CTcue: Making electronic health records more searchable with Elastic
Hospitals rely heavily on electronic health records (EHRs) to obtain a patient’s full medical history. However, healthcare data is complicated — 70% of the fields in EHRs hold unstructured, natural language data such as reports, reference letters and questionnaires. To make things more complicated, each doctor records information in a different way. Natural language in unstructured data isn’t easy for computers to understand, meaning it can be difficult to search. CTcue developed a privacy-by-design platform to help healthcare professionals find information in EHRs so they don’t have to employ business intelligence (BI) units to obtain insights. In this article, we’ll describe how we’ve used the Elastic Stack to power our solution.
Choosing a search engine
To allow users to build queries to both structured and unstructured documents, we needed a search engine that could handle unstructured documents, offered a flexible API, and was highly configurable and scalable. We decided to go with Elasticsearch, as Elastic was able to offer all of the aforementioned requirements and also has an active community and a development cycle with rapid iterations. All in all, the ecosystem met our current needs and the Elastic roadmap is in line with the majority of our ambitions. We have used Elasticsearch since late 2015 and haven’t run into performance issues related to the engine itself; therefore, we didn’t have a reason to explore other vendors.
The data model and its complexity
In stark contrast to the structure and complexity of logging data — a common Elasticsearch use case — the data CTcue uses is highly relational. We considered using a mapping with parent/child and join relations, but we determined that this approach would heavily impact search performance. We decided to go with a denormalized data structure where every patient represents a single top-level document with numerous nested documents. This of course comes with drawbacks, as the document size grows tremendously with this approach. We made the decision to trade index time performance (i.e., time to load and update the data) for search performance, because we would rather spend more time loading the data than burdening the end user with a slow search experience.
Prior to Elasticsearch 6.x, we used a data model that heavily relied on parent-child relationships. Each of the ‘types’ represented an entity such as ‘Medication’, ‘Operation’, ‘Admission’ etc. that all related to a patient. Already expecting that our data model would grow tremendously in the future, we realised that this type of relationship would not scale for query search time, especially with our limited resources.
To prepare for and implement our migration to Elasticsearch 6.x, we decided to contact Elastic to set up an on-site consultancy track. During the excellent kickstart video conferences with the Elastic team, we outlined the topics, ambitions and challenges that we were facing. The Elastic team pointed out that scalability could be a concern with the number of types we already had in play.
Previously, our data pipeline relied on the separate processing of each type. As this would update and insert documents using routing, it was quite fast but not scalable. For the migration we had several options to load our data in an index: either perform inserts and updates using Painless scripts or, for every update cycle, delete the old document and insert the complete top-level document, including all the nested fields, again. During the consultancy track we explored different implementation methods, but we found that the sizes of our documents and this level of nesting were fairly uncommon. In the end it seemed that updating these large documents with Painless was sub-optimal and we decided to go with full document inserts.
Currently, the CTcue data model encompasses close to 600 (nested) fields for each patient, each of which has specific requirements pertaining to search functionality (completion suggestion, aggregation, match phrase and match phrase prefix text search).
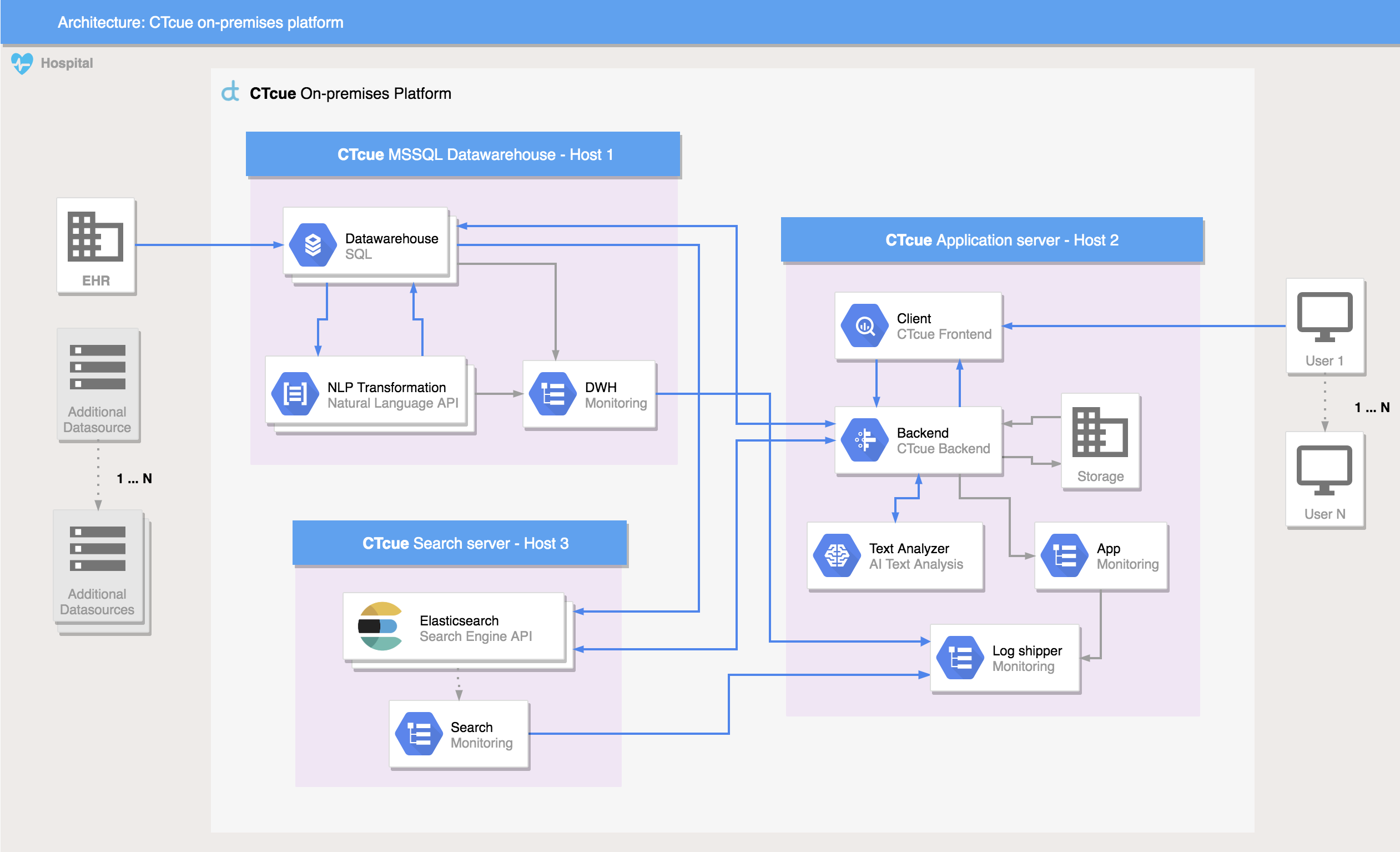
Figure 1: The architecture of the CTcue platform and how it fits in an on-premises infrastructure
Limitations of the on-premises infrastructure
The requirement for the search engine to be highly configurable comes out of the fact that the CTcue platform runs on extremely limited on-premises infrastructure. We have no control over hardware specifics such as processor speed or the availability of flash storage. This forced us to carefully select new query implementations and apply early-stage query optimizations (for example, wildcard match phrase queries tend not to be too kind on a four-core 16GB single-node Elasticsearch instance). Moving to on-premises production environments, we plan to set up three-node clusters and take advantage of Elastic subscription features such as auditing and security to improve search performance and ensure high availability.
Giving meaning to the context
Sadly, text search alone does not always give meaningful results. Natural language processing is required to handle linguistic negations and implications of medical terminology. A prime example of this would be searching for the text “hypertension” in a report. In the majority of the cases this will yield results; however, it will also return documents with the text “...brother has hypertension...”. This is typically a result that the end user would not be interested in. For this reason we preprocess and enrich our data prior to indexing to detect these occurrences so they do not arise at search time.
Impact on the healthcare industry
CTcue delivers accessible, privacy-by-design, enterprise-level search of EHRs to healthcare professionals. It enables researchers and trial nurses to perform prospective feasibility studies and collect the respective minimal datasets to be used for further analysis. Imagine that a new medication has been released to market and a healthcare professional would like to contact refractory patients to introduce them to this medication. Having a way to proactively provide healthcare by efficiently searching through EHRs could improve the quality of life of patients or potentially save lives.
Other use cases include integrating real-world evidence in internal studies to gain more insights into diseases, their treatments, therapy utilization and comparative analytics for the efficacy of used medications. An example here would be to investigate whether antibiotics are administered according to regulatory guidelines. The usage of antibiotics must follow strict guidelines, as a dose which is too low might not result in the correct efficacy and a dose which is too high might result in bacterial resistance. In this case, traditionally data would be manually collected from patient records or specialised clinical BI units, which are often limited to structured data. Several independent internal studies performed in hospitals have shown that determining patient cohorts using the CTcue platform saves up to 40x time spent compared to traditional methods.
The impact of CTcue and Elasticsearch making unstructured data accessible within the healthcare domain is tremendous. Previously untapped streams of data give insight into diagnoses, treatments and all real-world data available in a hospital, all with the end goal of improving internal processes and patient healthcare.
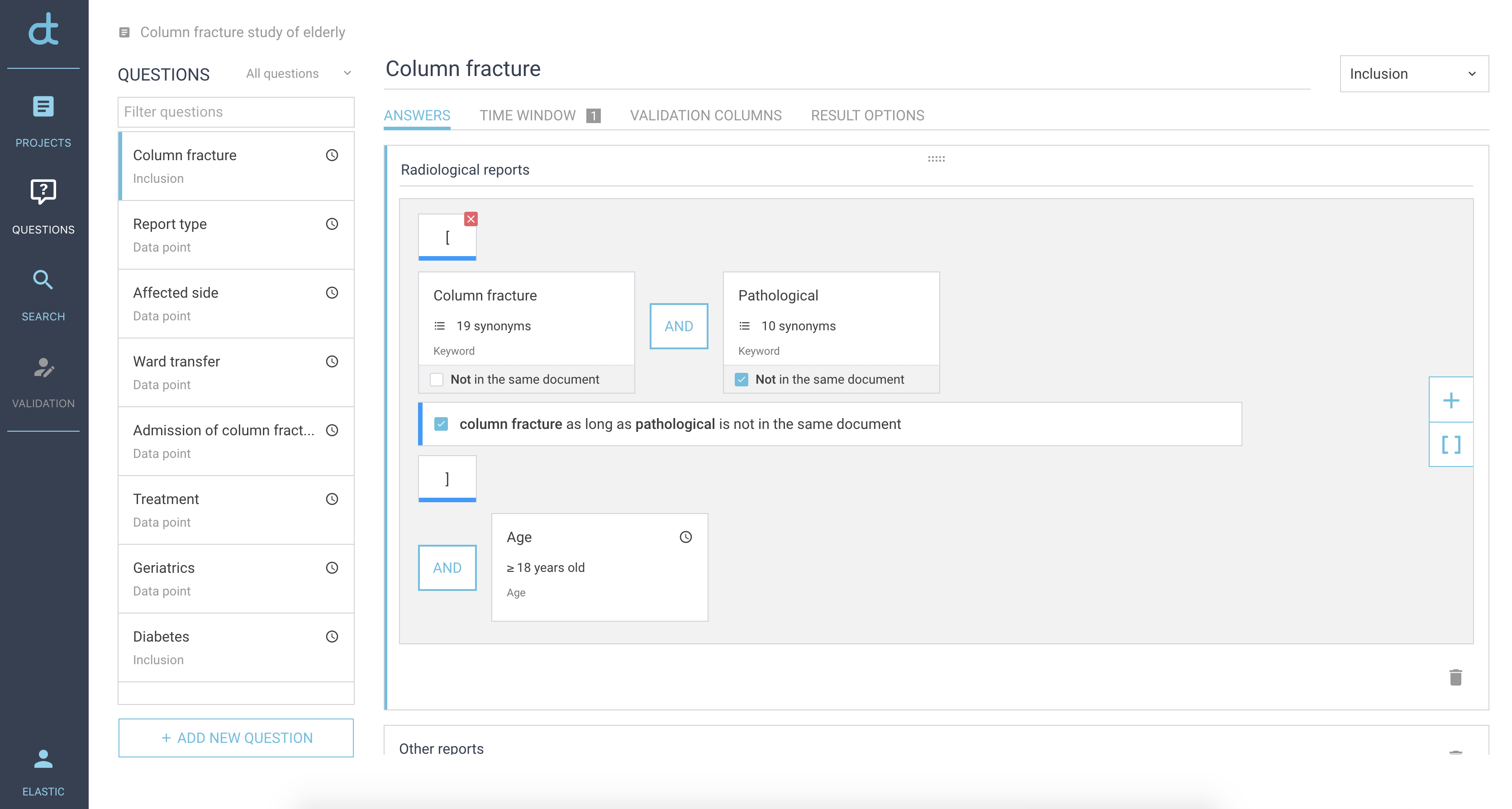
The future
Although we extensively employ enterprise search with Elasticsearch, we haven’t touched on all the available components in the Elastic Stack. As the number of hospitals deciding to implement CTcue is growing tremendously, we need better ways of reporting on the health of our deployments. In the near future we will be focusing on infrastructure scalability, centralised monitoring and reporting to improve the level of service.
After collecting a population or data thereof in the CTcue platform, it can be challenging for the end user to visualise or track changes over time. These insights can stem from a wide range of applications, such as performance metrics of a specialism or department, efficacy of a medication or even patient satisfaction levels after a certain treatment. When data is updated regularly, you wouldn’t want to force the end user to make export after export so they can update their own Excel graphs. This process has to be automated.
Since we are already running the Elastic Stack, the ideal candidate would be to use visualisations in Kibana and Canvas. Currently there are features being designed that will expose this data to the on-premises Elastic Stack, enabling users to use existing Kibana dashboards or Canvas workpads for near real-time monitoring.
Due to the sensitivity of healthcare data, it is also extremely important to be able to extensively audit the activities within the platform and keep track of data provenance. To make this happen we are extending our existing auditing suite and plan to make dashboards and alerting available to IT administrators and data security officers in the future. To make full use of these functionalities we plan to move to a subscription-based model for on-premises Elastic clusters.
One thing is for sure — the amount of usable data in on-premises healthcare infrastructures, much of which is currently lost in the noise, will only continue to grow. We want to make this data accessible to the healthcare professionals to whom it matters, all with one end goal in mind: to improve healthcare for the patient.

Bernd van der Veen graduated with a BSc in Bioinformatics and throughout his career held a strong affinity with the healthcare domain. Having transitioned from statistical genomics to software development, he worked at the Dutch Cancer Institute (NKI-AVL) and the open source life sciences IT company The Hyve. Currently he is the lead developer at CTcue, where he focuses on architecture and inventing how health care providers should interact with the data they generate and making it accessible to those who need it most.