In this section you are going to learn about a pattern derived from filters that is widely used in search implementations called faceted search. The idea is to let the user run a query, and then present them with a list of suggested filters along with the results.
The following screenshot shows a left sidebar with facets for the two filters that are currently implemented in the application.
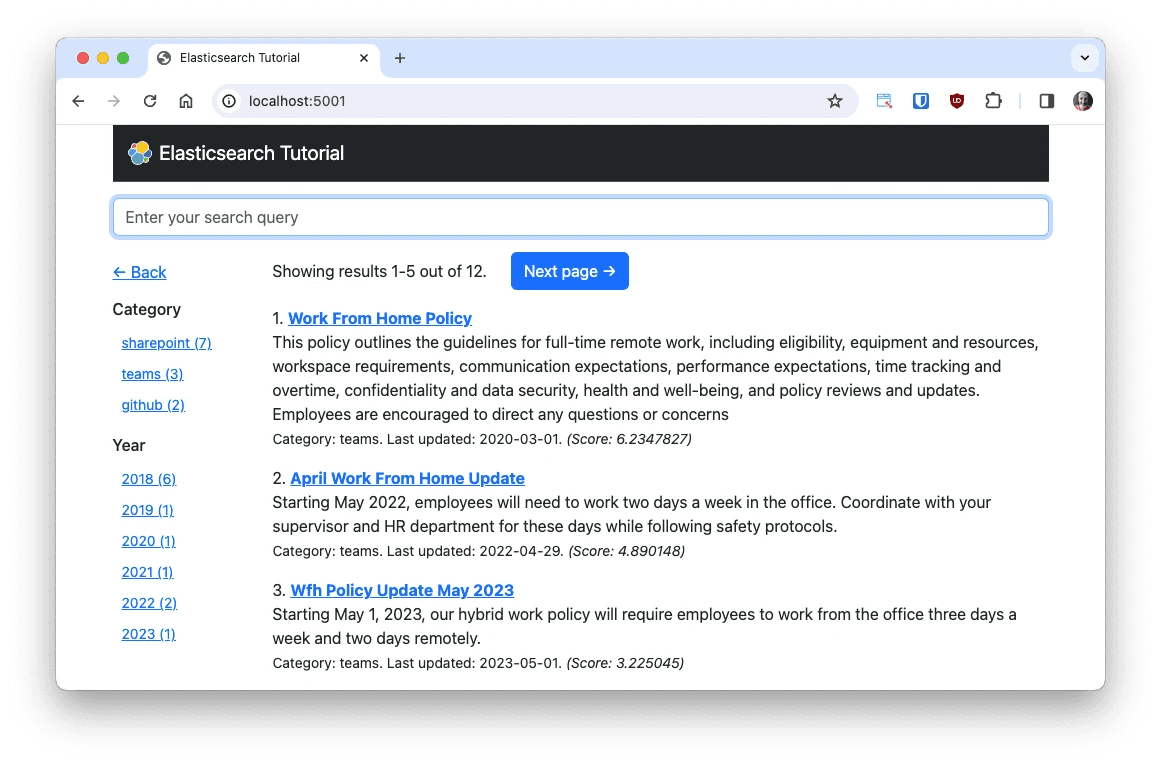
Here is a detail of the faceted search results. Note how each entry is rendered as a clickable link that adds the filter to the current search. Each face also reports how many results it includes.

Term Aggregations
In Elasticsearch faceted search is implemented using the aggregations feature. One of the supported aggregations divides the search results in buckets, based on some criteria. The list of buckets, each including the number of documents it contains, is going to be used to render the facets sidebar.
The simplest type of bucket aggregation is the one in which buckets are defined for each keyword. This type, which is called terms aggregation is perfect to create the buckets for the category field. Here is the search request from the application, expanded to ask for category aggregations:
The only change is the addition of the aggs option. Each aggregation is given a name, in this case category-agg. The terms aggregation indicates that filtering should be done by keyword. As with filters, the category field must be given as category.keyword, so that the keyword sub-type associated with the field is used.
The response to a request with aggregations has an aggregations field with the aggregated results. Here is what the response for the example request above might look like:
The index.html template that is included with the tutorial application is already designed to render aggregations in the left sidebar, which up until this point was empty. To keep the template logic simple, the data from the response above must be transformed into a dictionary with the following structure:
The next listing shows how to convert the Elasticsearch aggregation format to the above simplified dictionary, and also how to send the converted dictionary to the template for rendering:
In case you are curious, the index.html includes the following logic to render the aggs dictionary:
This implementation uses ideas that are similar to those used to render the next and previous pagination buttons. Each facet is rendered as a form with a hidden field that defines the query with the corresponding added filter. For example, a sharepoint category facet would add category:sharepoint to the current query.
As a merely cosmetic detail, the submit button in each facet is rendered in the style of a link.
Year Aggregations
The term aggregations used with the categories do not work for the year filter built in the previous section, because as you recall, the index does not store the years individually as keywords. Instead, the year each article was updated is defined by the updated_at field, which stores a full date.
From the long list of bucket aggregations that are available, the date histogram is the one that fits this use case the best. Here is the updated aggregations request:
Here you can see that a second aggregation was added to the aggs field. The type of this aggregation is date_histogram and the interval is set to year so that the buckets that are created each represents a year. The format option configures the format to use for the name of each bucket, which in this case should include just the year.
The aggregations field in the response is going to include two sections now:
There is another minor complication with this second aggregation. The key field that is included with each bucket is not useful, because for date interval aggregations it is in millisecond units. But luckily, the date rendered in the format given on the format option in the aggregation is provided in a key_as_string field.
Here is how the aggs dictionary including all the facets is calculated:
In addition to using key_as_string instead of key, for the year facets a conditional is added to eliminate any buckets that have zero documents in them, since obviously there is no point in using them as filters.
And with this, the faceted search implementation is complete. Here is the complete implementation of the handle_search() function:
The implementation of faceted search included in this tutorial has been designed with simplicity in mind. Aggregations in Elasticsearch have many possibilities that haven't been covered, so be sure to review the documentation to learn everything this feature has to offer.
Congratulations, you have reached the end of the Full-Text Search section of this tutorial! Click here to review the state of the tutorial search application up to this point.
Previously
FiltersNext
Vector Search