_(1).png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Hello from the Elastic DevRel team! In this newsletter blog, you’ll find information on upcoming Elastic meetups and events in your region, catch up on product updates and content, and stay up-to-date with everything Elastic-related. In this edition, we dive into Elasticsearch and the Elastic Stack 8.15.
What’s new?
Elasticsearch and the Elastic Stack 8.15 are available
Semantic text: Elasticsearch 8.15 makes it easier to set up semantic search with the new semantic_text field type, covering both sparse and dense vector search. It helps you split incoming text into chunks, create embeddings, and manage both indexing and querying. You can also connect third-party inference model providers, such as OpenAI, Hugging Face, Mistral AI, Amazon Bedrock, Google AI studio, and more. Elasticsearch will handle the embedding generation during indexing. When processing documents, they're divided into chunks of 250 words each with a 100-word overlap with additional combinations planned for the future. This overlap ensures that important context isn't lost at the break between chunks.

Logs data stream and LogsDB index mode: A logs data stream is a specialized data stream type designed for more efficient storage of log data, similar to the time series data stream for metrics. In our benchmarks it can reduce the disk space usage by 2.5x over regular data streams, though the exact savings depend on the specific data set.
Key features of a logs data stream include:
Synthetic source: The _source field occupies a significant amount of disk space. Instead of storing the documents exactly as requested, Elasticsearch can reconstruct source content from indexed fields on the fly upon retrieval. Synthetic source is now also available on all field types.
Index sorting: Reduces storage footprint by sorting indices by host.name and @timestamp at index time.
Space-efficient compression: Applies more efficient compression for fields with doc_values enabled.
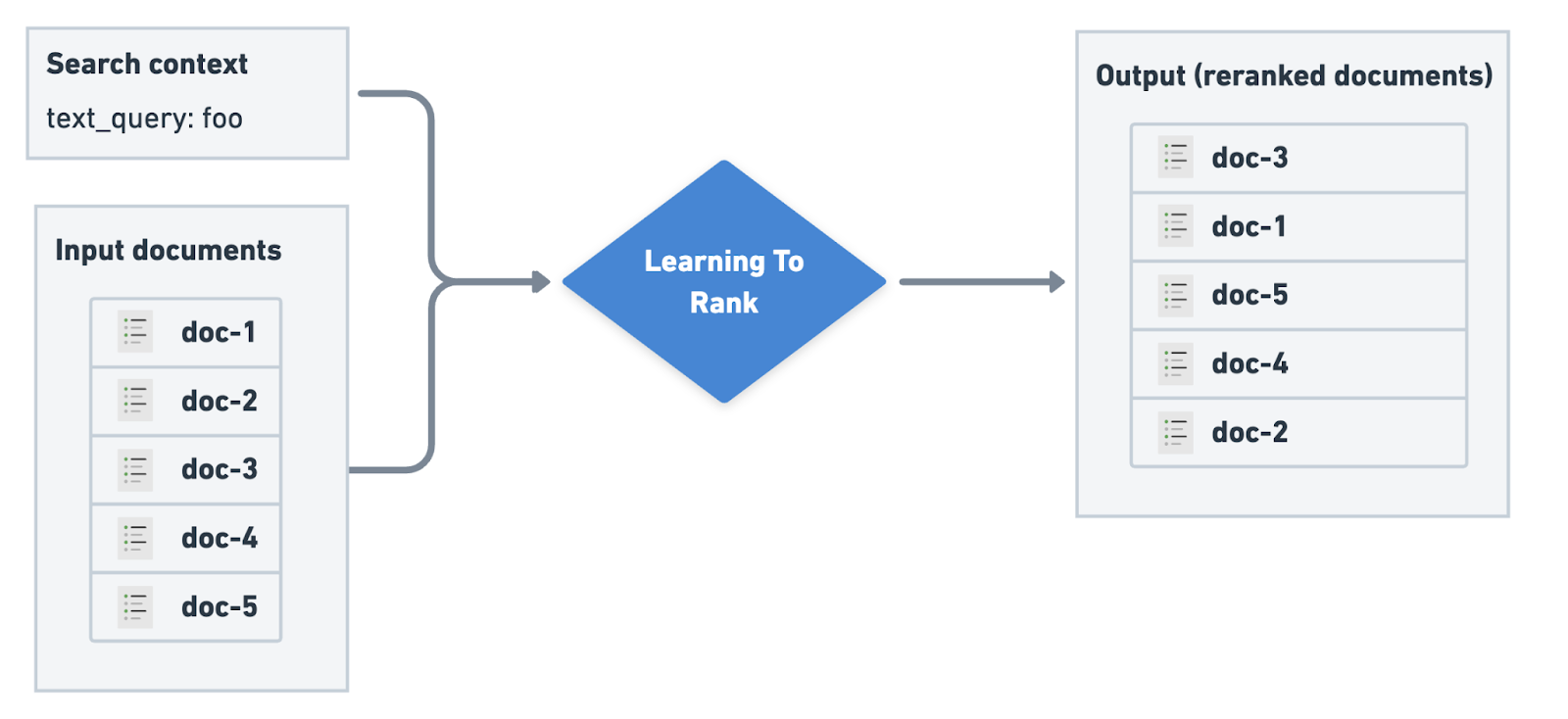
Elasticsearch's native Learning to Rank (LTR) is generally available: Learning to Rank is a technique that improves relevance by using a machine learning (ML) model to re-rank search results. Typically, LTR is applied after an initial retrieval stage, refining the results based on a search context and a judgment list. The search context includes user queries and potentially other user-related data while the judgment list is a data set of query-document pairs labeled with relevance scores, which is used to train the model. The ML model, often a Gradient Boosted Decision Tree (GBDT) like LambdaMART, ranks documents based on features extracted from the query and documents.
Vector database enhancements:
Save 8x memory (over float) with int4 quantization: To save memory, Elasticsearch uses bit shift operations to pack these small values into a single byte, doubling the space savings compared to int8. Overall, storing int4 with this bit compression makes it 8x smaller than float.
Bit vector support: As the name suggests, bit vectors consist of vectors where each dimension is represented by a single bit. Compared to vectors using float values, bit vectors offer an impressive 32x reduction in size. To compute the similarity, it uses hamming distance between vectors.
Lucene 9.11: Besides general improvements in memory management, the latest Lucene release speeds up multi-segment HNSW graph search for nested kNN queries and optimizes scoring without copying on-heap vectors.
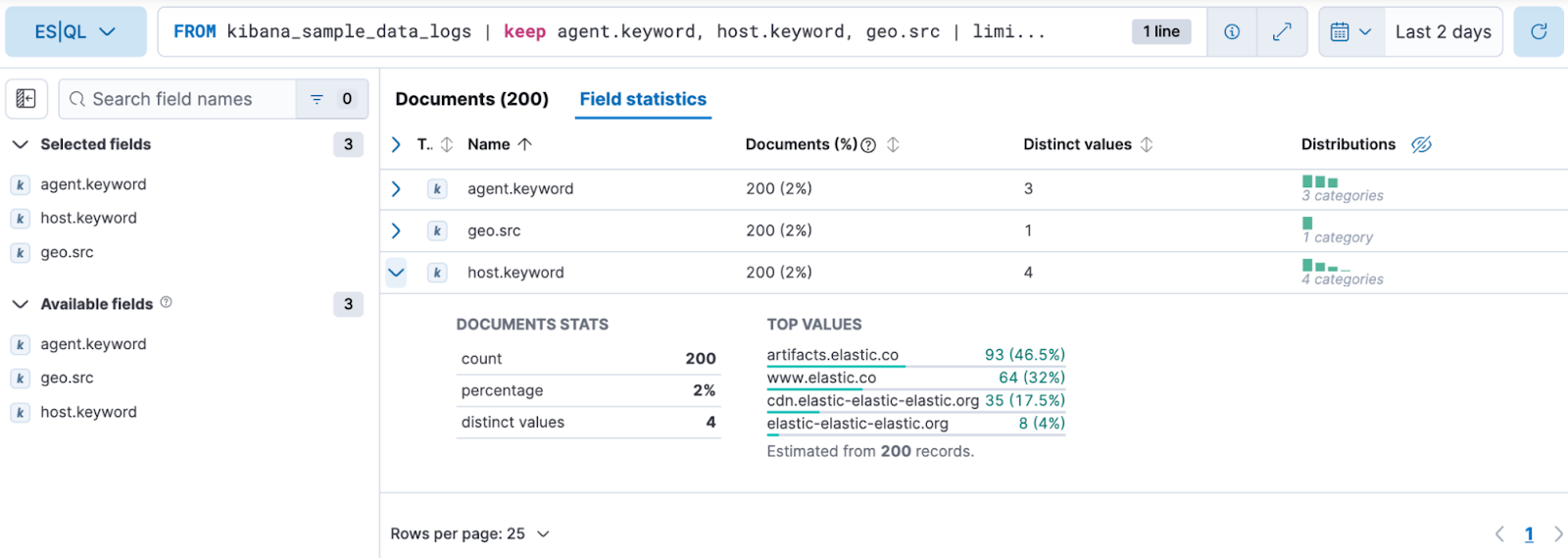
Field statistics in ES|QL: Field statistics are now available in ES|QL. This feature is designed to provide comprehensive insights for each data field. With this enhancement, you can access detailed statistics, such as distributions, averages, and other key metrics, helping you quickly understand your data. You can also embed field statistics in Dashboards, so you don’t have to switch back and forth with Discover while exploring the data.
And much more — see the full release notes.
Blogs, videos, and interesting links
Stateless Elasticsearch: Learn about the architectural changes in stateless Elasticsearch to power the Serverless offering, which is currently in technical preview:
Ingest autoscaling: Learn how ingest autoscaling works in Elasticsearch, the different components involved, and the metrics used to quantify the resources needed with Pooya Salehi, Henning Andersen, and Francisco Fernández Castaño.
Search autoscaling: Following a similar pattern, see the details of how search autoscaling works in Elasticsearch with Matteo Piergiovanni and John Verwolf.
Refresh costs: Using a cloud object store like S3 involves different tradeoffs compared to local disks in terms of latency as well as cost for each request and data transfer. Francisco Fernández Castaño and Henning Andersen show the refresh cost optimizations introduced for stateless Elasticsearch.
Thin indexing shards: Tanguy Leroux presents thin indexing shards, a new type of shard that allows storing Elasticsearch indices in a cloud object store.
More regions: Last but not least, Elastic Cloud Serverless is now available in three additional AWS regions — adding Europe (Ireland), Asia (Singapore), and the West coast of the US.
Kibana and Vega visualizations: Carly Richmond walks through how to build advanced dashboard visualizations on Elasticsearch data using Kibana and Vega.
RAG security: Srikanth Manvi explains how to protect sensitive and PII information in RAG with Elasticsearch and LlamaIndex.
OpenTelemetry: Integrate OpenTelemetry with Elastic Observability for application and infrastructure monitoring solutions with Ishleen Kaur.
Data tiering: Michael Calizo and Tim Lee explain how organizations with large amounts of data can optimize how it is stored across different tiers to gain cost savings and derive more value from their data.
Multilingual RAG: Build a multilingual RAG application using Elastic and Mixtral 8x22B model with Gustavo Llermaly.
Elastic Contributor Program: Discover insider tips from Elastic Gold Contributors Wagner Souza, Tomasz Dzierżanowski and Jeevanandham Selvaraj brought to you by Ully Sampaio.
Check out these videos:
Explore how to induce and troubleshoot Elastic Cloud's error "Some instances were unable to start properly” with Stef Nestor and Annie Hansen.
Learn how to use Elasticsearch to add powerful full-text search functionality to your Golang application in codeHeim’s video.
Watch OpenTelemetry - The universal observability umbrella with Elastic by Abhinav Kapoor.
Featured blogs from the community:
Liza Katz demonstrates how to create blazing fast reports with Elastic transforms and ES|QL.
Aditya Singh showcases how to find missing documents between two indices.
Abhinav Gunti created a getting started with Elasticsearch guide for beginners.
Learn about the Elasticsearch version_conflict_engine_exception with Chin Ming Jun.
- Safak Eren Saydır explains how to monitor server logs using the Elastic Stack.
Upcoming events
Americas
Meetup in Los Angeles: Kibana's ES|QL For The Win! Joint Meetup with LA DevOps — August 22
Meetup in Rio de Janeiro: Elastic & Tech in Rio: Esquenta DevOpsDays Rio 2024 — August 22
Rio de Janeiro: DevOpsDays Rio 2024 — August 24
Meetup in New York: Elastic User Group Meetup — August 28
New York: AWS Community Day — August 28
Meetup in Boston: Network Performance & Vector and Hybrid Search — August 29
Maceió: Roga DX 2024 — August 30–31
Meetup in Minas Gerais: Elastic & Tech Hub Juiz de Fora — September 3
Virtual (Spanish): 4º Meetup Elastic Latin America 2024 — September 4
Joinville: CodeCon Summit Brazil 2024 — September 6–7
Meetup in Phoenix: Scoring and Relevance in a Hybrid Search World — September 9
Meetup in San Francisco: RAG Workshop with AWS, LangChain & Elastic — September 9
San Francisco: The AI Conference — September 10–11
Florianópolis: PySul Brazil 2024 — September 13–15
Europe, Middle East, and Africa
Szczecin: 10.SJUG: Hunting with Stream Gatherers — August 22
Meetup in Stockholm: Elasticsearch Query Language (ES|QL) — August 29
Dublin: ShipItCon — August 30
London: London.JS — September 3
Oslo: Javazone 2024 — September 4-5
La Rochelle: JUG Summer Camp, Elasticsearch Query Language (ES|QL) — September 6
Meetup in Warsaw: Elasticsearch Query Language (ES|QL) — September 12
Lille: Chti’JUG, La recherche à l'ère de l'IA — September 12
Bydgoszcz: bITconf Bydgoszcz IT conference — September 13
Asia-Pacific
Meetup in Nanjing: Vector search and RAG — August 25
Meetup in Wellington: 8.15 update, observability and RAG — August 27
Meetup in Sydney: Elastic & Golang — August 29
Meetup in Chennai: Elastic Observability — August 31
Meetup in Canberra: Elastic in Canberra, we are back! — September 5
Virtual Meetup: Tooljet and Elastic — September 5
Meetup in Singapore: Elastic Observability — September 12
ElasticON Tour
Elastic's annual one-day conference series is coming to you. Join us to learn what's hot at Elastic right now, watch demos, and visit ask-me-anything booths.
Bengaluru: ElasticON — September 25
San Francisco: ElasticON — October 1
Munich: ElasticON — November 14
Amsterdam: ElasticON — November 16

Join your local Elastic meetup group for the latest news on upcoming events. If you’re interested in presenting at a meetup, send an email to meetups@elastic.co.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

