Data visualization with Elasticsearch aggregations and D3
Update November 2, 2015: Please note that facets are not supported in Elasticsearch 2.0+.
For those of you familiar with Elasticsearch, you know that its an amazing modern, scalable, full-text search engine with Apache Lucene and the inverted index at its core. Elasticsearch allows users to query their data and provides efficient and blazingly fast look up of documents that make it perfect for creating real-time analytics dashboards.
Currently, Elasticsearch includes faceted search, a functionality that allows users to compute aggregations of their data. For example, a user with twitter data could create buckets for the number of tweets per year, quarter, month, day, week, hour, or minute using the date histogram facet, making it quite simple to create histograms.
Faceted search is a powerful tool for data visualization. Kibana is a great example of a front-end interface that makes good use of facets. However, there are some major restrictions to faceting. Facets do not retain information about which documents fall into which buckets, making complex querying difficult. Which is why, Elasticsearch is pleased to introduce the aggregations framework with the 1.0 release. Aggregations rips apart its faceting restraints and provides developers the potential to do much more with visualizations.
Aggregations (=Awesomeness!)
Aggregations is "faceting reborn". Aggregations incorporate all of the faceting functionality while also providing much more powerful capabilities. Aggregations is a generic but extremely powerful framework for building any type of aggregation. There are several different types of aggregations, but they fall into two main categories: bucketing and metric. Bucketing aggregations produce a list of buckets, each one with a set of documents that belong to it (e.g., terms, range, date range, histogram, date histogram, geo distance). Metric aggregations keep track and compute metrics over a set of documents (e.g., min, max, sum, avg, stats, extended stats).
Using Aggregations for Data Visualization (with D3)
Lets dive right in and see the power that aggregations give us for data visualization. We will create a donut chart and a dendrogram using the Elasticsearch aggregations framework, the Elasticsearch javascript client, and D3.
If you are new to Elasticsearch, it is very easy to get started. Visit the Elasticsearch overview page to learn how to download, install, and run Elasticsearch version 1.0.
Requirements:
- elasticsearch.js
- d3.v3.js, or include the D3 source in a script tag in the html
- require.js (save file as require.js)
- nfl_2013.json and nfl_mapping.json (download)
- a text editor
- a webserver
* a link to the index.html and main javascript file can be found here. Alternatively, you can clone the project on github.
Uploading Data to our Elasticsearch Index
We will need to create an index and add some data.
Since the (American) football season just ended, let's send it off by exploring some NFL data. For this tutorial, we will only be concerned with touchdowns. Download the dataset (nfl_2013.json) and its mappings (nfl_mapping.json) using the link above.
Fire up Elasticsearch from your localhost. Now, let's add an index and some data. From the terminal:
curl -XPOST localhost:9200/nfl?pretty
curl -XPUT localhost:9200/nfl/2013/_mapping?pretty -d @nfl_mapping.json
curl -XPOST localhost:9200/nfl/2013/_bulk?pretty --data-binary @nfl_2013.json
The NFL data file consists of play-by-play data with 18 fields.
{
def: "HOU", // defensive team
defscore: "13", // score for defensive team
description: "(11:34) S.Ridley right guard for 8 yards TOUCHDOWN.", // play description
down: "2", // down for current play (up to 4)
gameid: "20130113_HOU@NE", // game id with date and teams
min: "26", // minutes remaining in game
nextscore: "7", // ???
off: "NE", // offensive team
offscore: "17", // score for offensive team
qtr: "3", // quarter
scorechange: "0", // amount offensive score changed
scorediff: "4", // difference in score
season: "2012", // nfl season (year)
sec: "34", // seconds remaining within minute of play
series1stdn: "1", // ???
teamwin: "1", // either 1 or 0, demarks the team winning
togo: "6", // number of yards to go to reach a first down
ydline: "8" // yard line ball is on to start play
}
Setting up our HTML and Javascript Files
Lets begin by creating a directory for our project. Lets call it nfl. Now add index.html and a scripts subdirectory. Within scripts, place our downloaded elasticsearch.js, d3.js, and require.js files. We will also create our main.js file within scripts.
Let's add some markup to index.html.
<!DOCTYPE html>
<html>
<head>
<title>Elastic Aggregations</title>
<script src="scripts/require.js"></script>
<script>require(["scripts/main"], function () {})</script>
<style></style>
</head>
<body>
<div id="donut-chart"></div>
</body>
</html>
Now, let's add some javascript to main.js.
define(['scripts/d3.v3', 'scripts/elasticsearch'], function (d3, elasticsearch) {
"use strict";
var client = new elasticsearch.Client();
});
Donut Chart with Terms Aggregation
Let's start by making a donut chart of the number of touchdowns scored in each quarter. We will use the terms aggregation to accomplish this. The same thing can be done using the terms facet, but this will demonstrate how aggregations can accomplish the same things as facets.
Since there are typically only 4 quarters in an NFL game, we should end up with a donut chart with 4 slices. To ensure that we only return 4 quarters we will filter out overtime quarters. We will also need to filter for touchdowns.
So lets create our query using the Elasticsearch javascript client and add it to main.js.
define(['scripts/d3.v3', 'scripts/elasticsearch'], function (d3, elasticsearch) {
"use strict";
var client = new elasticsearch.Client();
client.search({
index: 'nfl',
size: 5,
body: {
// Begin query.
query: {
// Boolean query for matching and excluding items.
bool: {
must: { match: { "description": "TOUCHDOWN" }},
must_not: { match: { "qtr": 5 }}
}
},
// Aggregate on the results
aggs: {
touchdowns: {
terms: {
field: "qtr",
// order by quarter, ascending
order: { "_term" : "asc" }
}
}
}
// End query.
}
}).then(function (resp) {
console.log(resp);
// D3 code goes here.
});
});
If we fire up a webserver, open up our browser, and navigate to the console under developer tools, you should see the output. Voila, data!
Now, let's create a donut chart. Add your donut chart d3 code to main.js.
...
}).then(function (resp) {
console.log(resp);
// D3 code goes here.
var touchdowns = resp.aggregations.touchdowns.buckets;
// d3 donut chart
var width = 600,
height = 300,
radius = Math.min(width, height) / 2;
var color = ['#ff7f0e', '#d62728', '#2ca02c', '#1f77b4'];
var arc = d3.svg.arc()
.outerRadius(radius - 60)
.innerRadius(120);
var pie = d3.layout.pie()
.sort(null)
.value(function (d) { return d.doc_count; });
var svg = d3.select("#donut-chart").append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", "translate(" + width/1.4 + "," + height/2 + ")");
var g = svg.selectAll(".arc")
.data(pie(touchdowns))
.enter()
.append("g")
.attr("class", "arc");
g.append("path")
.attr("d", arc)
.style("fill", function (d, i) { return color[i]; });
g.append("text")
.attr("transform", function (d) { return "translate(" + arc.centroid(d) + ")"; })
.attr("dy", ".35em")
.style("text-anchor", "middle")
.style("fill", "white")
.text(function (d) { return d.data.key; });
});
});
Let's add some styling to index.html.
<style>
body {
font: 14px sans-serif;
}
.arc path {
stroke: #fff;
stroke-width: 3px;
}
</style>
Refresh your page in the browser, and you should see a nice donut chart.
Of course, you can create the same donut chart using a terms facet, no surprises here. So, let's try something a bit more complex.
Dendrogram with Nested Terms Aggregations
Let's say we want to know for the 2013 season (through the 12th week), for each team, the name of the player(s) who scored touchdowns and the total number of touchdowns they scored in each quarter. For example, for the Denver Broncos (an NFL team), Peyton Manning (a player) was responsible for 36 touchdowns with:
- 9 touchdowns in the 1st qtr
- 6 touchdowns in the 2nd qtr
- 12 touchdowns in the 3rd qtr
- 9 touchdowns in the 4th qtr
Let's write this query. We will need to filter out incomplete passes, interceptions, fumbles, and over-turned plays to get a more accurate number.
define(['scripts/d3.v3', 'scripts/elasticsearch'], function (d3, elasticsearch) {
"use strict";
var client = new elasticsearch.Client();
client.search({
index: 'nfl',
size: 5,
body: {
query: {
bool: {
must: { match: { "description": "TOUCHDOWN"}},
must_not: [
{ match: { "description": "intercepted"}},
{ match: { "description": "incomplete"}},
{ match: { "description": "FUMBLES"}},
{ match: { "description": "NULLIFIED"}}
]
}
},
aggs: {
teams: {
terms: {
field: "off",
exclude: "", // exclude empty strings.
size: 5 // limit to top 5 teams (out of 32).
},
aggs: {
players: {
terms: {
field: "description",
include: "([a-z]?[.][a-z]+)", // regex to pull out player names.
size: 20 // limit to top 20 players per team.
},
aggs: {
qtrs: {
terms: {
field: "qtr"
}
}
}
}
}
}
}
}
}).then(function (resp) {
console.log(resp);
// D3 code goes here.
});
});
You can check the results in the console.
* Note that the team nodes have a touchdown count that is less than the sum of its leaf nodes. This is because touchdowns that resulted from passes are counted twice, once for the player catching the pass and once for the quarterback (e.g. Peyton Manning) throwing the pass.
Let's create our dendrogram. We will modify index.html.
...
<body>
<div id="donut-chart"></div>
<div id="dendrogram"></div>
</body>
...
Add your d3 code to main.js.
...
}).then(function (resp) {
console.log(resp);
// D3 code goes here.
var root = createChildNodes(resp);
// d3 dendrogram
var width = 600,
height = 2000;
var color = ['#ff7f0e', '#d62728', '#2ca02c', '#1f77b4'];
var cluster = d3.layout.cluster()
.size([height, width - 200]);
var diagonal = d3.svg.diagonal()
.projection(function(d) { return [d.y, d.x]; });
var svg = d3.select("#dendrogram").append("svg")
.attr("width", width)
.attr("height", height)
.append("g")
.attr("transform", "translate(120,0)");
var nodes = cluster.nodes(root),
links = cluster.links(nodes);
var link = svg.selectAll(".link")
.data(links)
.enter().append("path")
.attr("class", "link")
.attr("d", diagonal);
var node = svg.selectAll(".node")
.data(nodes)
.enter().append("g")
.attr("class", "node")
.attr("transform", function(d) { return "translate(" + d.y + "," + d.x + ")"; });
node.append("circle")
.attr("r", 4.5)
.style("fill", function (d) {
return d.children ? "#ffffff" : color[d.key - 1];
})
.style("stroke", function (d) {
return d.children ? "#4682B4" : color[d.key - 1];
});
node.append("text")
.attr("dx", function(d) { return d.children ? -8 : 8; })
.attr("dy", 3)
.style("text-anchor", function(d) { return d.children ? "end" : "start"; })
.text(function(d) { return d.children? d.key : d.key + ": " + d.doc_count; });
d3.select(self.frameElement).style("height", height + "px");
function createChildNodes(dataObj) {
var root = {};
root.key = "NFL";
root.children = dataObj.aggregations.teams.buckets;
root.children.forEach(function (d) { d.children = d.players.buckets; });
root.children.forEach(function (d) {
d.children.forEach(function (d) {
d.children = d.qtrs.buckets;
});
});
return root;
}
});
...
And finally, let's add the styling.
<style>
...
.node circle {
fill: #fff;
stroke: steelblue;
stroke-width: 1.5px;
}
.node {
font: 10px sans-serif;
}
.link {
fill: none;
stroke: #ccc;
stroke-width: 1.5px;
}
</style>
Refresh your browser and voila, dendrogram goodness!
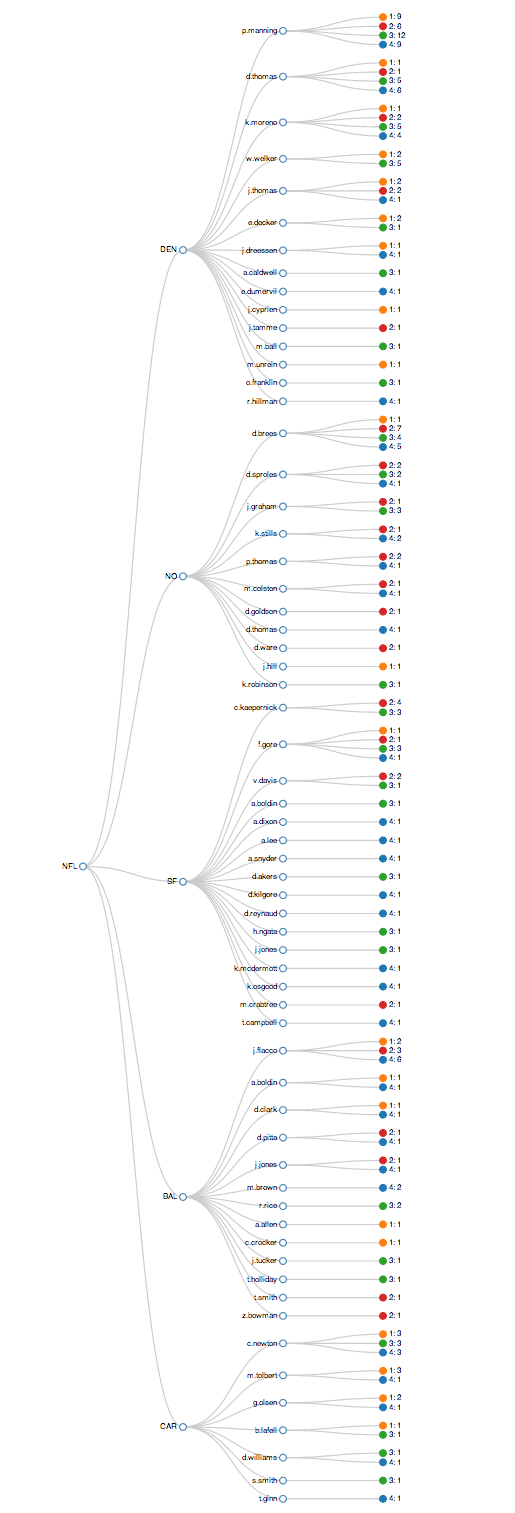
As you can see, aggregations are a powerful tool for creating visualizations. Of course, you can create much more rich and interactive visualizations than what we have created here, but hopefully this will get you started. Happy searching!