Connect a custom AWS S3 snapshot repository to Elastic Cloud
.jpg)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In this blog, we will walk through backing up our committed cluster data via Elasticsearch’s snapshots into an AWS S3 bucket. In Elastic Cloud (Enterprise), Elastic provides a built-in backup service under its found-snapshots repository. Elasticsearch also supports custom repositories for both Cloud and on-prem setups, connecting to data stores like AWS S3, GCP, and Azure for all platform types and also filesystem for on-prem. These built-in and custom snapshot repositories offer great options for data backups; custom repositories for longer term storage and on-off backups; and found snapshots for ongoing, recent backups. Users often integrate both methods into their production clusters.
Create AWS S3 bucket
To begin, we will set up an AWS S3 bucket to store our date following the AWS guide.
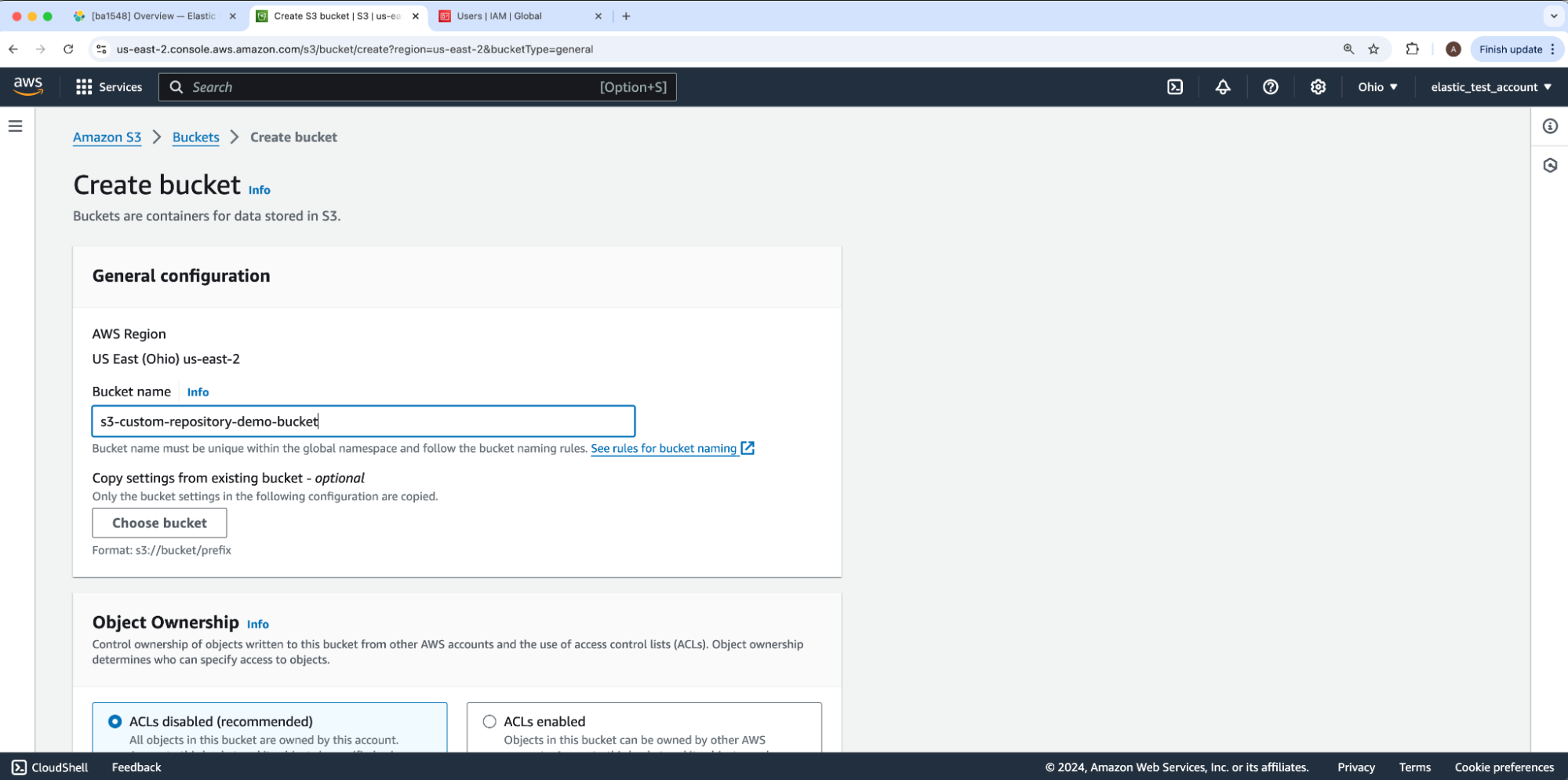
Under Create bucket, fill in the Bucket name and leave all other options at their defaults. Then, click Next to create this bucket to hold our data. For our example, the bucket name will be s3-custom-repository-bucket-demo.
Setup AWS IAM policy
Next, we will set up access authorization to our newly created bucket by creating an AWS IAM policy.
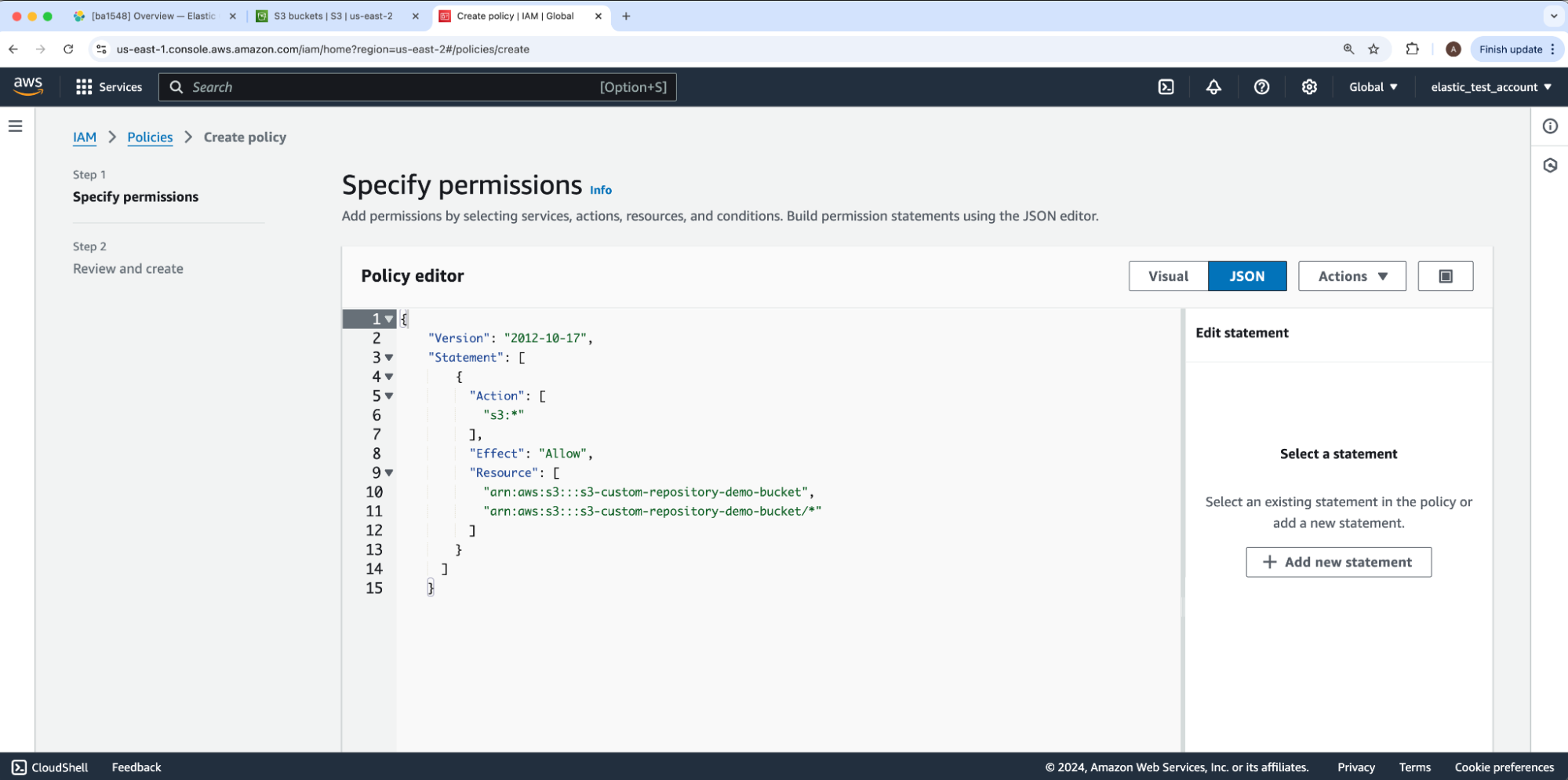
Under the first step for Create policy called Specify permissions, we will copy Elastic Cloud’s recommended S3 permissions into the JSON “Policy editor” — only retaining the value AWS originally had for its “Version” JSON key. You may prefer further permission restrictions as outlined within Elasticsearch’s documentation. We will replace the guide’s JSON’s placeholder bucket-name under Resource with our bucket name s3-custom-repository-bucket-demo. Then, we will select Next to proceed to Step 2: Review and create.
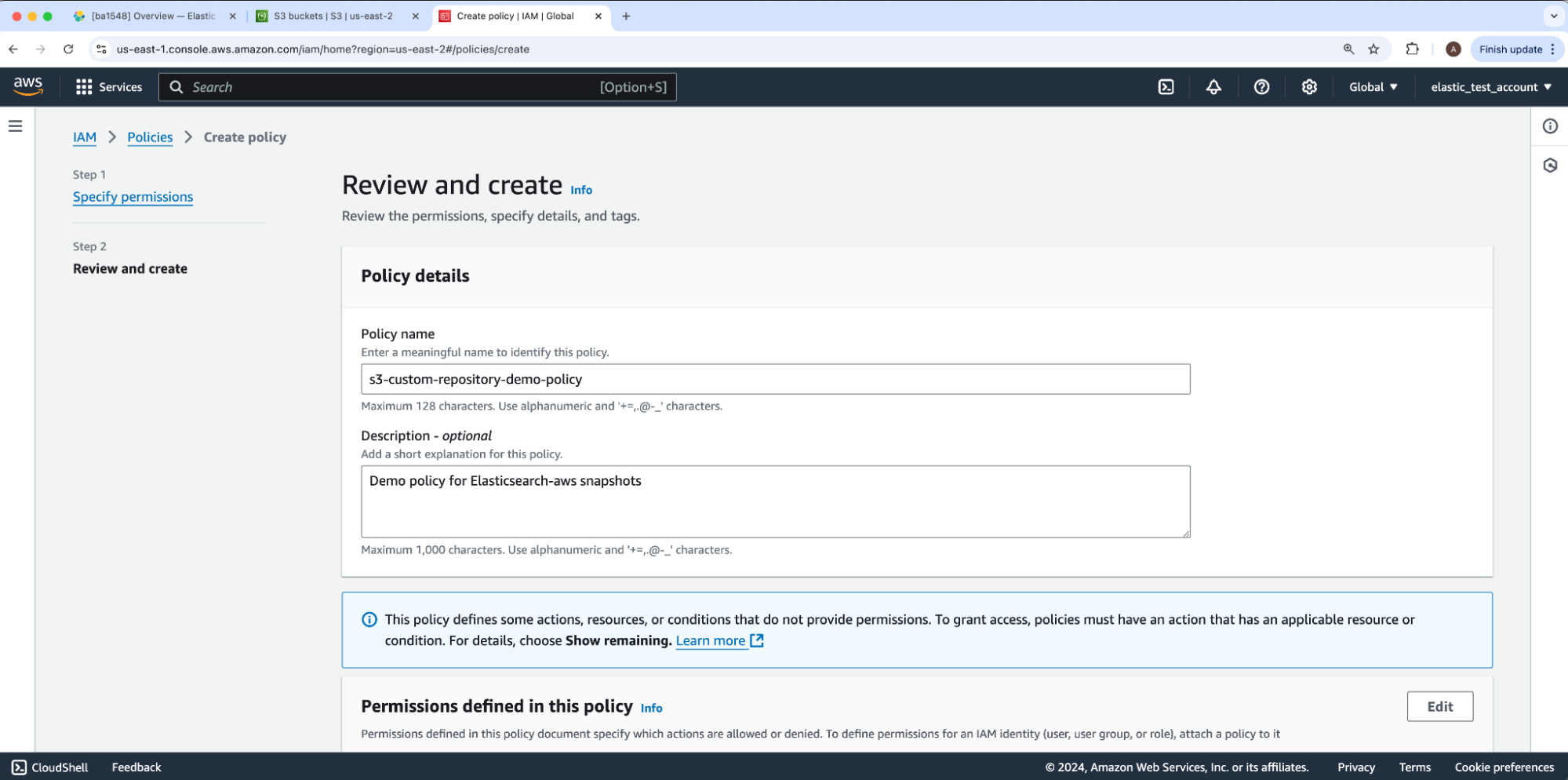
We will enter a Policy name and Description, then select Next. For our example, the policy name will be s3-custom-repository-demo-policy.
Create IAM user
Next, we will create an AWS IAM user, granting it authorization by way of our newly created IAM policy. Under the Create user flow, we will begin with Step 1: Specify user details. We will enter the user name as s3-custom-repository-demo-user, leave all other options on the page at their defaults, and select Next to move on to Step 2: Set permission.
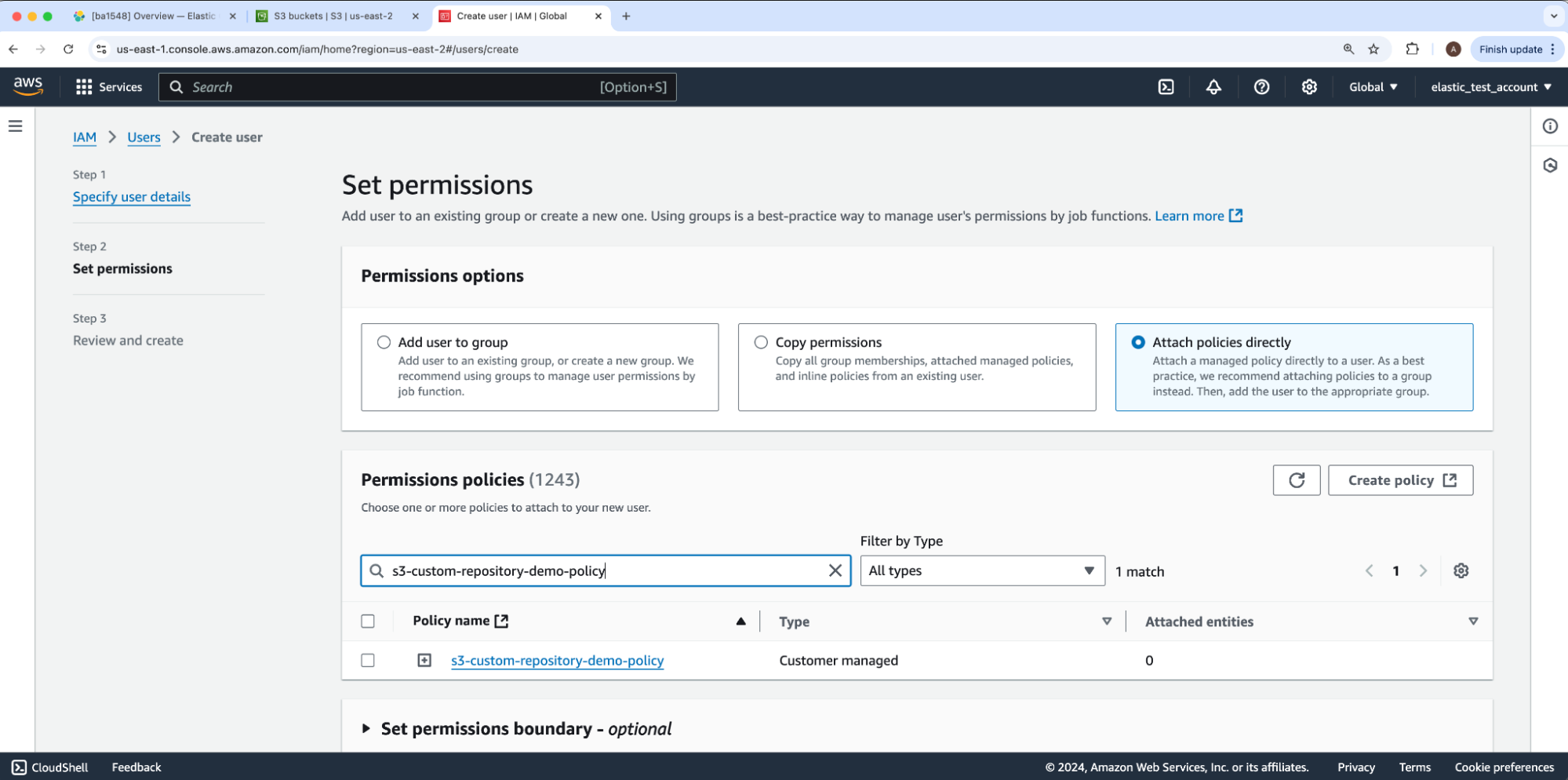
Here, we will attach the IAM policy to our user by selecting the Permissions Options value and Attach polices directly. Then, under Permissions policies, we will search and enable our IAM policy. Once done, we will leave all other options at their defaults and click Next to move onto Step 3: Review and create then scroll through and click Create user.
Setup IAM user access key
Elasticsearch connects to AWS S3 via an IAM user’s access and secret key as opposed to its username and password. In order to connect the bucket to our Elasticsearch cluster, we will create an access and secret key to later store in the deployment’s Elasticsearch keystore. Under our IAM user, we will select Create access key.
This directs us to the Create access key flow under Step 1: Access key best practices & alternatives.
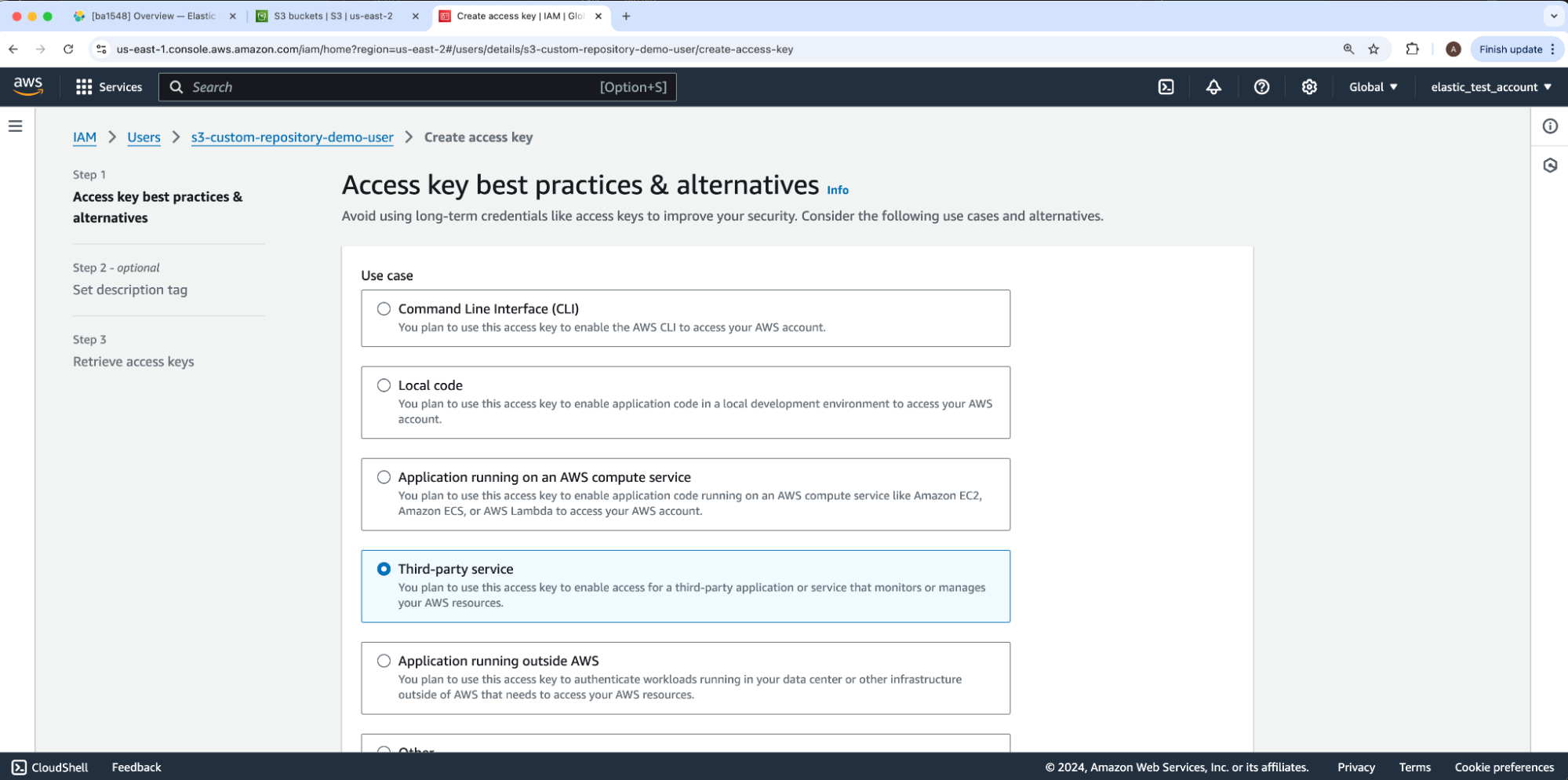
For the Use case, we will select Third-party service and then click Next. This takes us to Step 2 - optional: Set description tag which we’ll skip through by clicking Next again, bringing us to Step 3: Retrieve access keys.
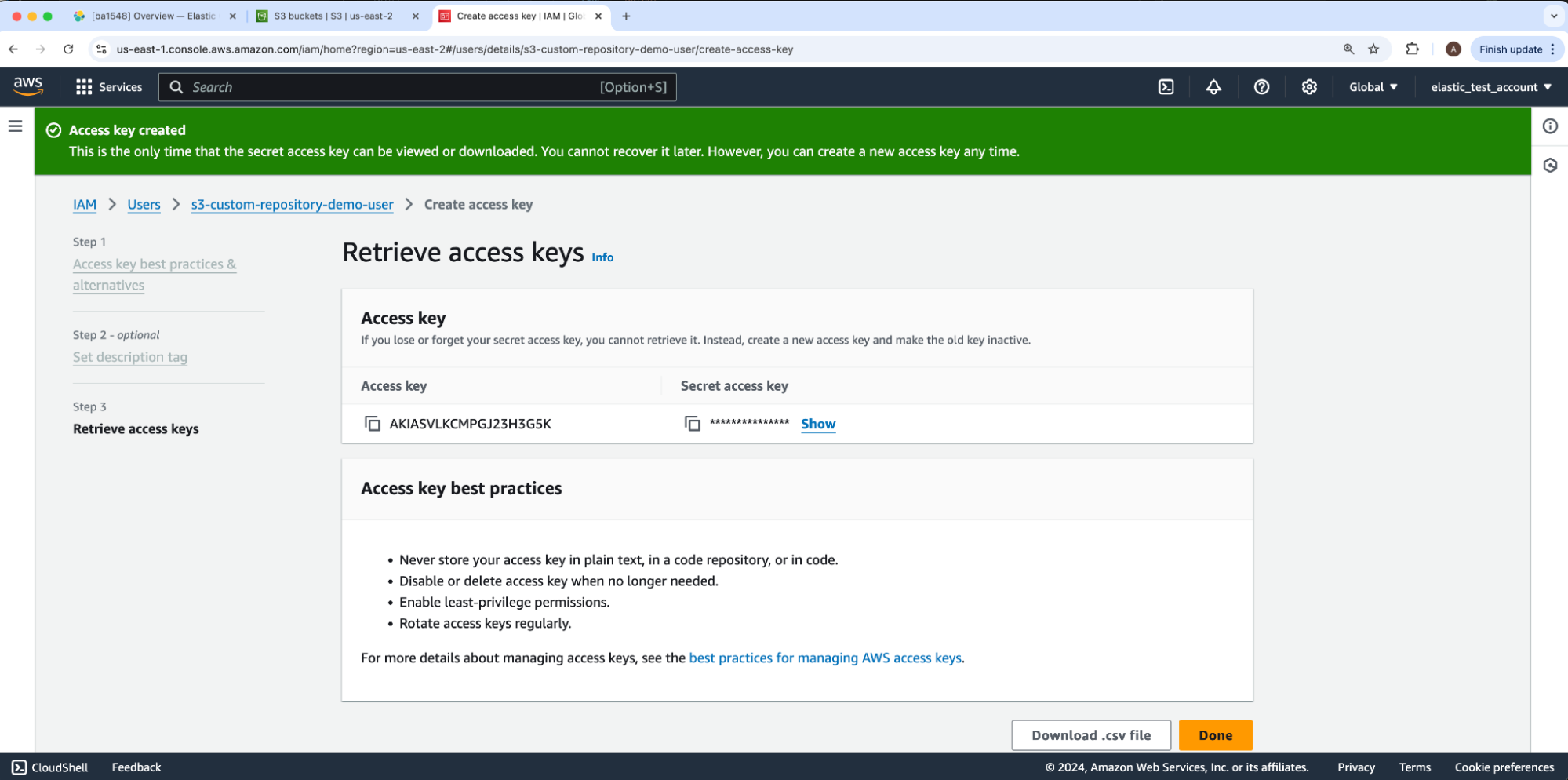
We will securely store our IAM user’s new access and secret keys.
Connect to deployment
We will add these IAM user access and secret keys to our Elastic Cloud deployment.
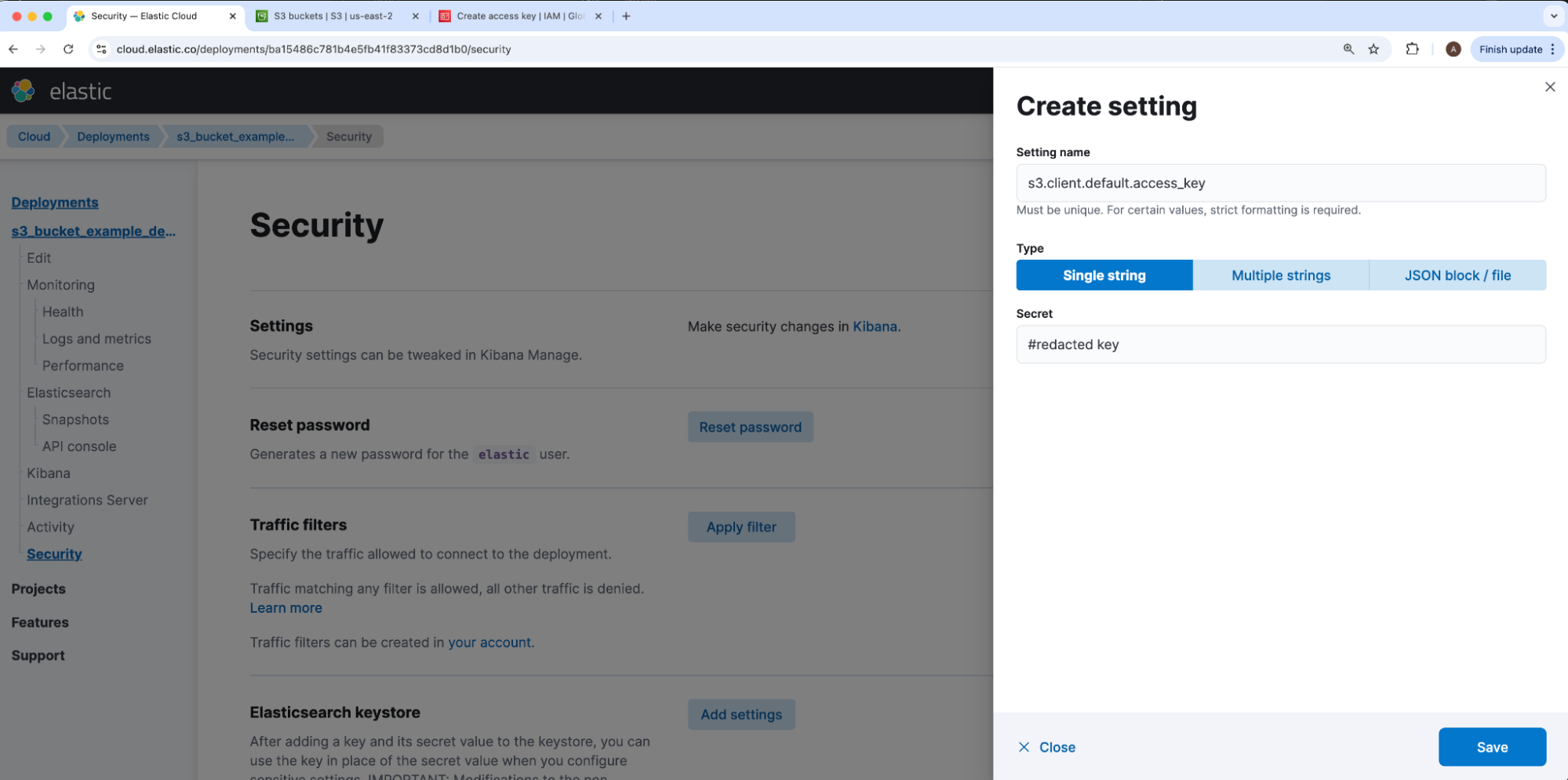
Under our deployment’s security tab, we will navigate to elasticsearch-keystore and click Add settings. In case there are multiple access and secret key pairs for separate S3 repository connections, the Elasticsearch S3 repository JSON maps our access and secret keys via a client string. Our IAM User’s access key will be the value of s3.client.CLIENT_NAME.access_key and secret key will be the value of s3.client.CLIENT_NAME.secret_key, where CLIENT_NAME is a placeholder for that S3 JSON mapping’s client value. Because the client defaults to default, we will use the same for our example, so our access and secret values to insert under Setting name will be stored under keys s3.client.default.access_key and s3.client.default.secret_key respectively.
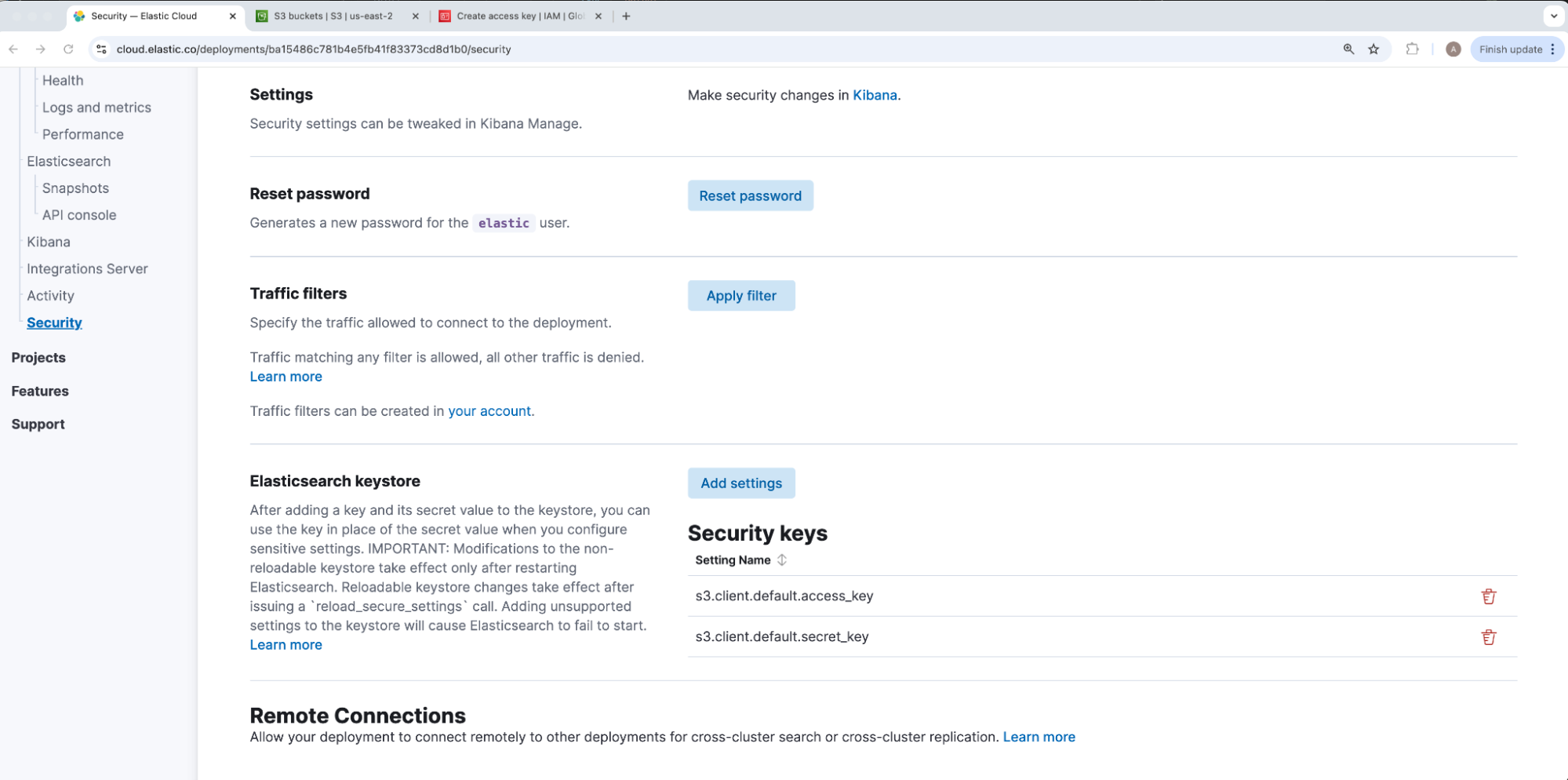
Once added, our keys will show under Security keys. For security, our keystore values cannot be viewed nor edited after adding — only removed to recreate.
Create repository connection
We will now register our AWS S3 Elasticsearch repository via Kibana. We will load our secure settings into our cluster by running node reload secure settings under Dev Tools.
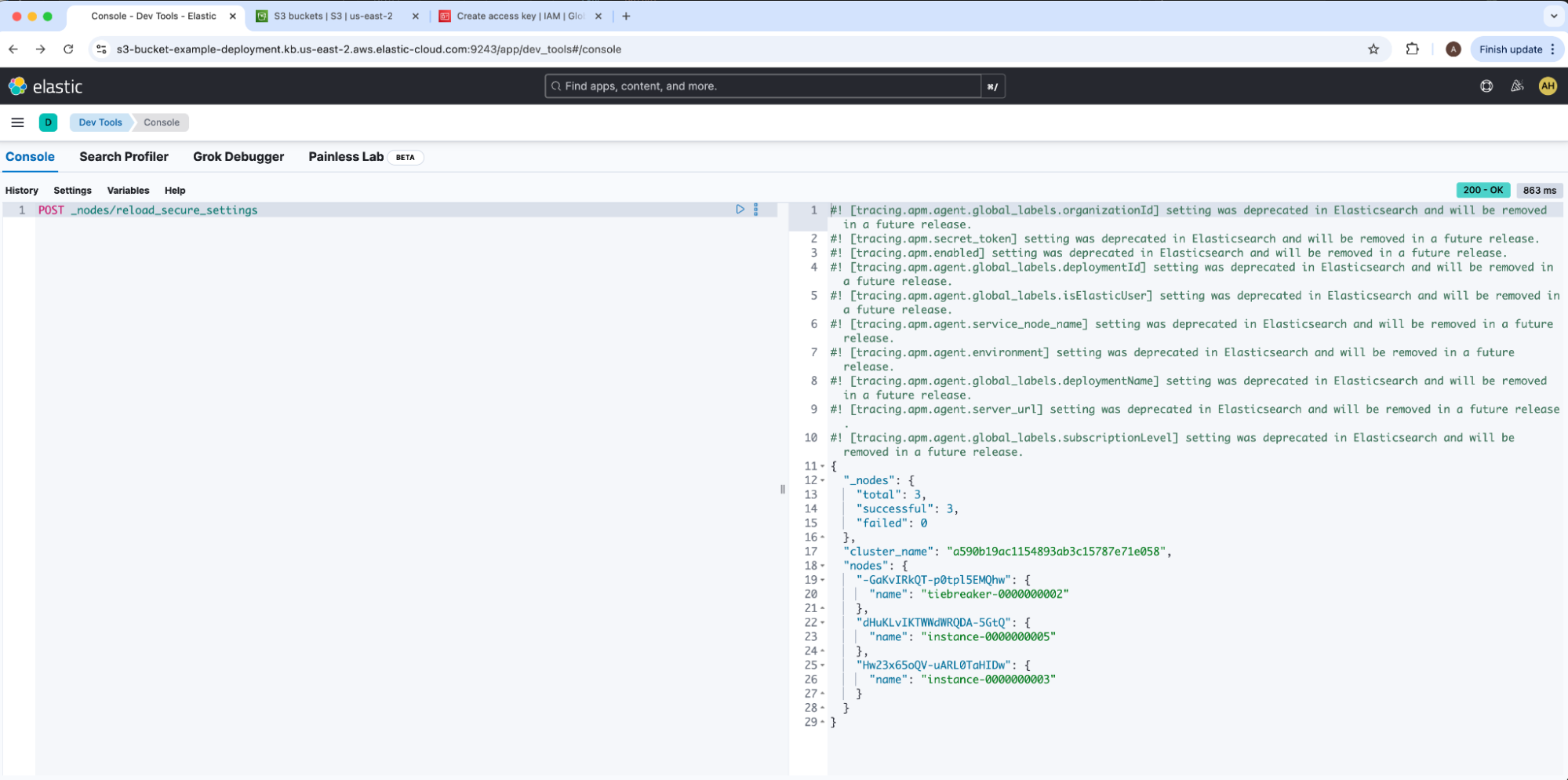
A successful response will emit _nodes.failed: 0. Our access and secret keystore pair are now added into Elasticsearch, so we can now register our AWS S3 repository. We will then navigate to Snapshot and Restore under Stack Management and click into the Repositories tab, then select Register a Repository.
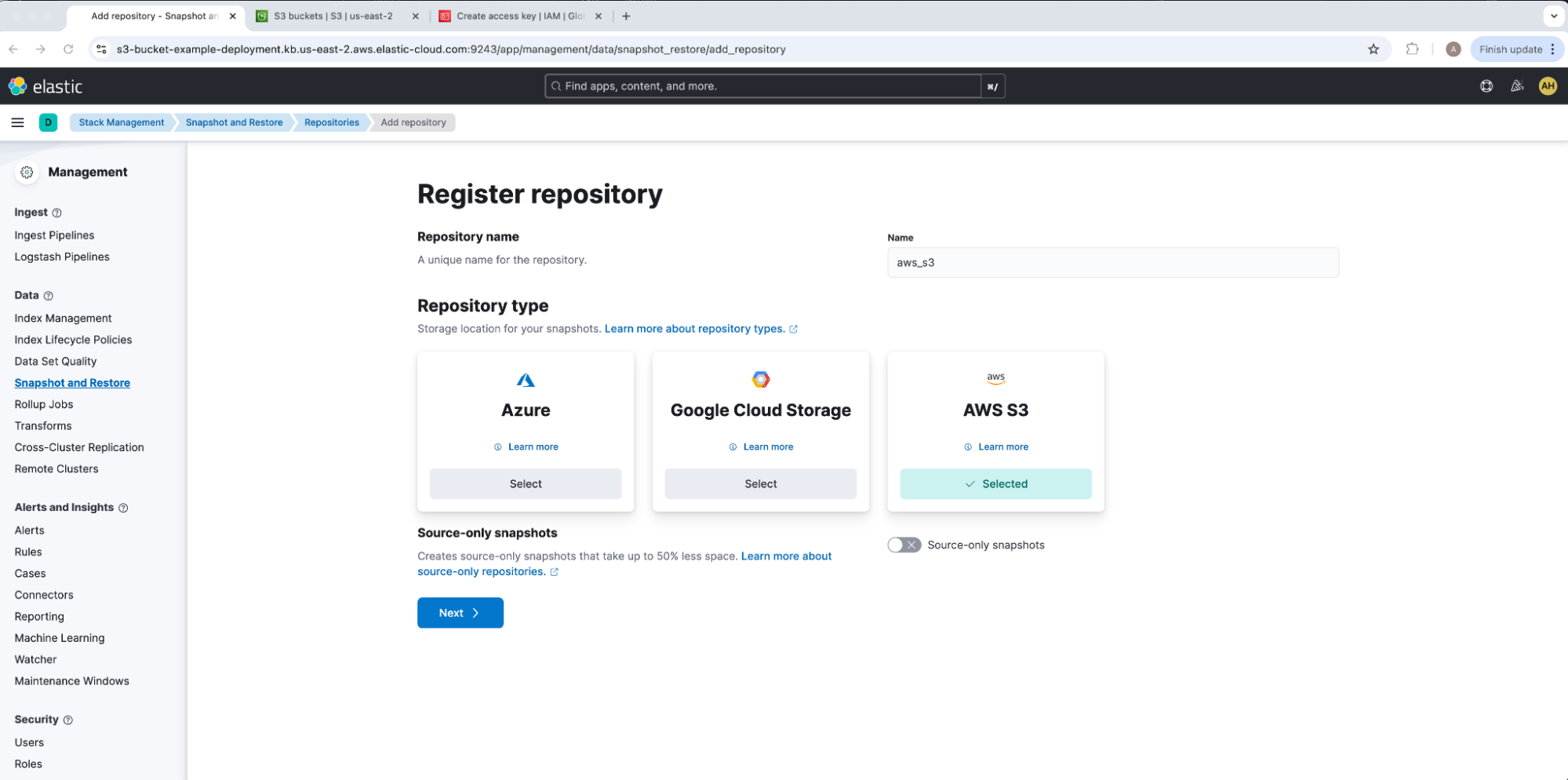
We will give our repository a Name and select a Repository Type of AWS S3. For our example, our repository name is aws_s3. Kindly note that while most Elasticsearch features like Allocation load data from the repository based on its stored uuid once initially registered, ILM searchable snapshots do use the repository name as an identifier. This will need to be lined up across Elasticsearch clusters when migrating searchable snapshot data.
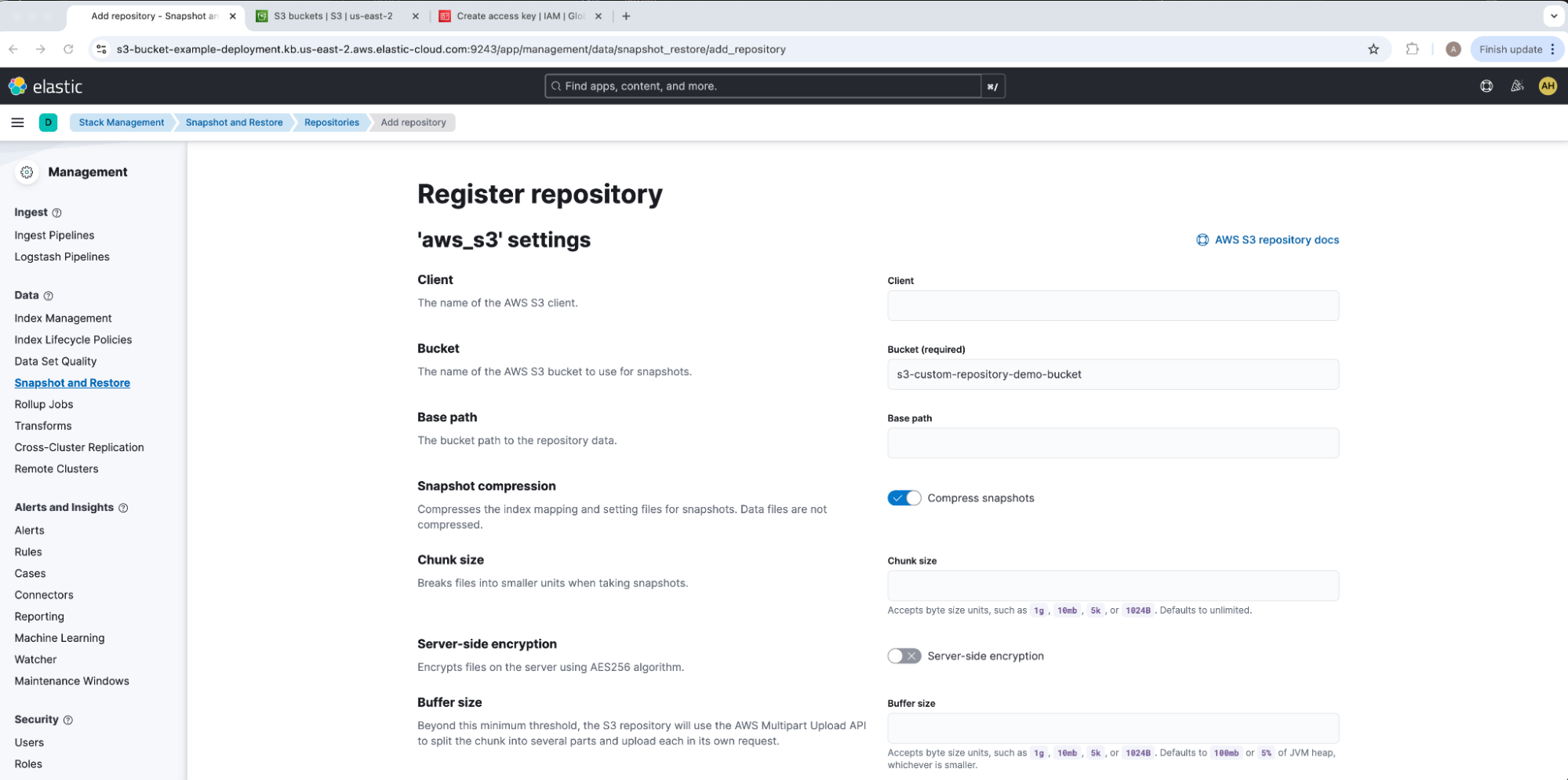
Under Register repository, add our Bucket name s3-custom-repository-demo-bucket, leave all other options at their defaults, and select Save. For our example, we will leave the Client empty in order to default to default to match our Elasticsearch keystore CLIENT_NAME. Kindly note that only one read-write connection from one Elasticsearch cluster should be acting on a repository at a time; as needed, make sure to flag readonly to avoid accidental data overwriting or corruption. This will take us to the aws_s3 repository overview UI drawer.
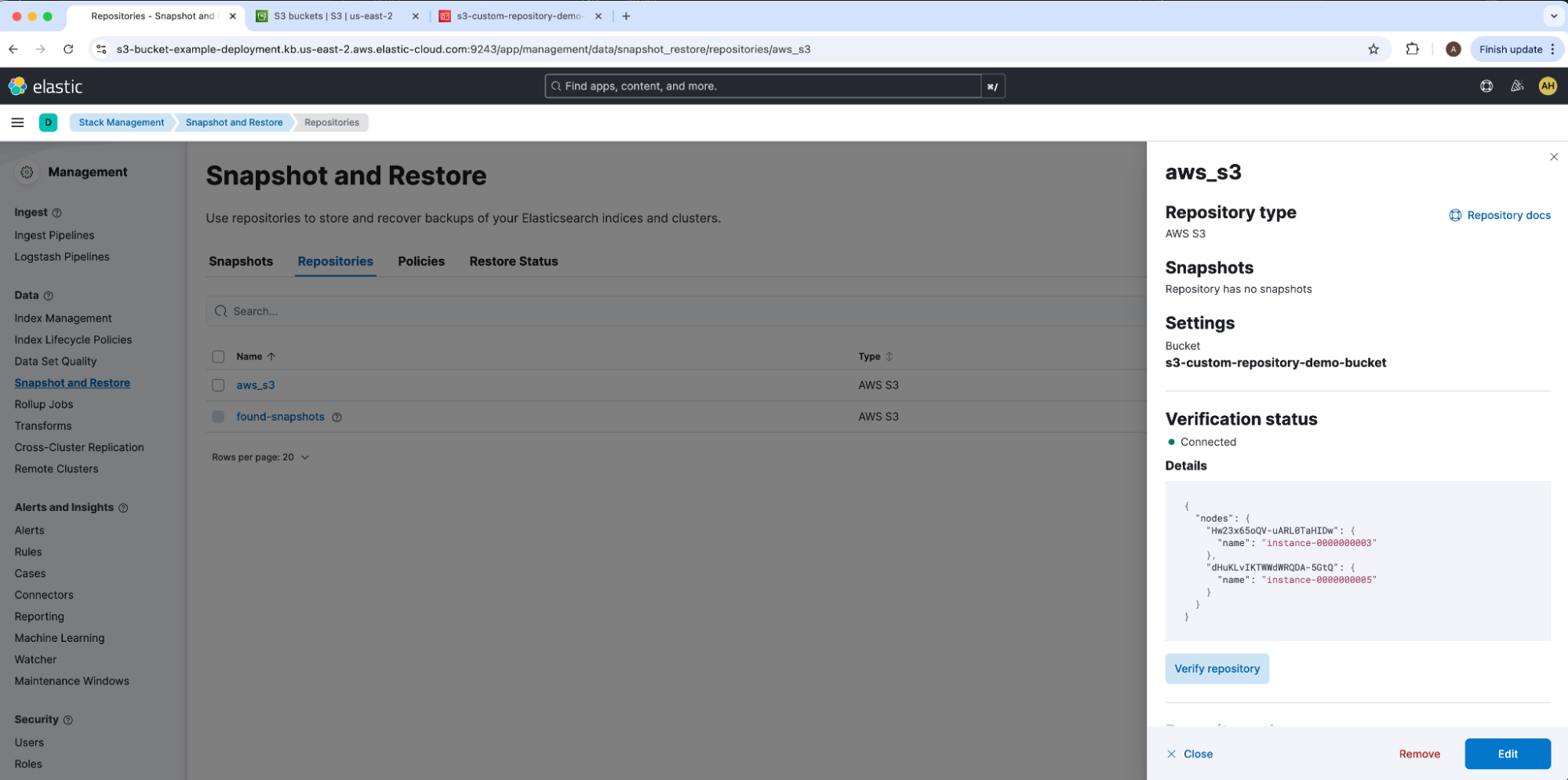
Here we can select Verify repository under Verification status to confirm that all nodes can connect to our AWS S3 bucket and pass initial verification checks. We can also run this same test from Dev Tools with verify snapshot repository.
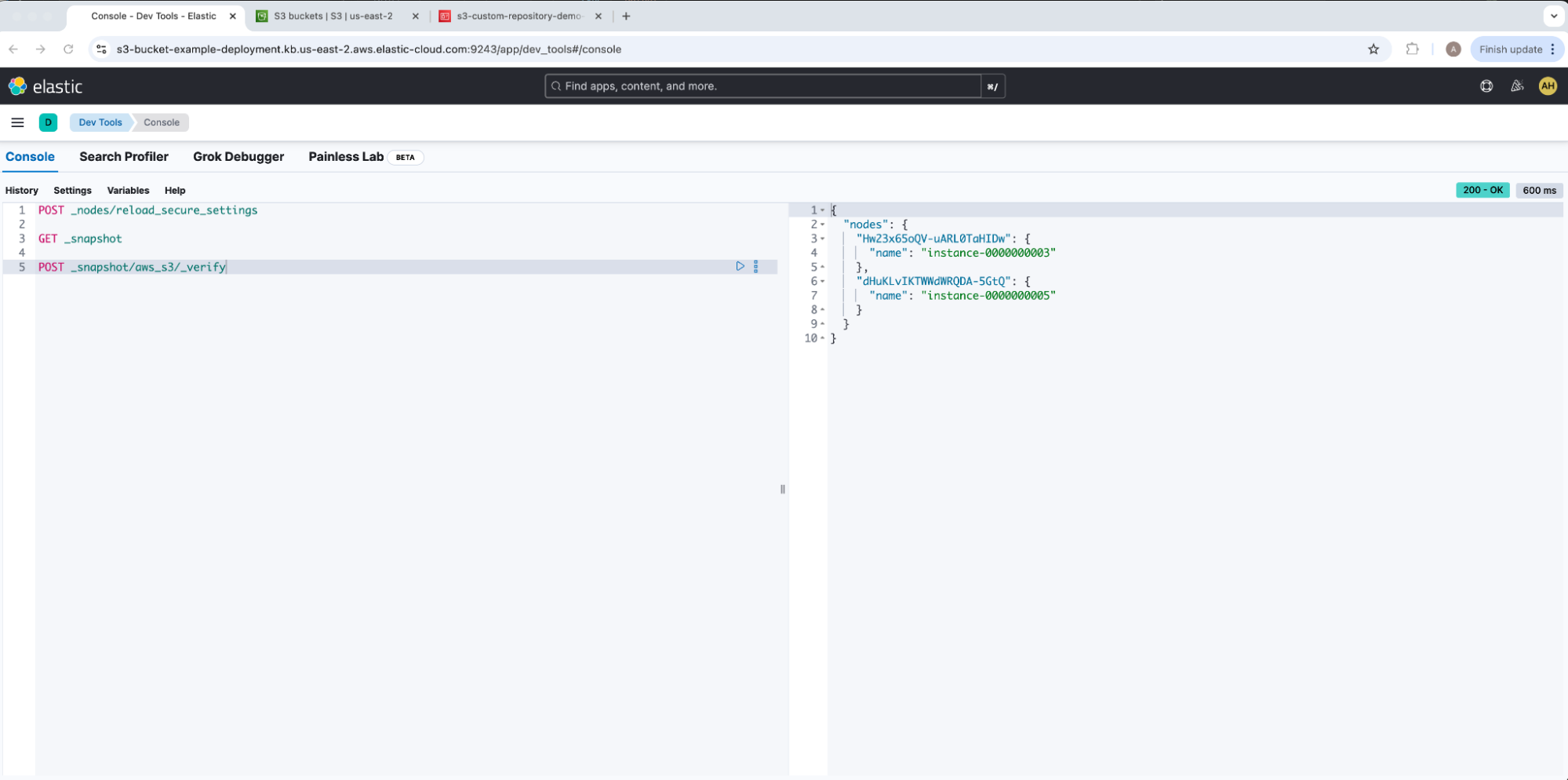
Both of these outputs return the same list of nodes successfully connected to our AWS S3 bucket.
Capture snapshot
We are now ready to backup a snapshot of our committed Elasticsearch cluster into our AWS S3 bucket. Kindly note that Elastic Cloud’s built-in repository found-snapshots takes periodic backups as well via Elasticearch’s snapshot lifecycle management. We will run create snapshot.
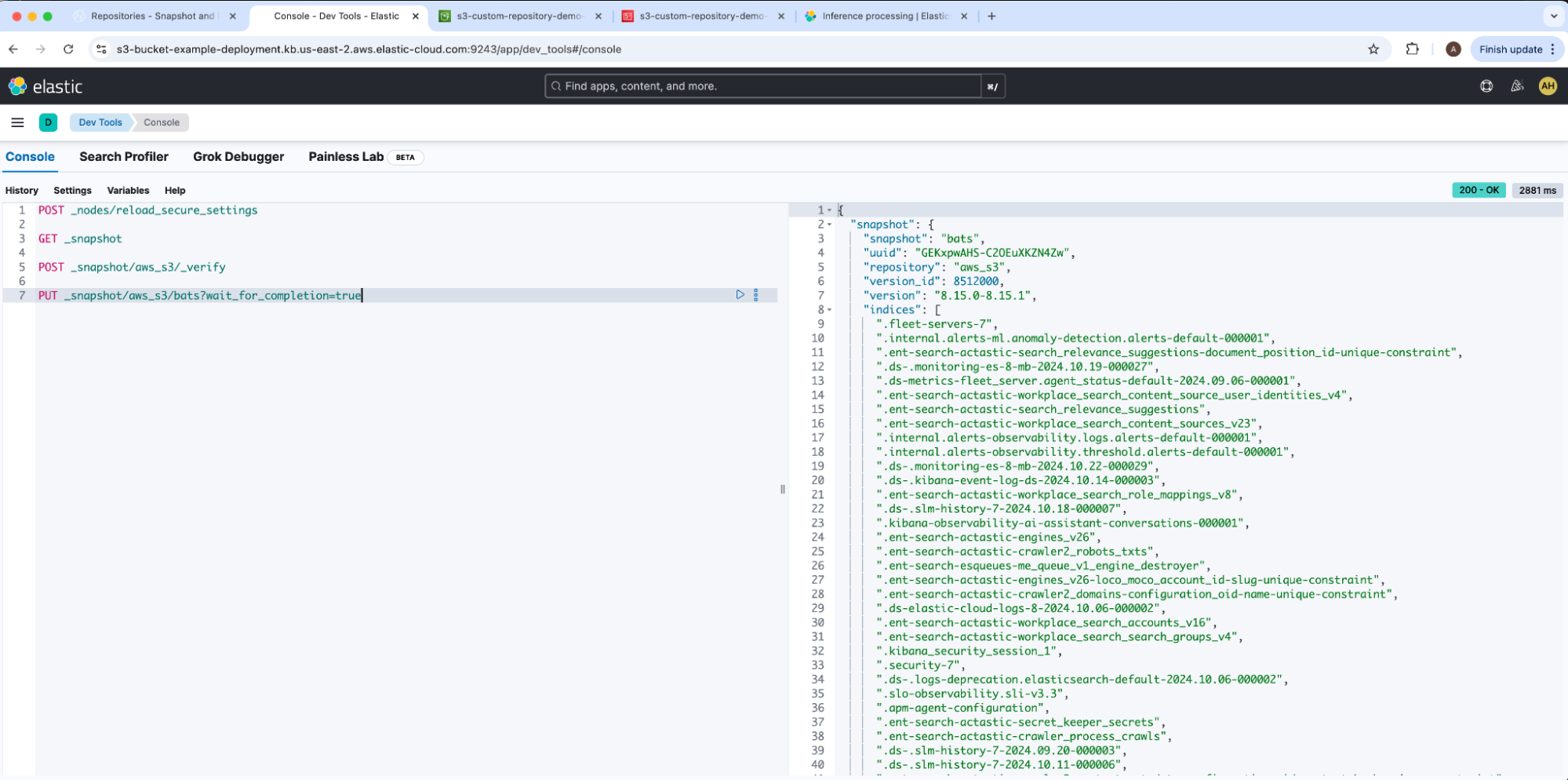
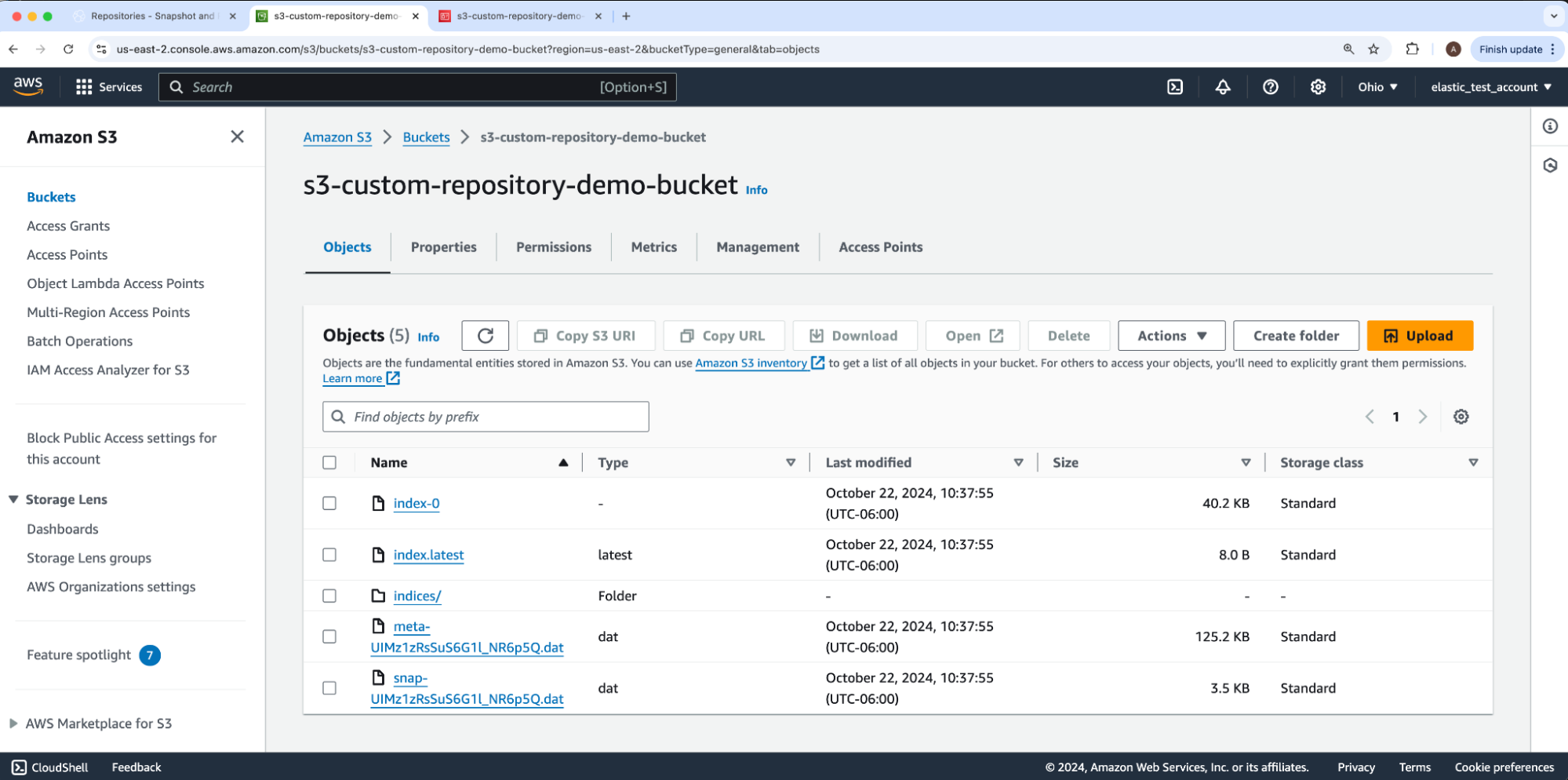
Our example snapshot name is bats. The resulting snapshot reported state: SUCCESS. We can confirm results by navigating back to our AWS S3 bucket s3-custom-repository-demo-bucket which shows Elasticsearch added files and subfolders into our root directory.
We did it! Check out this video for a walkthrough of the steps above.
As desired at this point, we can set up snapshot lifecycle management to take period snapshots and manage snapshot retention. Alternatively, we could disconnect our AWS S3 repository to connect it to a different Elasticsearch cluster to migrate this newly snapshot data.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print