_(1).png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Hello from the Elastic DevRel team! In this newsletter, you’ll find information on upcoming Elastic meetups and events in your region, catch up on product updates and content, and stay up to date with everything Elastic-related. In this edition, we dive into Elastic Cloud Serverless and the 8.14 release for Elasticsearch and the Elastic Stack.
What’s new?
Elasticsearch and the Elastic Stack 8.14 are available
Elastic 8.14 introduces the stable release of Elasticsearch Query Language (ES|QL), a new query language designed to simplify data investigations on top of a new query engine, enhancing speed and efficiency across various data sources and structures.
.png)
Introducing Retrievers: Retrievers are a new abstraction layer added to the search API in Elasticsearch. They allow you to configure multi-stage retrieval pipelines within a single _search API call like fetching 1,000 documents with keyword search and then reranking it with vector search. This architecture simplifies the search logic in your application by eliminating the need for multiple Elasticsearch API calls for complex search queries. It also reduces the need for client-side logic that’s often required to combine results from multiple queries. Retrievers support three types: standard, kNN, and RRF.
Universal Profiling for .NET is now supported alongside all major languages like PHP, Python, Java (or any JVM language), Go, Rust, C/C++, Node.js/V8, Ruby, Perl, and Zig. This is the first of its kind to profile .NET versions 6, 7, and 8 without instrumentation using an eBPF-based profiler.
Generative AI Attack Discovery feature enhances the detection and understanding of complex attack patterns by combining search and retrieval augmented generation (RAG) to provide results that matter. Attack Discovery transforms a flood of alerts into a clear and comprehensive overview of attack progressions, enabling teams to respond to cyber threats with exceptional precision and speed.
Start RAG in minutes: A new Playground and Dev Console with Jupyter notebooks are parts of Kibana that allow you to experiment, refine, and iterate quickly. In the Playground, you can work with multiple indices (including various third-party data sources) to refine semantic text queries, export code, and design conversational search experiences. This simplifies RAG and enables rapid prototyping of chat experiences with Elasticsearch data.
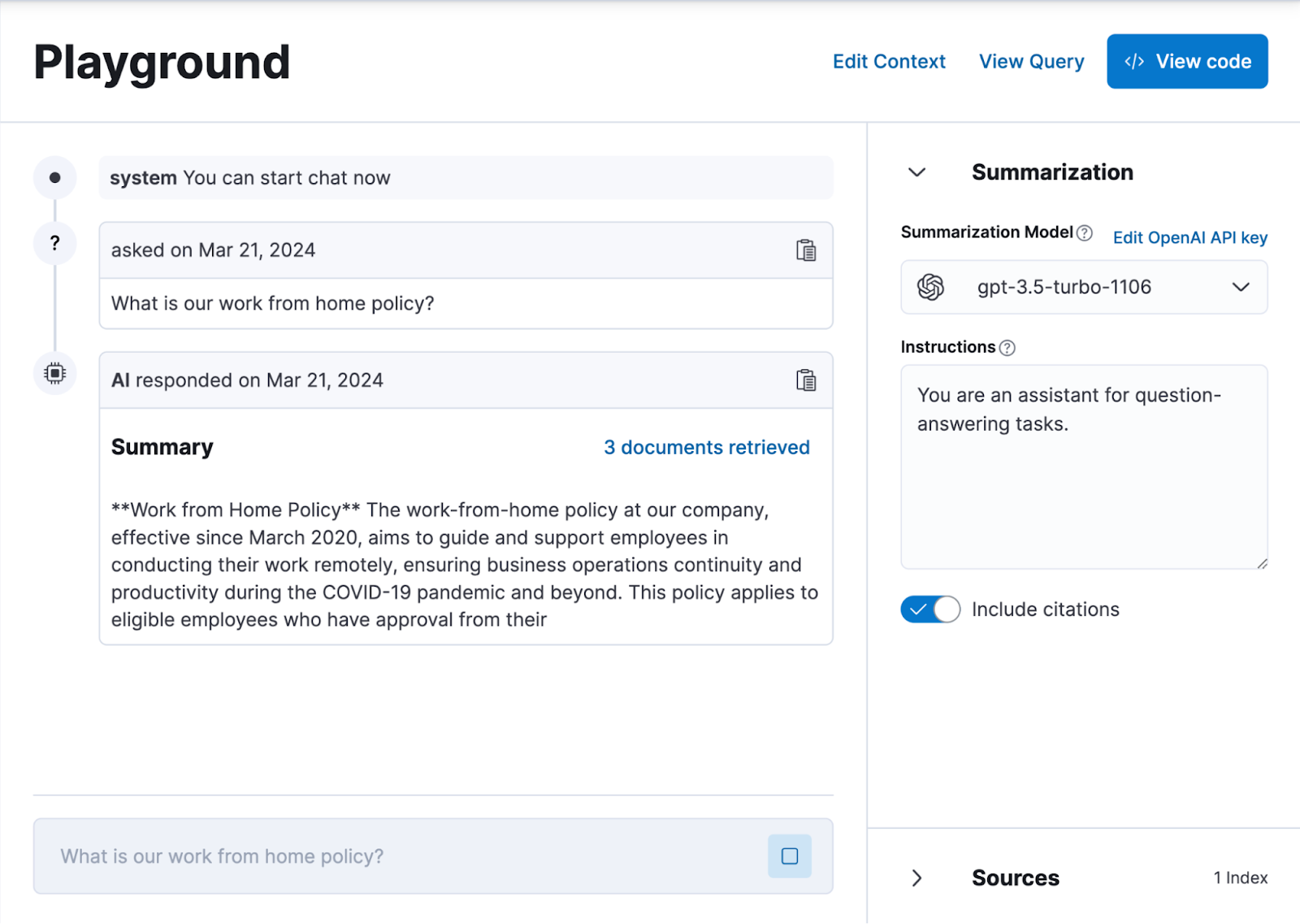
Faster vector search:
int8 quantization is enabled by default for dense vector fields, reducing the (off-heap) memory requirement by 75%.
Vector distance functions are optimized for int8 vectors on the ARM AArch64 architecture. Using native code for vector comparisons and segment merging of int8 vectors has become several times faster than it was.
See all of the improvements combined in a benchmark blog post using 138 million documents with 1024-dimensional vectors.
And much more — see the full release notes:
In Kibana’s Discover you can compare documents like diffing SIP messages of a certain ID.
Logstash support on ECK — Elastic’s Kubernetes Operator — went GA.
Add user information to the slow log.
Pass model_text and model_id within a kNN query in the Query DSL to convert a text query into a dense vector.
Upgrade straight to Elastic Stack 8.14.1: 8.14.0 has fixed a couple of security issues. Upgrade to the latest release 8.14.1 today, which also includes a couple of additional bug fixes.
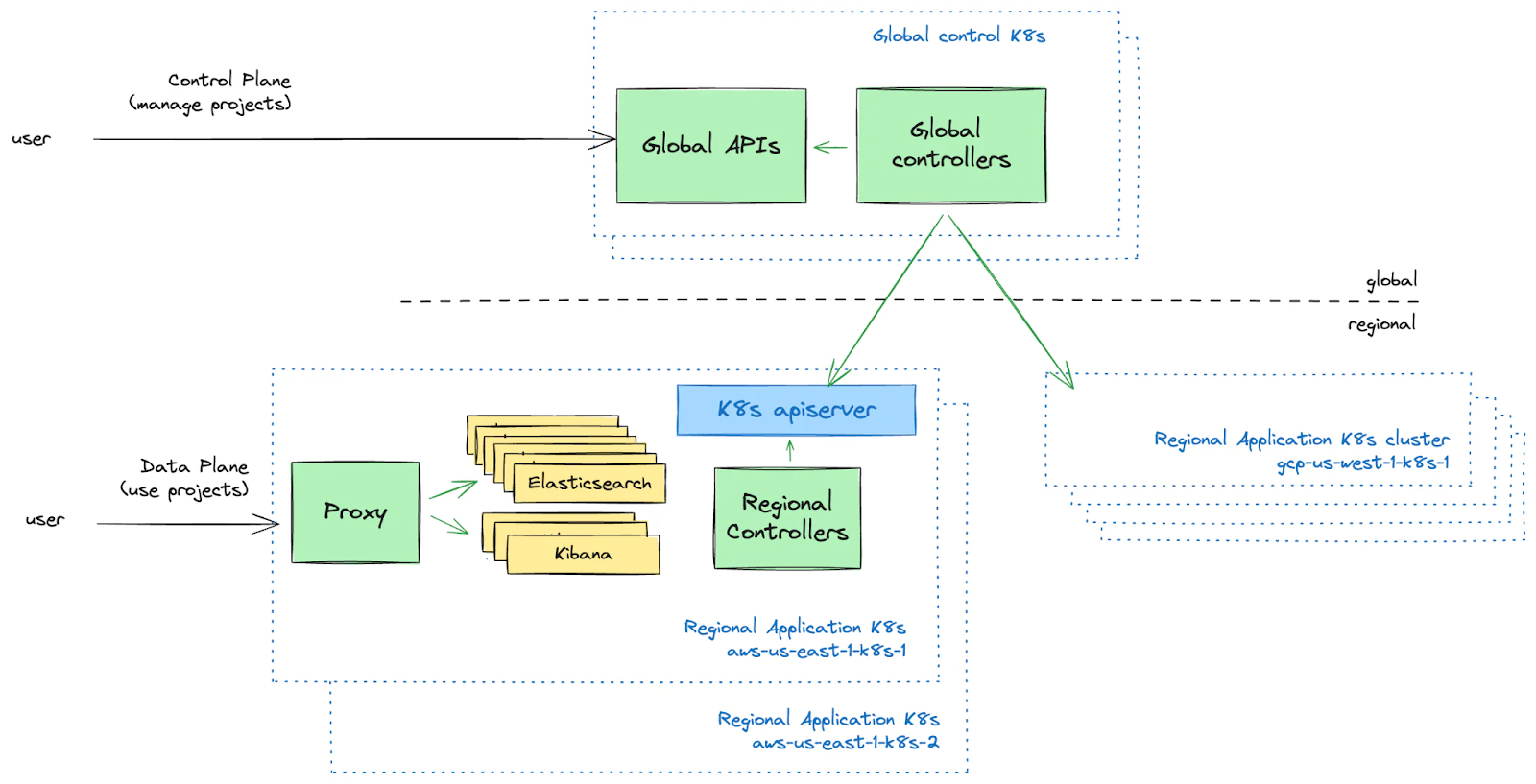
Elastic Cloud Serverless: Elasticsearch Serverless is available as a technical preview, adding an additional deployment option to Elastic Cloud: we will take care of nodes, shards, and versions for you while you can pick a project type — Elasticsearch, Observability, or Security — with streamlined onboarding and pricing.
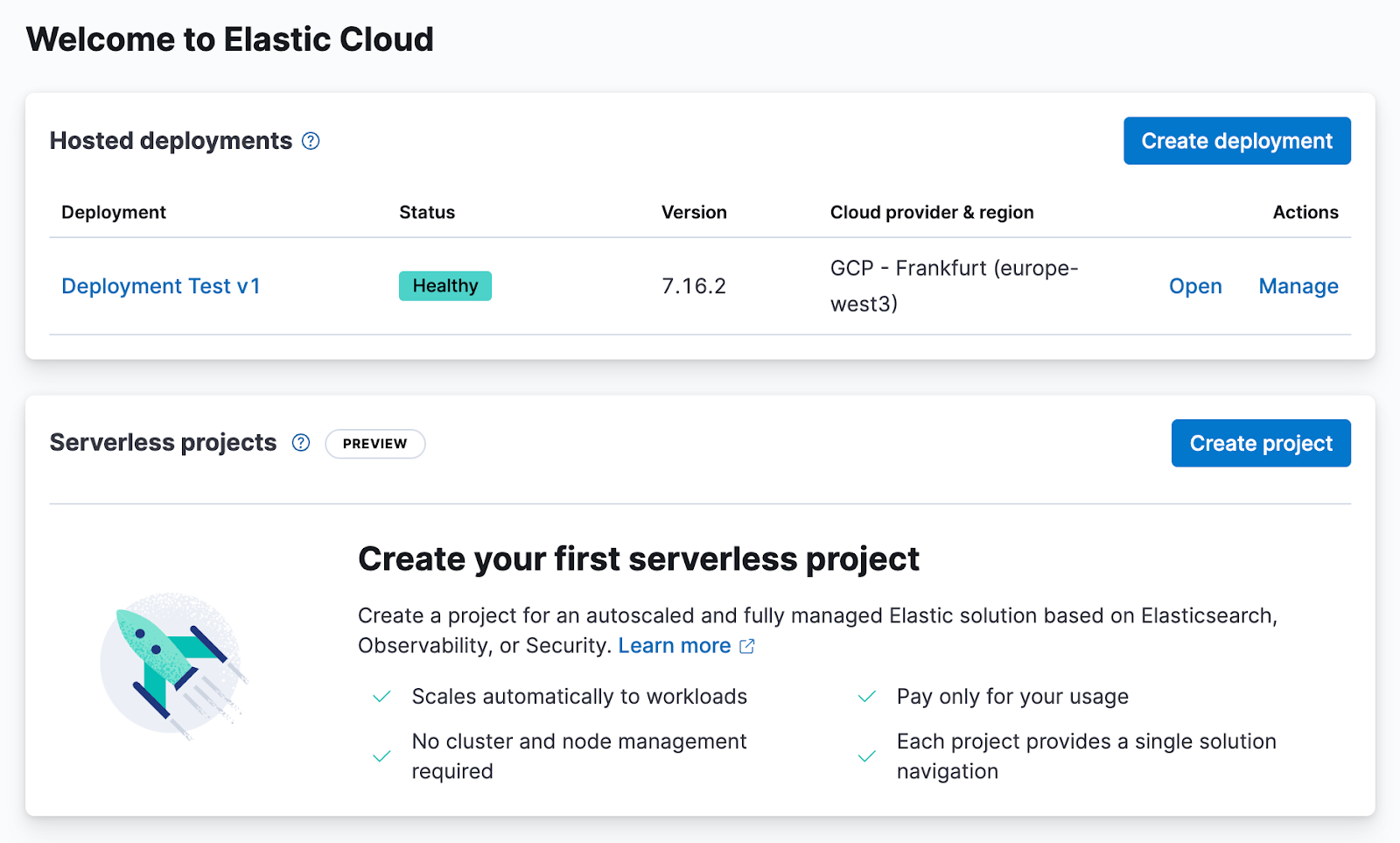
A lot of work has gone into this offering over the past 18 months for Elasticsearch and Kibana, and this includes not only the products themselves but also their orchestration. We've designed and built a new backend platform powered by Kubernetes to orchestrate Elastic Cloud Serverless projects, making it easier to manage the Elastic Stack within Kubernetes running in the cloud.
Blogs, videos, and interesting links
Scalar quantization: Follow Thanos Papaoikonomou and Thomas Veasey as they evaluate scalar quantization and demonstrate how it can be used to reduce the memory footprint by 75% of vector embeddings in Elasticsearch without significant loss in retrieval performance.
Elastic connectors: Discover how the usage of incremental syncs can improve the performance of your Elastic connectors with Artem Shelkovnikov. Jedr Blaszyk demonstrates how to use the Connector API to ingest data into Elasticsearch Serverless.
SIEM: Reduce false positives with automated SIEM investigations from Elastic and Tines with Aaron Jewitt.
kNN search: Learn about exact and approximate kNN search in Elasticsearch and when to use each one with Carlos Delgado. Madhusudhan Konda explains how to choose the best k and num_candidates for kNN search and how to score documents based on the closest ones with multiple kNN fields.
Geospatial search: Philipp Kahr and Valentin Crettaz demonstrate how to create a geospatial search from a question formulated in natural language.
Multi-agent AI architecture: Achieve better RCAs with multi-agent AI Architecture and discover how specialized LLM agents collaborate to tackle complex tasks with unparalleled efficiency with Jeff Vestal and Baha Azarmi.
Keep your index up to date: Learn how to use Node.js to keep your index current using an Azure Function App with Jessica Garson.
OpenAI function calling with Elasticsearch: Ashish Tiwari explains how to route the user's query to the appropriate function using OpenAI function calling. The blog also shows how to perform searches on Elasticsearch using natural language queries.
Elastic’s RAG-based AI assistant: Bahubali Shetti analyzes application issues with LLMs and private GitHub issues, explaining how GitHub issues and other documents from internal and external GitHub repositories can be used in root cause analysis with Elastic’s RAG-based AI Assistant.
Featured content from the community
Arton Demaku explains how Elasticsearch works.
Maksim Navitsky develops a Spring Boot application with Elasticsearch integration.
Implement an Elasticsearch autocomplete email analyzer with Andrew Dieken.
- Usha Rengaraju explains how to combine semantic search with Elasticsearch to improve search efficiency for accessibility & inclusion using Intel’s Quantization and Neural-Chat-7b.
Upcoming events
Americas
San Francisco: AI Engineer World’s Fair — June 25-27
São Paulo: Febraban Tech 2024 — June 25-27
Meetup in San Francisco: Elasticsearch at Stairwell: Journey to Developing the Search Infrastructure — June 26
Meetup in New York City: Elastic & LangChain — June 26
Meetup in Denver: Unveiling ES|QL — June 26
Juiz de Fora: DevOpsDays Juiz de Fora 2024 — July 5-6
Montreal: Enhancing Search Relevance with Elasticsearch and Azure OpenAI Integration — July 9
Meetup in Recife: Elasticsearch e Elastic Cloud — July 9
Meetup in Washington, D.C.: Elasticsearch Transforms and Enrichment + Vector Search — July 11
Meetup in Austin: Elastic & Tines Joint Meetup — July 11
Europe, Middle East, and Africa
Rennes: BreizhCamp — June 26-28
Meetup in Barcelona: Security meetup at Trainline — June 27
Meetup in London: ES|QL at Worldpay — June 27
Lyon: Lyon JUG — June 27
Nürnberg: Developer Week '24 — July 1-5
Meetup in Amsterdam: Elastic summer meetup — July 3
Montpellier: Sunny Tech — July 4-5
Nice: Riviera Dev — July 8-10
Asia-Pacific
Meetup in Pune: Function calling - Connect LLMs to the Internet — June 29
Meetup in Delhi: Elastic Observability Day — July 13
Join your local Elastic meetup group for the latest news on upcoming events. If you’re interested in presenting at a meetup, send an email to meetups@elastic.co.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print