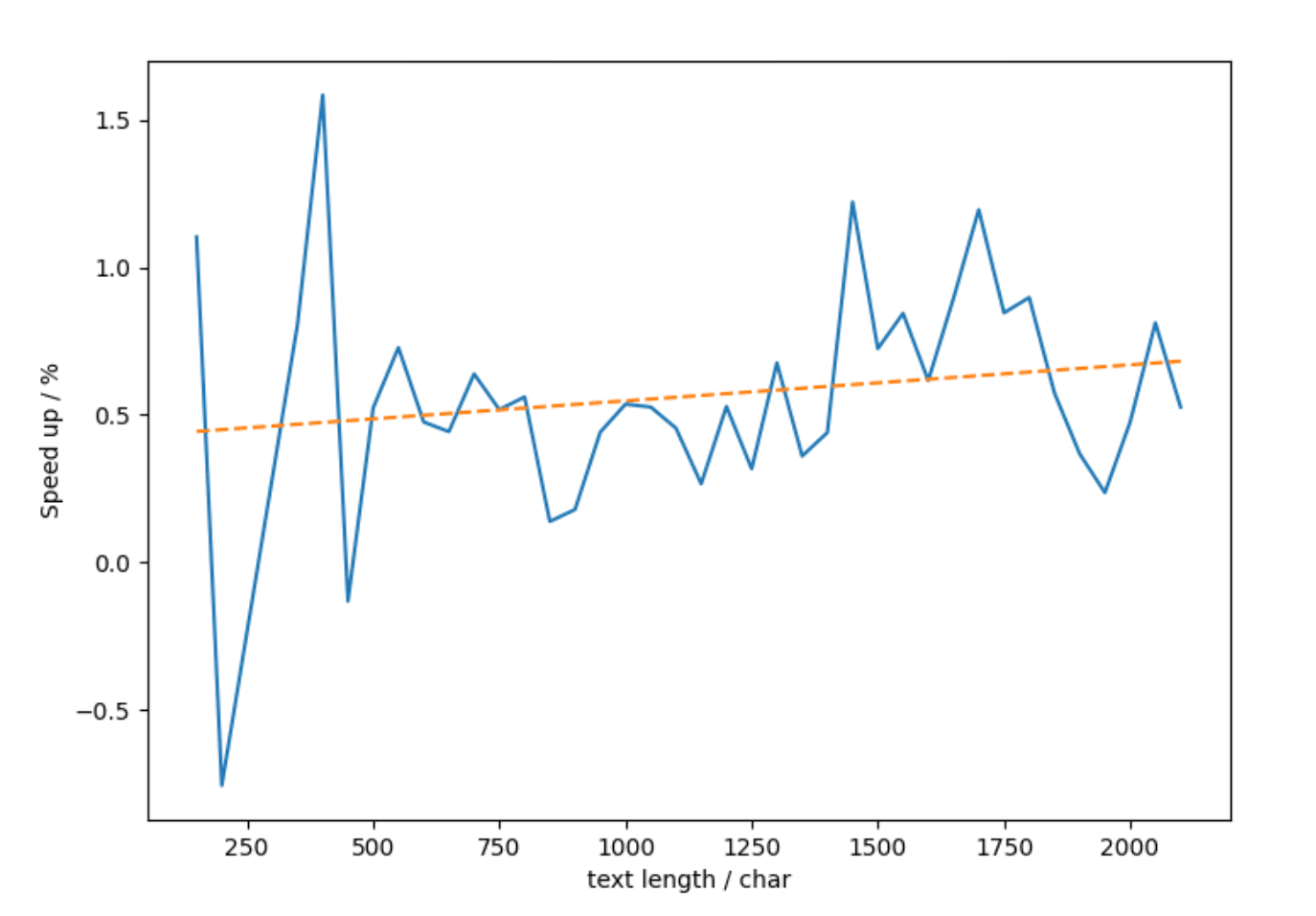
Speed up per thread from IPEX optimize on ELSER v2 using an Intel Xeon CPU
Another interesting observation we made is that the performance improvements are larger when using intra-op parallelism. We consistently achieved 2-5% throughput improvement across a range of text lengths using both our VM's allotted physical cores.
In the end, we decided not to enable these optimisations. The performance gains we get from them are small and they significantly increase the model memory: our script file increased from 263MB to 505MB. However, IPEX and particularly hardware support for bfloat16 yield significant improvements for inference performance on CPU. This work got us a step closer to enabling this for Elasticsearch inference in the future.
Conclusion
In this post, we discussed how we were able to achieve between a 60% and 120% speed-up in inference compared to ELSER v1 by upgrading the libtorch backend in 8.11 and optimizing for x86 architecture. This is all while improving zero-shot relevance. Inference performance is the critical factor in the time to index a corpus. It is also an important part of query latency. At the same time, the index performance is equally important for query latency, particularly at large scale. We discuss this in part 2.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Related Content

January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.

April 3, 2025
Generating filters and facets using ML
Exploring the pros and cons of automating the creation of filters and facets in a search experience using ML models vs the classical hard-coded approach.

February 5, 2025
Implementing clustering workflows in Elastic to enhance search relevance
We demonstrate how to integrate custom clustering models into the Elastic Stack by leveraging OpenAI text-ada-002 vectors, streamlining the workflow within Elastic’s ecosystem.

January 7, 2025
Early termination in HNSW for faster approximate KNN search
Learn how HNSW can be made faster for KNN search, using smart early termination strategies.

December 19, 2024
Understanding optimized scalar quantization
In this post, we explain a new form of scalar quantization we've developed at Elastic that achieves state-of-the-art accuracy for binary quantization.