3 best practices for using and troubleshooting the Reindex API


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
When using Elasticsearch you may want to move data from one index to another, or even from one Elasticsearch cluster to another Elasticsearch cluster. There are multiple variations and features that could be used, and the Reindex API is one of them.
In this blog post, I will be discussing the reindex API, how to know if the API works, what can cause potential failures, and how to troubleshoot.
By the end of this blog post, you will understand the options the Reindex API has and how to run it confidently.
The reindex API is one of the most useful APIs across multiple use cases:
- Transferring data between clusters (Reindex from a remote cluster)
- Re-define, change, and/or update mappings
- Process and index through ingestion pipelines
- Clearing deleted documents to reclaim storage space
- Split large indices into smaller groups through query filters
When running the reindex API in medium or large indices it's possible that the full reindex will take more than 120 seconds, that means that you will not have the reindex API final response, you don't know when it finished, if it works, or if there were failures.
Let's take a look!
Symptom: In Kibana Dev tools, “Backend closed connection”
When you execute the reindex API with medium or large indices, the connection between the client and Elasticsearch will timeout, but that doesn't mean that the reindex will not be executed.
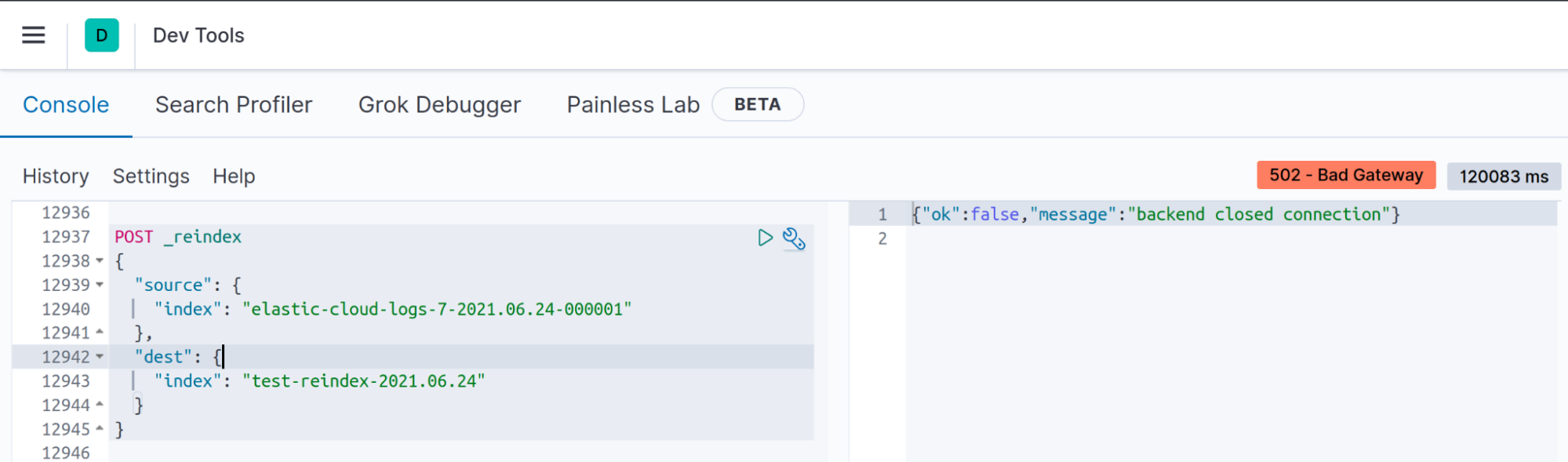
Problem
Your client will close inactive sockets after N seconds, in Kibana for example, if the reindex operation could not be finished in less than 120 seconds (default server.socketTimeout value in v7.13) you will see the "backend closed connection" message.
Solution #1 - get the list of task running on the cluster
This is not a real issue, even if you have this message in Kibana, Elasticsearch behind the scenes is running the reindex API.
You could follow the execution of the reindex API and see all the metrics with the _task API:
GET _tasks?actions=*reindex&wait_for_completion=false&detailedThis API will show you all the reindex API that are currently running in the Elasticsearch cluster, if you don't see your reindex API on this list, it means that it is already finished.

As you can see on the image, we have details about the documents created, updated or even the conflicts.
Solution #2 - Store the reindex result on _tasks
If you know that the reindex operation will take longer than 120 seconds (120 seconds is the Kibana dev tools timeout) you can store the reindex API results using the query parameter wait_for_completion= false, this will allow you to get the status at the end of the reindex API using the _task API (you can also get the document from the ".tasks" index, as explained in the documentation of the wait_for_completion=false).
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
When you execute the reindex with "wait_for_completion=false" the response will be something like:
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
You will need to keep the task provided here to search for the reindex results (you will see the number of documents created, conflicts or even errors, and when finished you will see the time that it took, number of batches… etc):
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906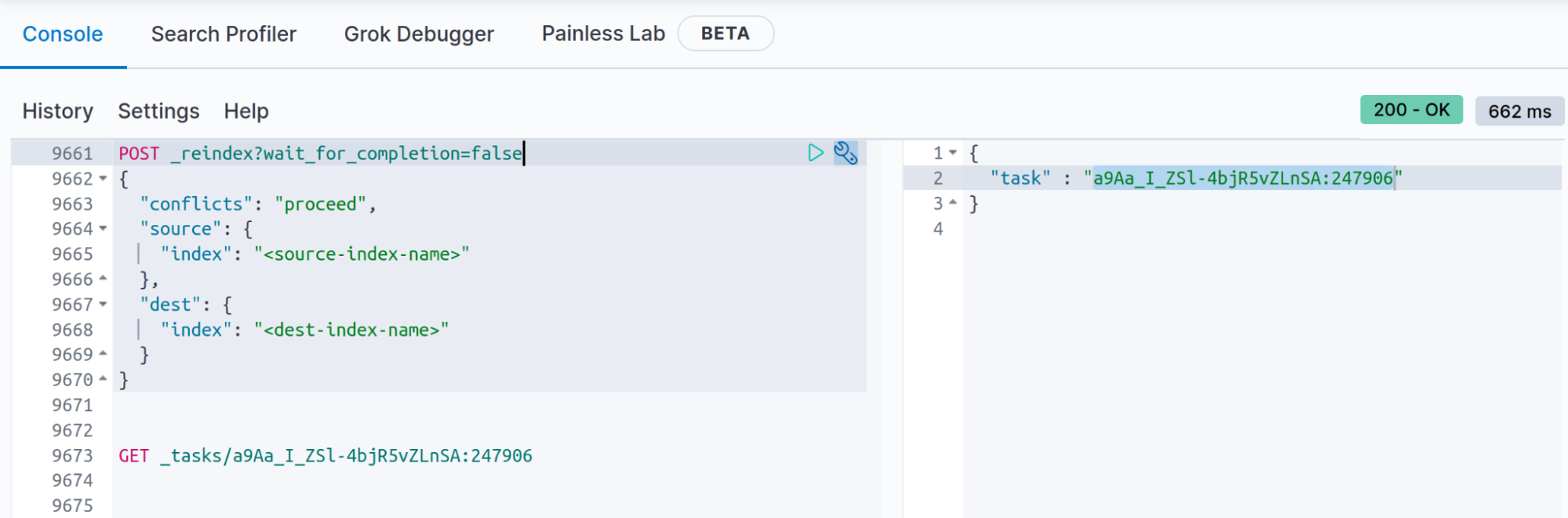
Symptom: Your reindex API is not in the _task API list.
If using the API mentioned above you can not find your reindex API operation, it could be different problems, we will go one by one.
Problem
If the reindex API is not listed it means that it finished because there were no more documents to reindex or because there was an error.
We will use the _cat count API to see the number of documents stored on both indices, if this number is not the same it means that somehow your reindex API execution failed.
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
You will need to replace <source-index-name> / <dest-index-name> by the index names you are using in your reindex API.
Solution #1 - It’s a conflict issue
One of the most frequent errors is that we have conflicts, by default the reindex API will abort if there is any of those.
Now we have two options:
- Set the setting "conflicts" to "proceed", that will allow the reindex API to ignore the documents that could not be indexed and index the others.
- Or we have the option to fix the conflicts so we can reindex all the documents.
The first option with the conflicts setting, will look like this:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Or in the second option, we will search and fix the errors that produce the conflict:
- The best practice that will allow you to avoid this issue is defining a mapping or template on the destination index. 99% of the time those errors are field types that don't match between the origin index and the destination.
- If even after defining the mapping or a template the problem remains, it means that some documents could not be indexed and the error will not be logged by default. We need to enable the logger to see the errors on the Elasticsearch logs.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- With the logger enabled, we need to execute the reindex API one more time, if possible use the setting "conflicts" to "proceed" as many times you have more than one field that has conflicts between the source and the destination index.
- Now that the reindex API is running, we will grep/search on the logs "failed to execute bulk item" or "MapperParsingException"
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
Or
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
With this stack trace we already have enough information to understand what the conflict is, in my reindex API the destination index has a field called [test-field] of type [long], and the reindex API try to set this field a string 'ABC' ('ABC' will be replaced by your own content field).
In Elasticsearch you can define field data types, you can set those during index creation or using templates. You can not change the types once the index is created you will need to delete the destination index first, then set the new fixed mapping with the options provided before.
- Once you have fixed your errors remember to move the logger to a less verbose mode:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
Solution #2 - You have no conflict errors, but the reindex continues failing
If during the reindex execution you find this trace in your Elasticsearch logs:
'search_phase_execution_exception', 'No search context found for id [....]')
It could be different reasons:
- The cluster has some instability issues and some data nodes were restarted or unavailable during the reindex execution.
If this is the reason, before running the reindex be sure your cluster is stable and that all the data nodes are working well. - If you are doing a reindex operation from remote, and you know that the network between the nodes is not reliable:
- The snapshots API is a great option (as described in the conclusion of this blog post).
- We can try to slice manually the reindex API, this operation will allow you to break the request process into smaller parts (this option is when we are using the reindex API within the same cluster).
If your Elasticsearch cluster has oversharding issues, high resource utilization, or garbage collection issues we could have timeouts during the scroll search query. The default scroll timeout value is 5 minutes, so you could try the scroll setting on the reindex API with a higher value.
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
Symptom: "Node not connected" in your Elasticsearch logs
We always advise to run the reindex API with a cluster stable and with a green status, and the cluster will need enough capacity to run search and index actions.
Problem
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
If you have this error in your logs it means that your cluster has stability and connectivity issues, and it's not only the reindex API that fails.
But let's imagine that you are aware about the connectivity issues, but you need to run the reindex API.
Solution
Fix the connectivity issues.
But let's imagine that we are aware of the connectivity issues, but you need to run the reindex API, we could reduce the possibilities of failing but this is not a fix and it will not work in all the different cases.
- Move the shards for the origin or destination index (primaries or replica) out of the nodes that have the connectivity issue. Use the allocation filtering API to move the shards.
- You could also remove the replicas on the destination index (only on the destination index) this will speed up the reindex API, and if the reindex runs faster the less likely to face a failure.
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
If both actions have not allowed you to get the reindex API to succeed you need to fix the stability issue first.
Symptom: No errors in logs, but the count of documents for both indices doesn’t match
Sometimes the reindex API is finished but the count of documents in the origin doesn’t match with the destination.
Problem
If we try to reindex from multiple sources in one destination (merge many indices in one), the problem could be the _id you have assigned for those documents.
Imagine we have 2 source indices:
- Index A, with _id: 1 and message:"Hello A"
- Index B, with _id: 1 and message:"Hello B"
The merge of both indices in C, it will be:
- Index C, with _id: 1 and message:"Hello B"
Both documents have the same _id, so the last document indexed it will just override the previous one.
Solution
You have different options as the ingest pipelines or use painless in your reindex API. For this blog post we will use the script option with “painless” on the request body.
It's really simple, we will just use the original _id and we will add the source index name:
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
And if we take our previous example:
- Index A, with _id: 1 and message:"Hello A"
- Index B, with _id: 1 and message:"Hello B"
The merge of both indices in C, it will be:
- Index C, with _id: 1-A and message:"Hello A"
- Index C, with _id: 1-B and message:"Hello B"
Conclusion
Reindex API is a great option when you need to change the format of some fields. Here we will list some key aspects that will make that the reindex API works as smoothly as possible:
- Create and define a mapping (or a template) for your destination index.
- Tune the destination index so the reindex API could index documents as fast as possible. We have a documentation page with all the options that will allow you to tune and speed up the indexation.
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - If the source index is medium or large in size, please define the setting "wait_for_completion=false" so the reindex API results will be stored on the _tasks API.
- Split your index in smaller groups, you can define different groups using a query (range, terms… etc) or break the request into smaller parts using the slicing feature.
- Stability is key when running the reindex API, the indices that are involved in the reindex API need to be in a green status (worst case scenario in yellow status), then be sure we don't have long GarbageCollections in data nodes, and that the CPU and disk usage has normal values.
Since v7.11, we have released a new feature that will allow you to avoid the need to reindex your data, and it's called "runtime fields". This API allows us to fix errors without the need to reindex the data, as you can define runtime fields in the index mapping or in the search request. Both options will allow you to have the flexibility to alter a document's schema after ingest and generate fields that exist only as part of the search query.
A great example of the runtime fields capabilities, is the ability to create a runtime field with the same name as a field that already exists in the mapping, the runtime field shadows the mapped field, to test it you need just to follow the steps provided here.
You can see more details about runtime fields in our documentation or in the getting started blog post.
When you are trying to move data from one cluster to another, you can use the snapshot-restore API. Using snapshots, you can move the data faster as the cluster doesn't need to search, then to reindex the data. You need to ensure that both clusters have access to the same snapshot repository, more details about the snapshot API.
We've covered reindex frequent questions, and common error solutions. At this point, if you're stuck resolving an issue, feel free to reach out. We're here and happy to help! You can contact us via Elastic Discuss, Elastic Community Slack, consulting, training, and support.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print