Detecting rare and unusual processes with Elastic machine learning
In SecOps, knowing which host processes are normally executed and which are rarely seen helps cut through the noise to quickly locate potential problems or security threats. By focusing attention on rare anomalies, security teams can be more efficient when trying to detect or hunt for potential threats. Finding a process that doesn’t often run on a server can sometimes indicate innocuous activity or could be an indication of something more alarming. It is important to not only have a methodical approach to identifying rare processes, but also a process for analyzing whether the rare process is benign or alarming.
In this blog, we’ll break down when to classify host process execution as truly rare, and how to identify such anomalies using detection jobs in both the Machine Learning app in Kibana and Elastic Security. We’ll also show a demo of how to investigate rare anomalies using Elastic Security.
Determining rarity
What types of process executions should we consider rare? And how can we indicate how rare they are? Message volume and rarity are not the same thing. If a cron job runs a monthly process, the volume of messages will be low, but it shouldn’t be considered rare. On the other hand, when a new, never-before-seen process creates a spike in messages, it might not be the process with the fewest log messages, but it should still be considered rare.
In typical environments, you will find rare processes, and it is important to prioritize the most unusual ones. By assigning a severity score for how rare a process is on a host, we can use that score to prioritize the rare processes across all of our hosts. If that process is new and hasn’t been seen before, then it should be scored higher. If, however, it has occurred periodically before, it should have a lower score.
To determine rarity, we can use Elastic’s unsupervised machine learning to build a time series model that can learn as data is collected to highlight and score rare processes based on how unusual they are in our environment. Elastic’s machine learning has a rare function built into its anomaly detection engine that detects values that are rare in time. In my previous blog, I explained how to use the rare function in the Machine Learning app to detect and score rare entities. Here, we’ll walk through the specific use case of looking for a rare process on our hosts.
Elastic makes creating machine learning jobs easy by providing out-of-the-box templates for common scenarios like rare processes by host, but it also provides a high level of customization so that you can build to fit into any environment. There are prepackaged anomaly detection jobs for data sources like Auditbeat, Winlogbeat, the Elastic Agent, and Packetbeat. The important field that we will be building anomaly detection jobs for in the examples below will be around the Elastic Common Schema (ECS) field for the process called process.name.
Enabling anomaly detection jobs to detect rare processes in Elastic Security
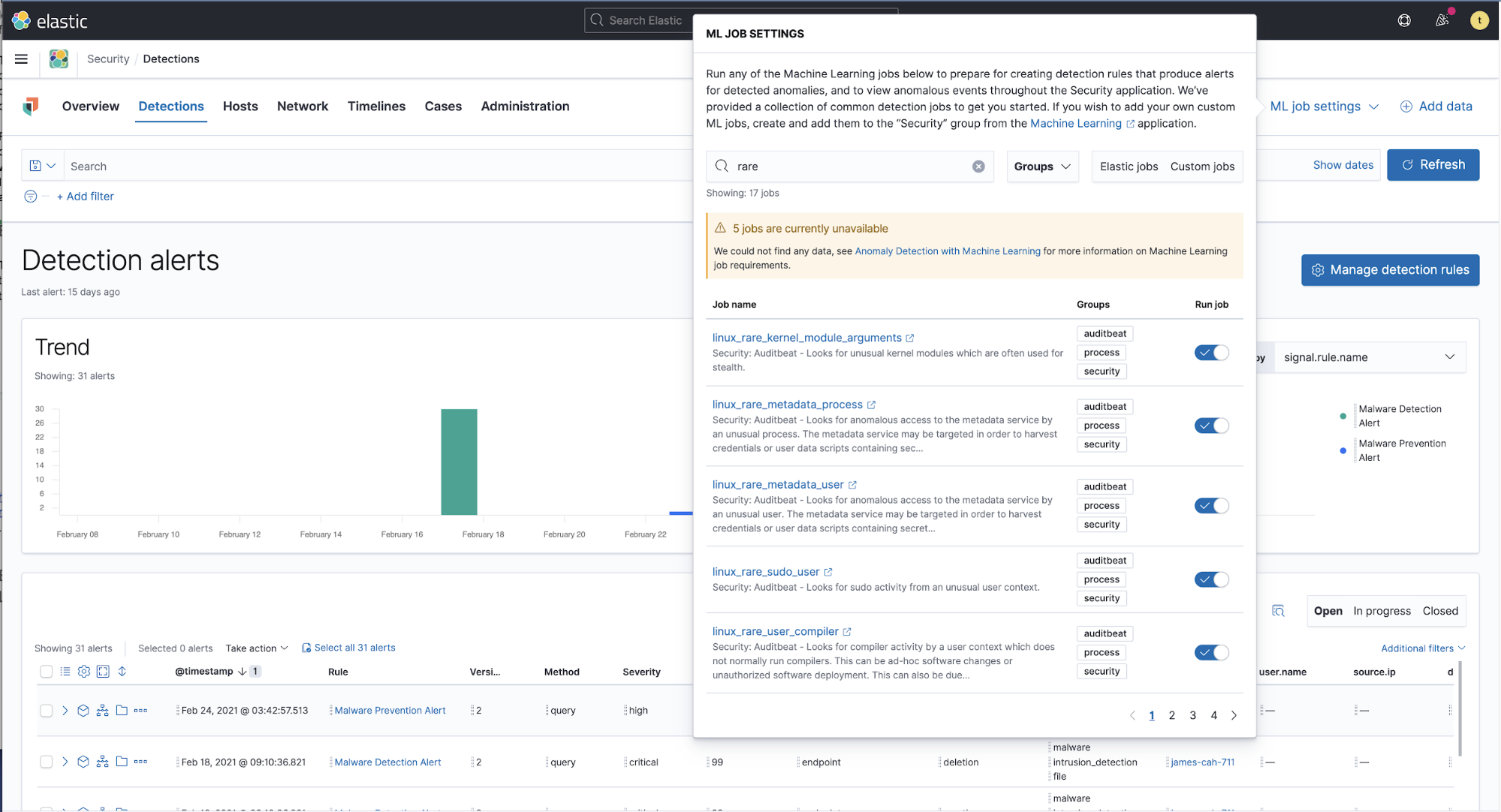
Elastic Security has several prebuilt machine learning jobs to detect rare processes. In the Security → Detections view, there is an option for ML job settings in the upper right corner that will provide a menu with supplied anomaly detection job configurations, including several for rare processes. You can enable these jobs simply by selecting the Run job switch.
Each of these jobs also has a corresponding detection rule. Activate the detection rules in question if you wish to be alerted when a machine learning job detects anomalies that meet a defined threshold.
Building an anomaly detection job to detect rare processes in the Machine Learning app
There may be situations where you might want to create your rare process anomaly detection job through the Machine Learning advanced wizard. Maybe your data source isn’t using ECS-compliant fields, or maybe your data needs to use different bucket spans for indicating rarity. The advanced wizard in the Machine Learning app gives you more options when building out your anomaly detection job — and you can still view the results in Elastic Security if you add the Security label to the job.
When building your own customized anomaly detection job for rare analysis, you can get started quickly using the advanced wizard. Below is a list of questions and considerations you should be ready for before you build your anomaly detection job:
- In which index or data stream is the process field located? You don’t have to use the entire index — you can use a saved search to filter the data feed for your machine learning job.
- What is the name of the field for your rare analysis?
- Is there a partitioning field you want to use? For example if you want to separate the processes by host name, then you should use the host name field for the
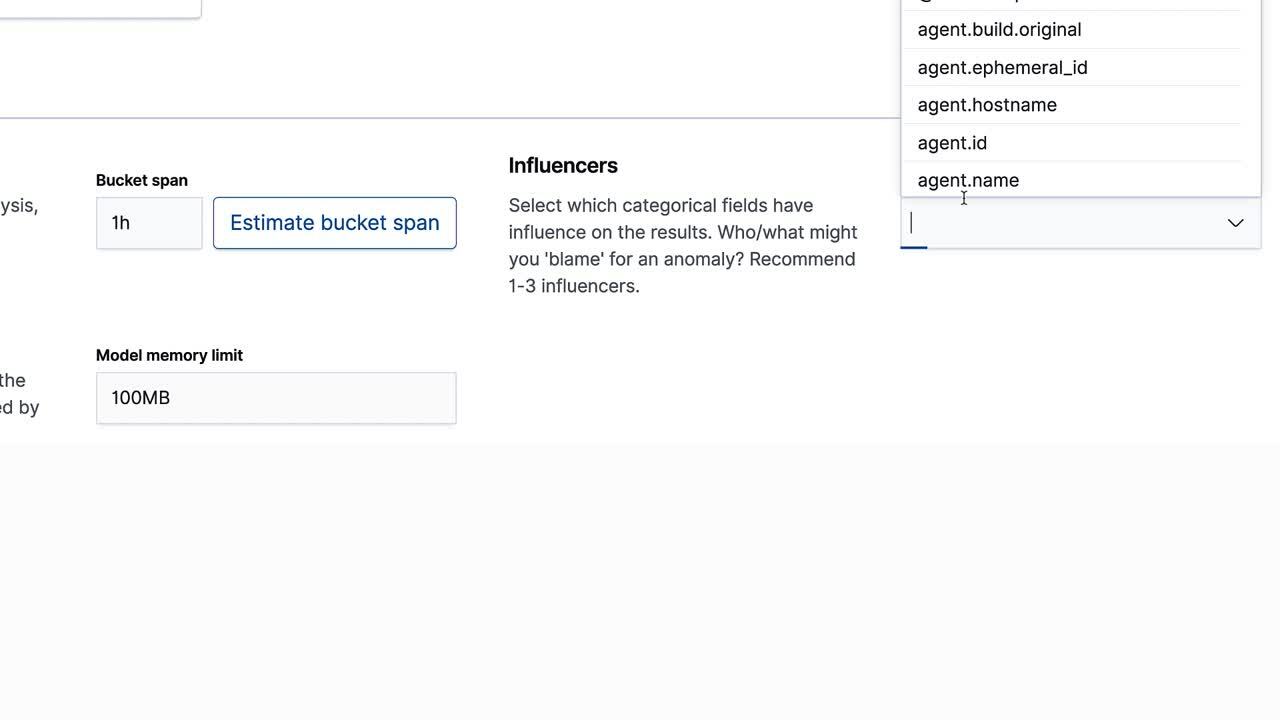
byfield. - Select some influencing fields that you would like to identify as reasons that might cause a rare process.
- Select the bucket time length for the model. As we showed in the previous blog, the rare function is especially sensitive to bucket time.
- Select groups to put the job into so it can be viewed alongside other anomaly detection jobs in that same group. By adding the
Securitylabel to the results, they will appear in Elastic Security.
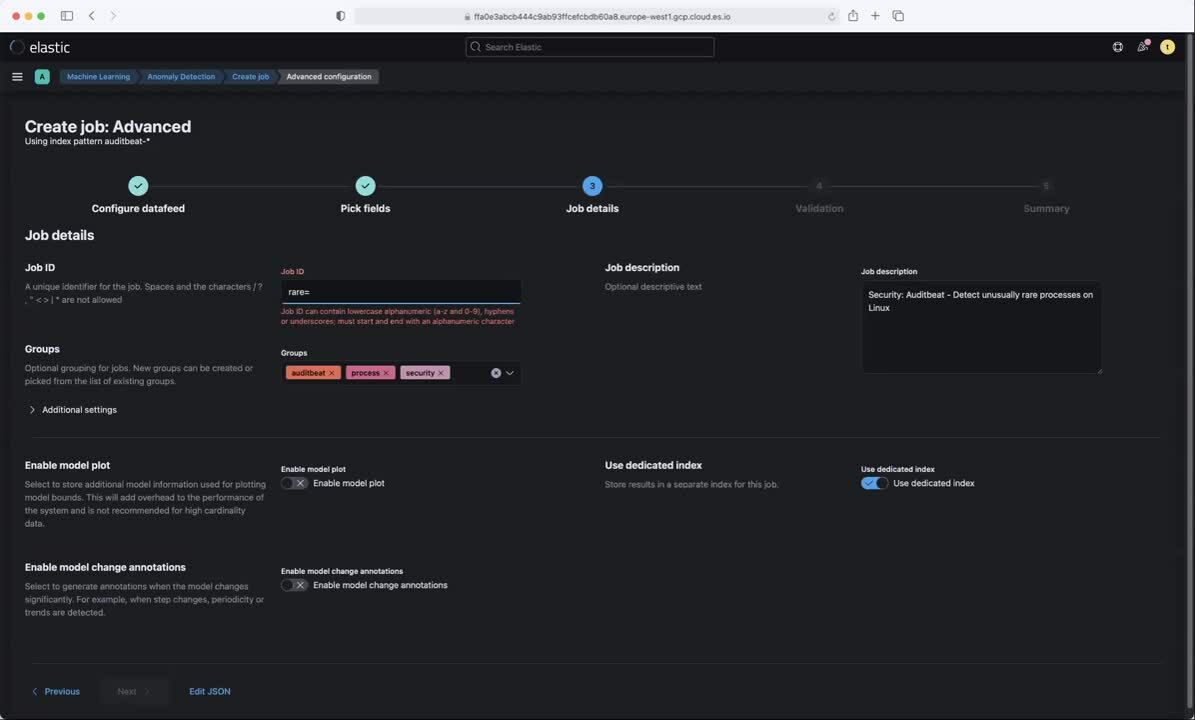
Here is a walkthrough of how to create an anomaly detection job for detecting unusual processes per host in Winlogbeat data:
Investigating rare events in Elastic Security
Once you have configured an anomaly detection job to detect rare or unusual processes, you can then use the results you get from those ML jobs to investigate further and provide feedback to the system to filter out innocuous rare events and share important information about potential threats with other users.
Here's a quick demo of creating a rare anomaly detection job and investigating the results within Elastic Security:
Conclusion
Elastic Security has many out-of-the-box machine learning configurations for detecting rare activity, networks, and processes, and it's easy to get up and running quickly with default templates. Additionally, if you want to add your own configuration because you want to change the time bucket span or the fields you use to reference the process or influencing fields, Elastic also provides the tools to customize your own anomaly detection jobs.
The goal of anomaly detection is to let the algorithms model what is normal and use that model to detect unusual or rare data. It is not enough to count the least number of values because they might be normal — it is much better to build a model of what is normal and highlight what is abnormal.
Furthermore, it is not enough to simply detect rare events. It is also important to provide a path to investigate those rare events and provide a feedback loop to indicate whether the unusual process was a security threat or a normal event.
You can accomplish a lot with Elastic. Start your free 14-day trial (no credit card required) or download our products, free, for your on-prem deployment. And take advantage of our Quick Start training to set yourself up for success.