Analyzing a High-Tech Manufacturing Supply Chain with Social Network Theory
Imec is a world-leading nano-electronics research institute working on a broad variety of topics, ranging from advanced silicon chip technology to healthcare, solar cells, wireless communications and many other applications. The Imec Innovation Services and Solutions division is the semiconductor manufacturing division of Imec which helps innovators, entrepreneurs and universities realize their ideas in hardware and software by providing design and low-cost prototyping, volume production and system integration of silicon integrated circuits and electronic assemblies.
In our first blog, we defined the wide scope of the business and technology data that we have to store, process and analyze. The raw input data is mostly in the form of tabular financial datasets which are linked and extended using unstructured technology descriptions in a wide variety of formats. The heterogeneous nature of these data sources has directly impacted the architecture of the software infrastructure and analysis principles. We have used the Elastic Stack for our data processing and business analytics framework. On the one hand, this has enabled us to make the traditional analytics process more interactive leading to easily customizable dashboards. On the other hand this has enabled us to adopt less common analytics approaches such as graph-theoretic analysis of the linked data or the application of machine learning for time-based data analysis.
The Business Network Graph
Since then, we have developed a relatively unique usage of graph analysis for business network modeling using the Graph plug-in of the Elastic Stack. It deals with modeling and analysis of Imec Innovation Services and Solutions manufacturing and customer supply chain by visualizing it as a social network graph.
Here we draw on the rich literature which discuss the modeling and evaluation of popular social networks as undirected graphs, and from which we can profit from employing a wide variety of graph-theoretic parameters. One of the most intriguing graph-based parameters is known as the degree of separation. This is a measure of the average number of “hops” across a graph to connect two vertices. This measure has received a lot of attention since Facebook showed that average degree of separation among active Facebook users is approximately 3.5 and has been decreasing as the network has grown in size: a phenomenon which has been termed the “network effect”.
While perhaps not as dramatic as the growth experienced by Facebook, our manufacturing supply chain network has also experienced rapid growth. The work described in this blog was therefore initiated to see if the network effect could be used to explain our success. In contrast to a standard social network graph model with only one type of a node, a user, our business graph model recognizes three types of nodes. The first node type corresponds to customers, mostly universities, research institutes and SMEs (Small Medium Enterprises). The second type represents suppliers of manufacturing services, such as foundry-based manufacturing of silicon chips, chip packaging, testing, etc. The third type of node is a project node, created internally, to connect the manufacturing services providers to the customers.
Connections between nodes of our graph model therefore represent financial transactions and associated flows of costs and revenues. For example, an invoice sent to a customer forms a connection between a project node and a customer node. A purchase order sent by a supplier forms connection between a project node and a supplier node. The data on which we base these connections are mined from the SAP datasets covering the financial operations in question and are kept in an internal SQL-based data warehouse. As well as connections between customers and projects and suppliers and projects, connections between individual projects are established through customers or suppliers taking part in two or more common projects, and thereby creating a rich network. Figure 1 shows examples of the above described connections between three different project examples.
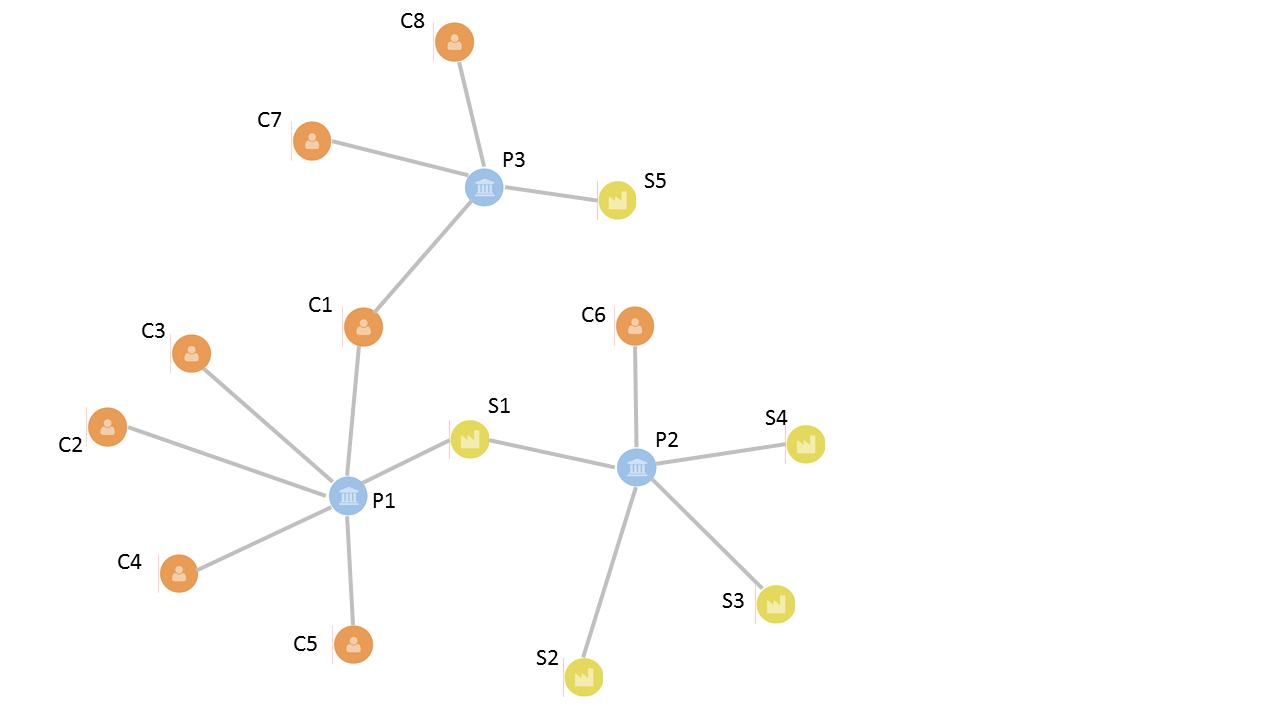
The business network is quite dynamic because the lifetime of each project is limited. For our evaluation and analysis, we generated and analyzed partner networks in consecutive one- month time windows. An instance of a network graph covers status of all projects created or already existing in a month. The lifetime of a project graph connection is bounded by the first and last financial transaction of the project. Figure 2 shows a part of monthly snapshot of our partner network graph in 2016.
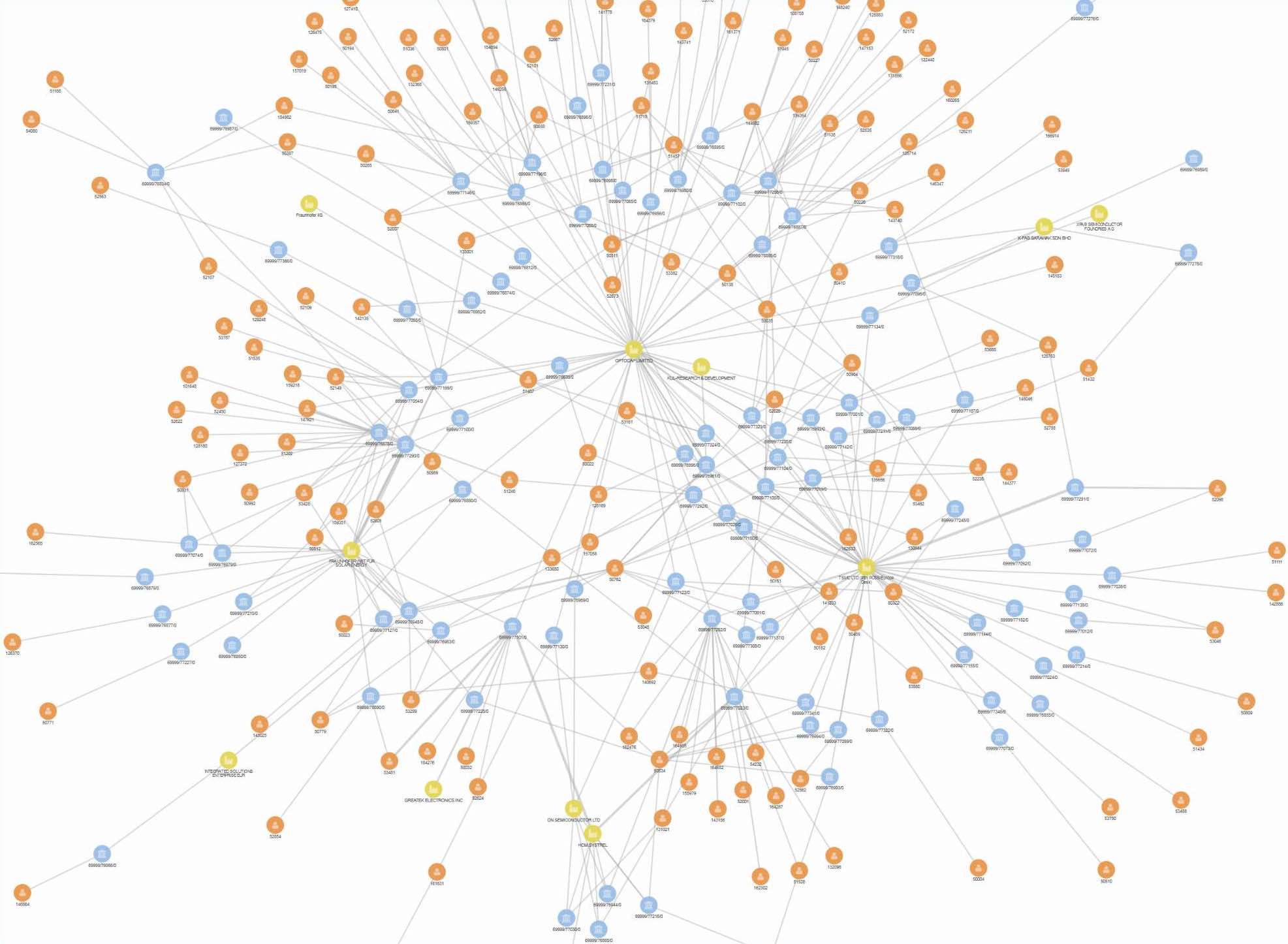
Technical Solutions
As was already mentioned, the core data for our analysis are in the form of tabular datasets from our internal data warehouse. These data must be processed into a form suitable for the Elasticsearch index when the local, intermediate SQL storage is imported using Logstash. These data are augmented with large amounts of unstructured textual data, such as technical and non-technical presentations, mail communication, etc., which exist in many different formats such as *.doc, *xls(x), *.pdf, *.txt, etc. The raw text content of these documents is extracted and linked to the previously created Elasticsearch index. In this way, project information with technical and technological details and with additional info related to our customers involvement not covered by standard CRM records is incorporated. Figure 3 shows the business analytics infrastructure with the Elastic Stack at its core.
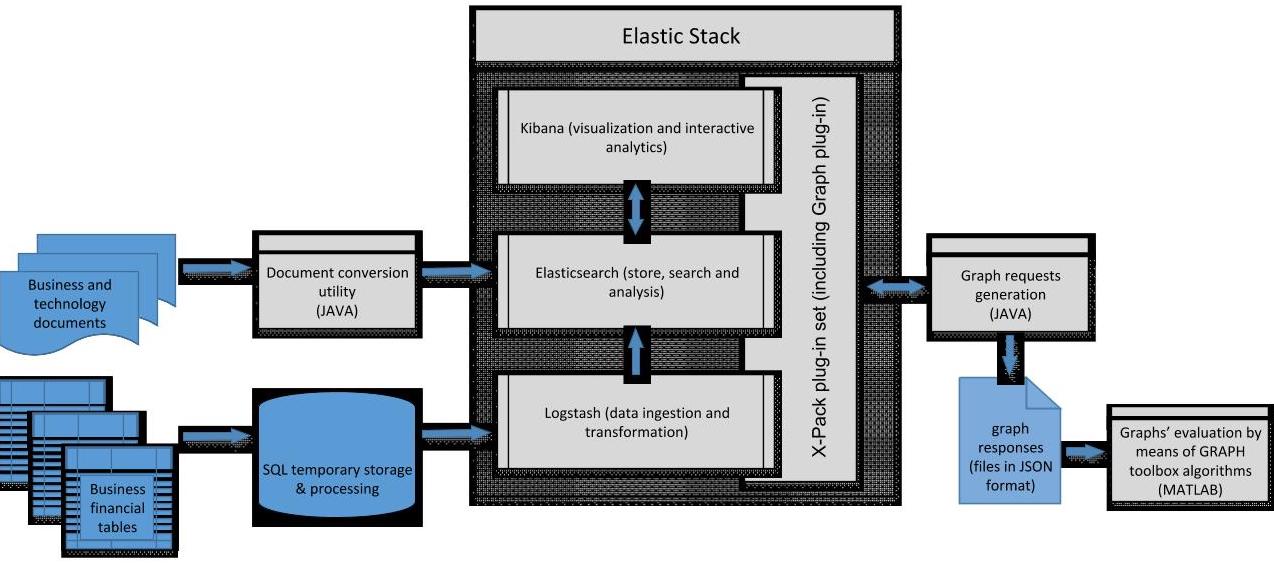
For the graph analysis of our partner network it is necessary to install the Graph plug-in, which is a part of an Elastic subscription. With the Graph plug-in, one can easily, interactively or programmatically, explore relations among data in an index without the necessity to create a special “graph compatible” index. Kibana, the visualization and analysis layer of the Elastic Stack, provides an interactive user interface for initial graph exploration. It is usually the first and most important step for initial graph formulation. It helps to identify data fields corresponding to intended nodes and qualitatively evaluate connections among nodes.
Graphs of our business network monthly were also available for a moving time window from 2004 until now. This resulted in the creation and evaluation of approximately 170 graphs and allowed the study of the evolution of the business graph over time. Since the business network has a moderate size this enabled the generation of all graphs in reasonable time without the need for any approximations such as limiting number of analyzed documents, defining minimum number of connections, or applying special techniques like “searching for significance”.
The graphs are automatically generated using the graph explore API by means of the Java REST client. Our Java code prepares Graph API requests, controls REST communication with Elasticsearch index and stores Graph API responses in JSON format.
After generation of the business network graphs for the period under study, processing and evaluation is carried out using the scientific programming environment MATLAB. This is a numerical computing environment with a proprietary programing language and with a large set of computational toolboxes for almost any type of numerical or symbolic computation. For this analysis, graph toolbox routines were exploited which are capable of manipulating and processing graphical objects. The graph toolbox also implements a rich set of sophisticated graph and network algorithms which were applied for the evaluation of the time-dependent properties of the business network.
The technical solution described here is only a small part of our overall infrastructure with the Elastic Stack in the center. This infrastructure was built with a focus on flexibility and adaptability to the varying content of processed data and with less attention paid to the size of imported data.
Graph Analysis
The first analysis procedure looks at a simple graph parameter – number of nodes. Figure 4 shows the growing number of nodes of the business network graph over time.
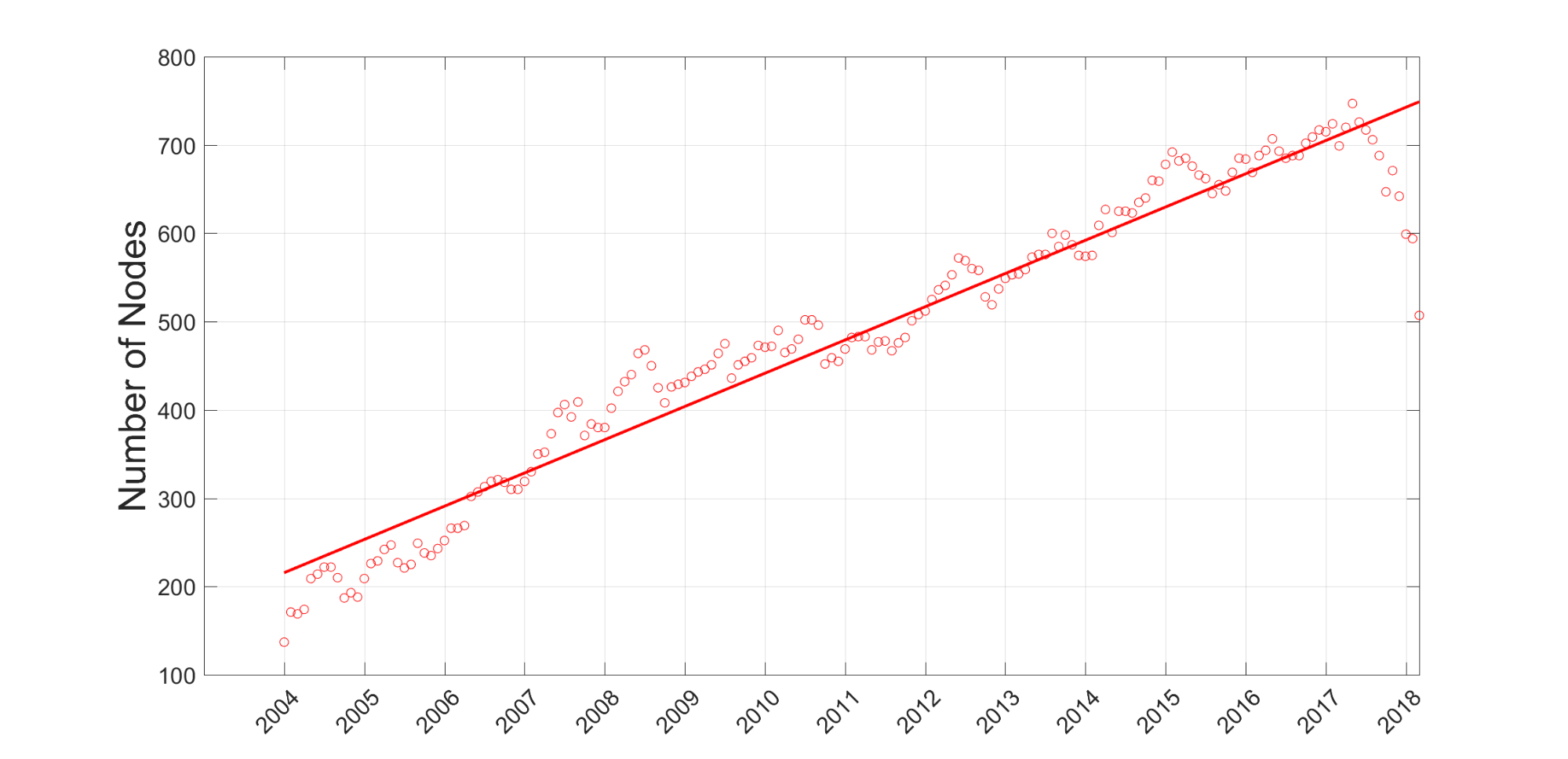
The overall number of nodes increased by factor of approximately 5, and clearly corresponds to a growing number of projects and a growing number of customers and suppliers. However, with respect to the node type, the suppliers exhibit the highest growth factor at almost 8. Another interesting centrality metric is the order or degree of a node. For undirected graphs, the degree of a node is defined as the number of edges connected to a node. Our time evolution shows a growing average node degree, and this is mostly driven by the increasing average degree of the supplier’s nodes. As the supplier nodes typically serve more projects than customer nodes, they naturally form high-degree hubs.
The average degree of customer nodes is shown in Figure 5:
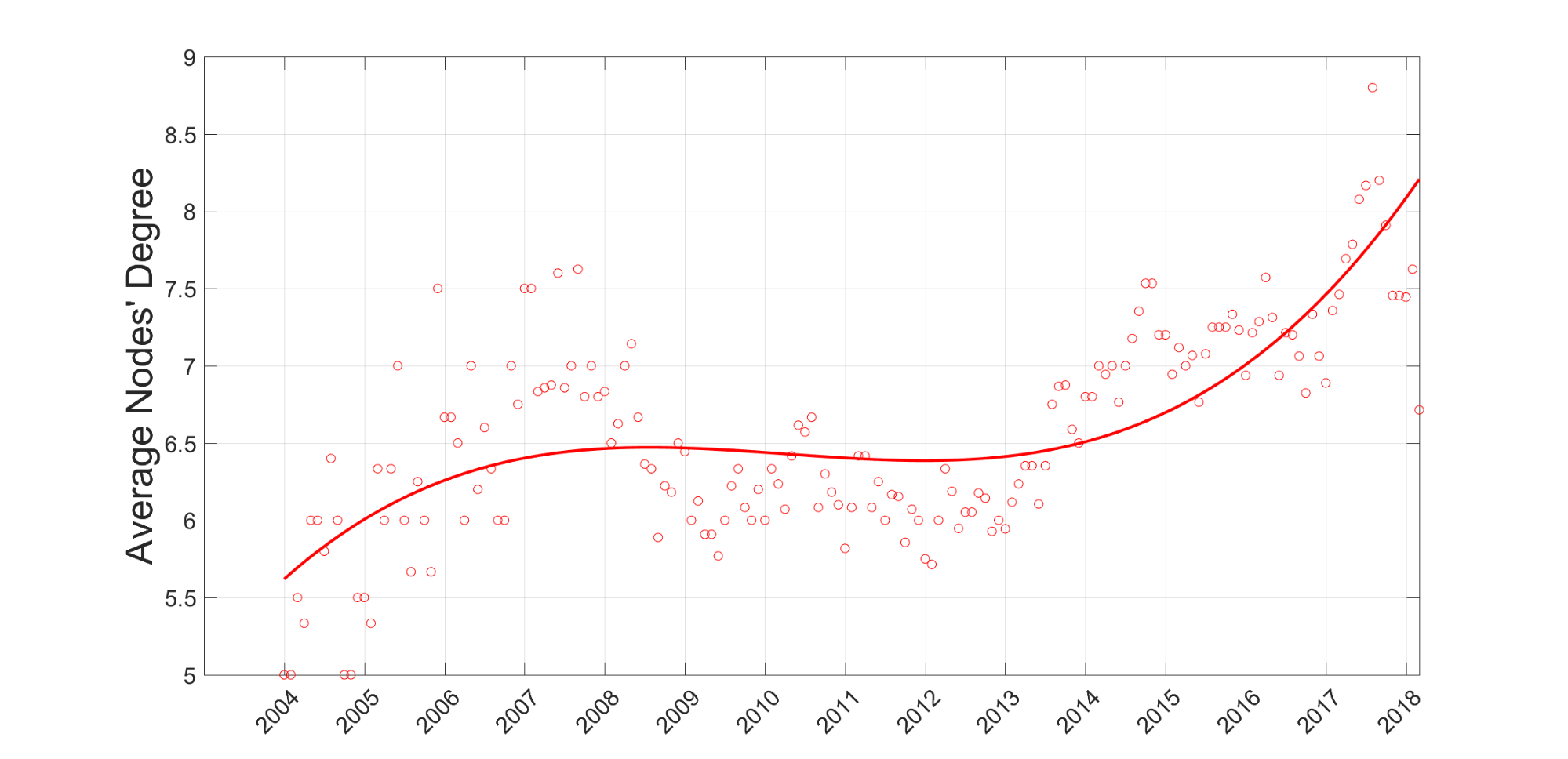
The increase is about 30% during the observed period. It demonstrates that the involvement and retention of customers is increasing. We can even speak about new customer class, let’s called them super-customers, which are growing and changing our customer landscape.
The next important network parameter, which was already mentioned it in the introduction discussion, is the degree of separation. In the case of our business network, we are searching for degrees of separation between any pair of customers nodes and it is computed using the shortest path between any pair of customer nodes. Figure 6 displays how the average shortest path is changing during observed period.
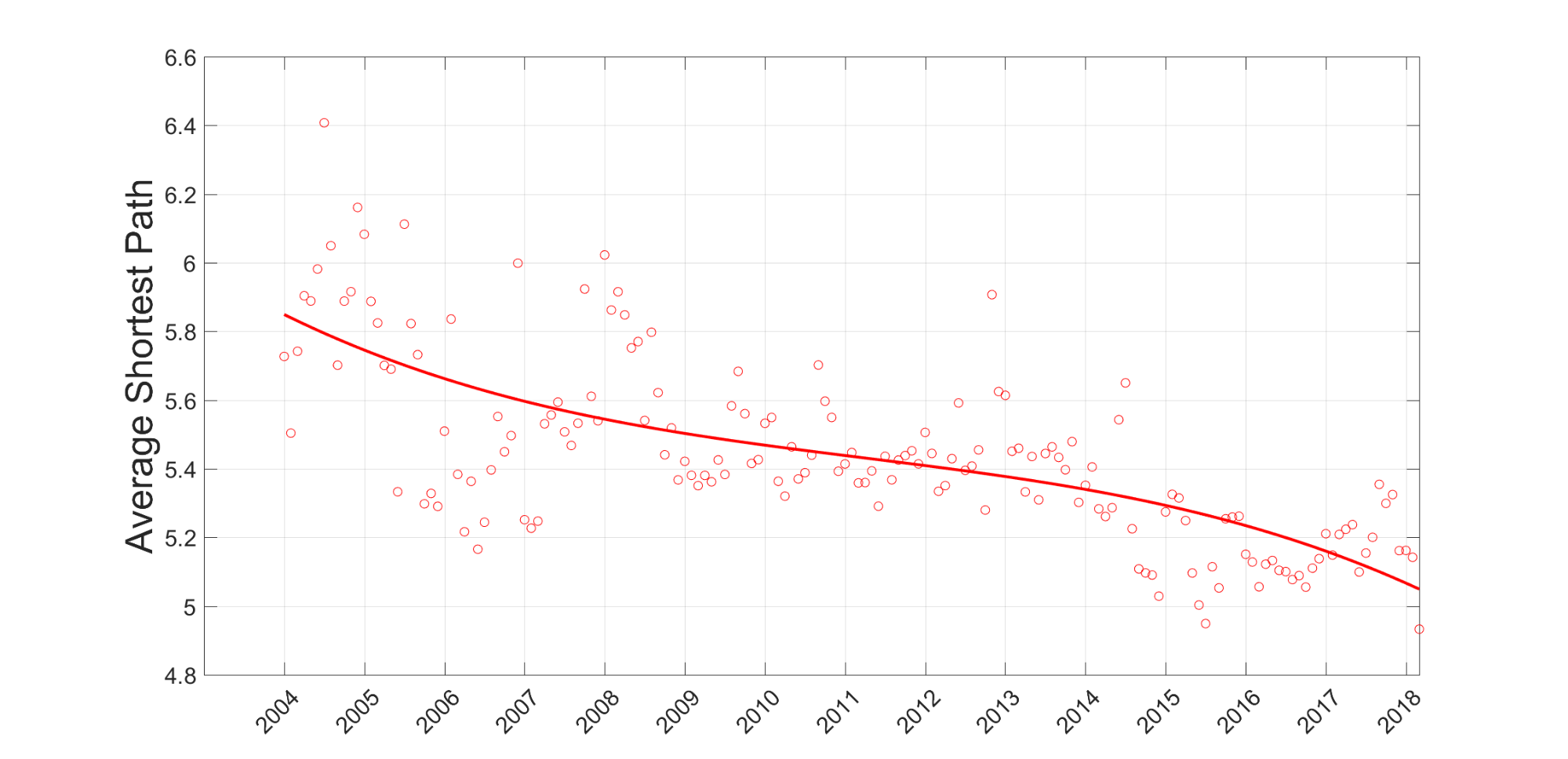
We can recognize the slow but permanent trend of a decreasing average shortest path between customers, especially in the second part of the graph, after 2013. The nature of our business graph differs in several aspects from simple single node-type graphs such as social network graphs. In the business network, direct connection between customers are not possible but must be intermediated through project nodes, so the only way to decrease the degree of separation between customer nodes is by increasing the number of customers which participate in more than one project. Such customer behavior exactly corresponds to the growing, already mentioned, group of super-customers. In addition, the increasing importance of suppliers providing numerous additional services creates additional connections, and also contributes to the decreasing degree of customer separation.
The last centrality parameter to be discussed is called betweenness, and is based on shortest paths. The betweenness metric captures how often a graph node appears on a shortest path between two nodes in a graph. Specifically, the betweenness c(u) for a node u is defined as:
.png)
Where nst(u) is the number of shortest paths from node s to node t that pass-through node u, and Nst is the total number of shortest paths from s to t. In general, the higher value of this centrality metric means the increasing importance of a node. The analysis shows that increasing the average betweenness for all types of nodes is driven mainly by the growing betweenness value of project and vendor nodes. Figure 7 displays this trend of growing betweenness of project nodes:
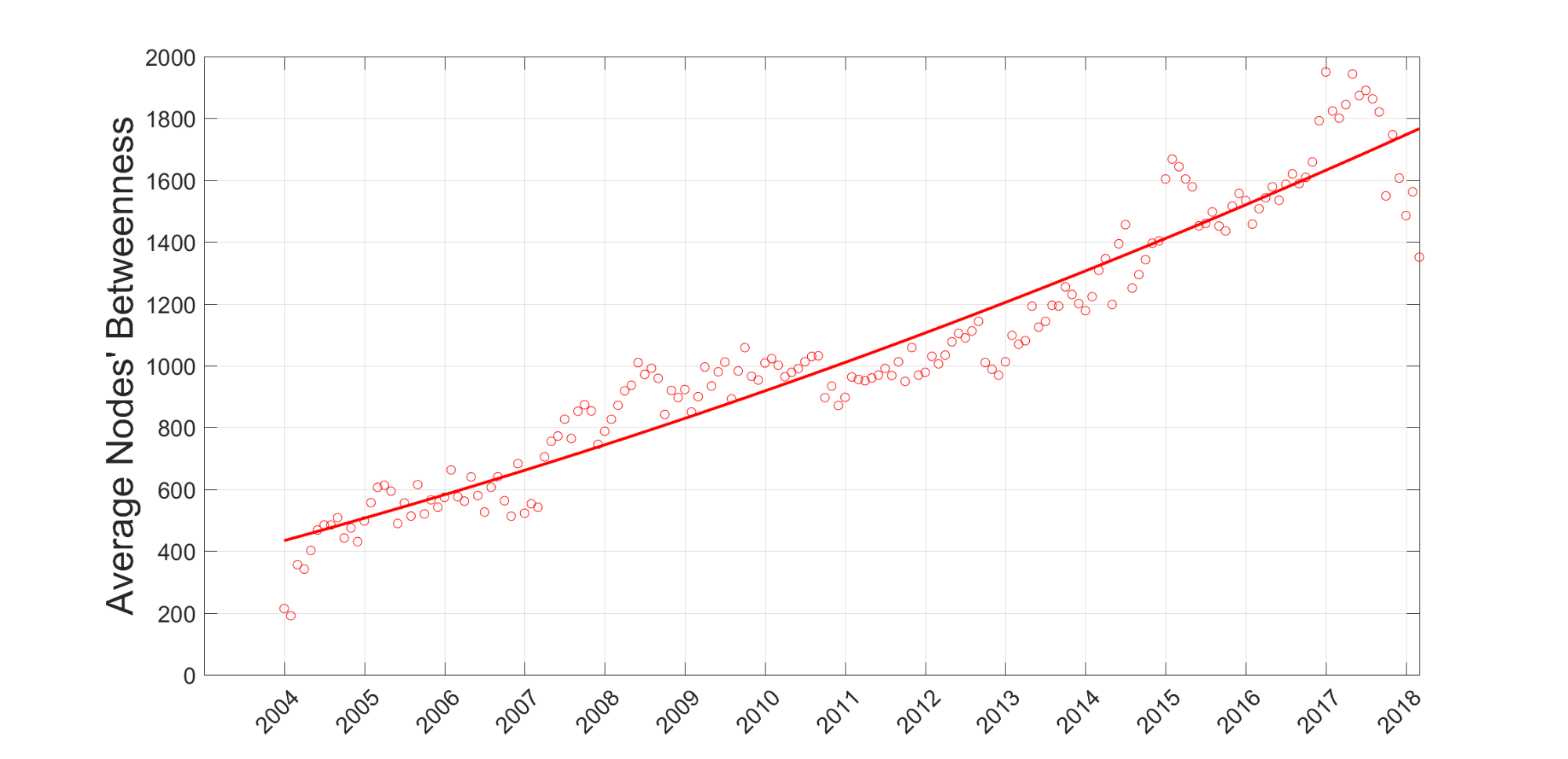
These results nicely correspond to the already concluded observations about growing number and complexity of our project and growing number and involvement of our suppliers.
Summary
In this blog, we presented a part of Imec Innovation Services and Solutions' infrastructure based on the Elastic Stack for modeling business partner network. The business network has evolved over time towards a much denser structure. Two main factors behind such structural changes are identified: the increasing number of suppliers due to the focus on providing more complex offering, more services along IC production chain and a growing class of so-call super-customers involved in more projects and that returned repeatedly. These two factors overlap and influence each other and together drive the changes in business activities.
We generated hundreds of business partner network graphs covering time evolution from 2004 till now and exported results into MATLAB computational environment. We apply various node centrality analysis to understand how business model of Imec Innovation Services and Solutions is changing and how is these changes reflected in the structure of business partner network. It was proven that the described approach based on modeling and analysis of business partner network as a kind of social network including its time evolution is a relevant method to study significant changes in existing business models.
Petr Dobrovolný is a software engineer who received his M.Sc. and Ph.D. degrees from the Brno University of Technology, Dept. of Microelectronics, in 1987 and 1998, respectively. During his Ph.D. studies he investigated the problem of the symbolic analysis of large analog circuits in the cooperation with the KUL, Dept. ESAT-MICAS. Since 1999, he has been with Imec, where he was involved in research and development projects focused on analysis and system level design of mixed-signal and digital electronics systems. Currently he is a member of the Business & Technology Strategy group of imec.IC-link. He is responsible for architecting and implementing business analytic framework aimed to generate various descriptive and predictive analysis results on top of internal IC-link business, operational and technology data.