_(1).png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Hello from the Elastic DevRel team! Welcome to our latest newsletter blog edition, where you'll find information on upcoming events in your region, catch up on content, and stay up to date with product updates.
In this edition, we dive into the latest enhancements and optimizations that boost vector search performance in Elasticsearch and Apache Lucene, making it up to 8x faster and 32x more efficient. We also explore the new Elastic Cloud Vector Search optimized hardware profile that is now available for Elastic Cloud users on GCP.
What’s new?
Elasticsearch and Lucene are getting up to 8x faster and 32x more efficient with their recent improvements for vector search.
Architecture: Lucene organizes data into segments — immutable units that undergo periodic merging. This structure allows for efficient management of inverted indices that are essential for text search. With vector search, Lucene extends its capabilities to handle multi-dimensional points, employing the hierarchical navigable small world (HNSW) algorithm to index vectors. This approach facilitates scalability, enabling data sets to exceed available RAM size while maintaining performance. Additionally, Lucene's segment-based approach offers lock-free search operations, supporting incremental changes and ensuring visibility consistency across various data structures.
The integration, however, comes with its own challenges. Merging segments requires recomputing HNSW graphs, which incurs index-time overhead. Searches must cover multiple segments, leading to possible latency overhead. Moreover, optimal performance requires scaling RAM as data grows, which may raise resource management concerns.
Multi-threaded search: But Lucene's segmented architecture also enables the implementation of multi-threaded search. Elasticsearch’s performance gains come from efficiently searching multiple segments simultaneously. Latency of individual searches is significantly reduced by using the processing power of all available CPU cores. This optimization is particularly beneficial for Hierarchical Navigable Small World (HNSW) searches.
Multi-graph vector search: In multi-graph search scenarios, the challenge lies in efficiently navigating individual graphs, while ensuring comprehensive exploration to avoid local minima. To mitigate this, we devised a strategy to intelligently share state between searches, enabling informed traversal decisions based on global and local competitive thresholds.
By synchronizing information exchange and adjusting search strategies accordingly, we achieve significant improvements in search latency while preserving recall rates comparable to single-graph searches. In concurrent search and indexing scenarios, we notice up to 60% reduction in query latencies with this change alone!
Java's advancements: Lucene's vector search implementation relies on fundamental operations like dot product, square, and cosine distance, both in floating point and binary variants. Traditionally, these operations were backed by scalar implementations, leaving performance enhancements to the JIT compiler. However, recent advancements introduce a paradigm shift with the Panama Vector API that interfaces with Single Instruction Multiple Data (SIMD) instructions, enabling developers to express these operations explicitly for optimal performance — with Lucene and Elasticsearch making excellent use of them.
Scalar quantization: Memory consumption has long been a concern for efficient vector database operations. By embracing byte quantization, Lucene slashes memory usage by approximately 75%, offering a viable solution to the memory-intensive nature of vector search operations. Lucene’s implementation uses scalar quantization, a lossy compression technique that transforms raw data into a compressed form, sacrificing some information for space efficiency. It achieves remarkable space savings with minimal impact on recall, making it an ideal solution for memory-constrained environments.
To make compression even better, we aimed to reduce each dimension from seven bits to just four bits. Our main goal was to compress data further while still keeping search results accurate. By making some improvements, we managed to compress data by a factor of eight without making search results worse by adding a smart error correction system.
Multi-vector integration: Lucene's "join" functionality — integral to Elasticsearch's nested field type — enables multiple nested documents within a top-level document, allowing searches across nested documents and subsequent joins with their parent documents. Instead of having a single piece of metadata indicating, for example, a book's chapter, you now have to index that information data for every sentence.
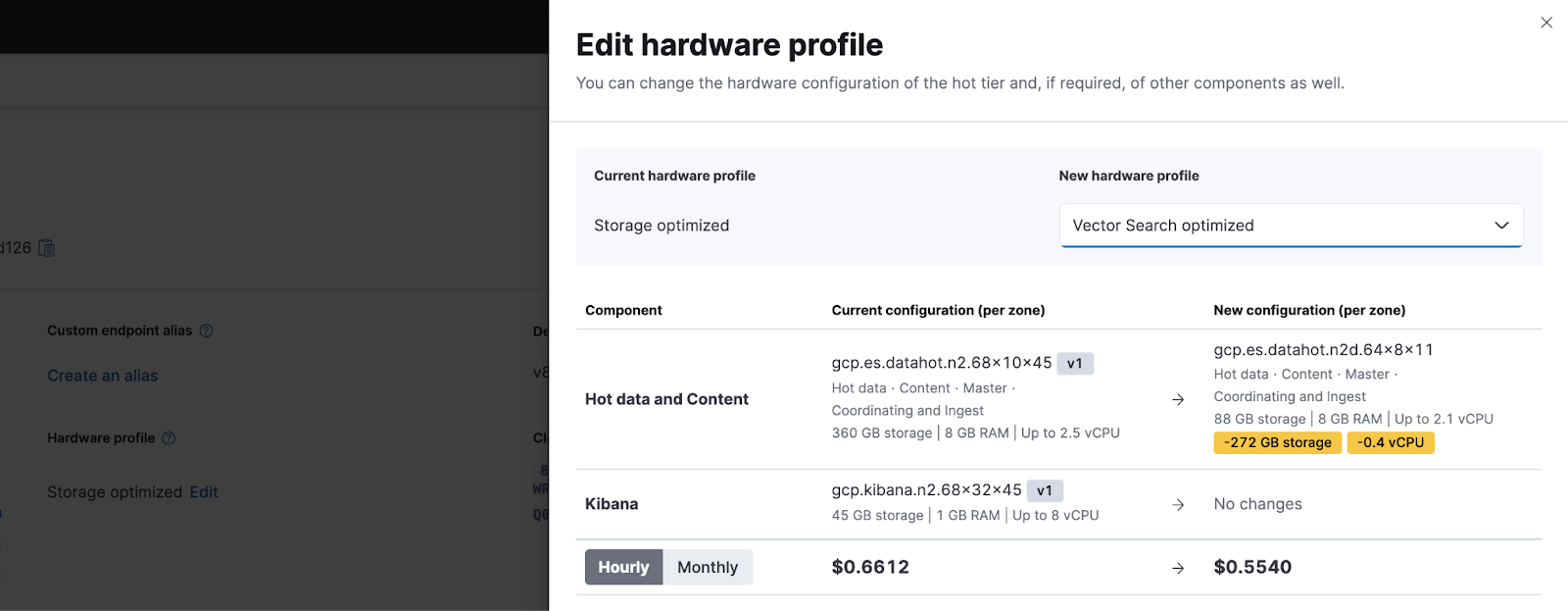
Vector database optimized instance on Google Cloud: To be most performant, HNSW requires the vectors to be cached in the node's off-heap memory. With this in mind, the Elastic Cloud Vector Search optimized hardware profile is configured with a smaller than standard Elasticsearch JVM heap and disk setting. This provides more RAM for caching vectors on a node, allowing you to provision fewer nodes for your vector search use cases.
Blogs, videos, and interesting links
Scalar quantization in Lucene: Benjamin Trent and Thomas Veasey share their in-depth two-part series about Int4: more scalar quantization in Lucene and scalar quantization optimized for vector databases and how to use byte or half-byte sized integers instead of floats (4 bytes) per vector dimension.
Elastic web crawler: If you’re looking for a concrete example of how to use the Elastic web crawler, Lionel Palacin demonstrates it with a website where we want to add search.
.NET client: Learn about the evolution of the Elasticsearch .NET client and how it will gradually phase out the old NEST library with Florian Bernd.
kNN search: Panagiotis Bailis explains the simplification of kNN search. k and num_candidates are now optional. But picking good default values for them was a tricky undertaking and the blog post shows how we got there.
Universal profiling agent: The Elastic Universal Profiling agent is now open source and in the process of being donated to OpenTelemetry. Learn more about it with Israel Ogbole and Christos Kalkanis. Luca Wintergerst and Tim Rühsen explore how Elastic’s Universal Profiling can improve performance and reduce costs by fixing issues in Logstash.
ChatGPT and Elasticsearch: Follow Sandra Gonzales to learn how to develop a custom GPT step by step. It’s your own version of ChatGPT that retrieves custom data from Elasticsearch, which can add both current and proprietary context.
Elastic Contributor Program: Explore three reasons why you should become an Elastic community ambassador and check out the winners of the 2024 cycle in Ully Sampaio’s blog.
Featured blogs from the community
- Learn how to do reverse search within Netflix’s federated graph with Ricky Gardiner, Alex Hutter, and Katie Lefevre.
- Hugo Chargois demonstrates how to reclaim 100 TB+ of storage with better tuned Elasticsearch mappings.
- Get an overview of Elasticsearch’s Index Lifecycle Management from Chunting Wu.
- Sagar Gangurde explains how to use Elasticsearch as a vector database.
Upcoming events and meetups
Americas
Virtual Meetup: Aggregations, the Elasticsearch Group By — May 15
Meetup in Silicon Valley: OTel Collector for log collection + Elasticsearch in the United States House — May 15
Meetup in Lancaster: Monthly Meetup — May 15
Meetup in Goiânia: Esquenta para o Cloud Summit Cerrado 2024 — May 15
Cloud Summit Cerrado 2024, Goiânia — May 15–16
PyCon US, Pittsburgh — May 15–23
DevOpsDays São Paulo 2024 — May 18
Meetup in Seattle: Streamlining Generative AI with Elastic & Azure's OpenAI Integration — May 20
Meetup in Dallas: do MORE with stateLESS — May 21
Microsoft Build: How will AI shape your future?, Seattle and online — May 21–23
Meetup in Austin: Putting Insights into Motion with Elastic & Tines + do MORE with stateLESS — May 22
Meetup in St. Louis: Transforming Underutilized Media Assets into Valuable Resources — May 23
DevOpsDays Montréal — May 27-28
Meetup in Belo Horizonte: 2° Meetup Elastic & Dito em BH — May 28
Meetup in Québec: GenAI à travers la sécurité et l'observabilité — May 30
Open Source North, Minnesota — June 5
Meetup in Minneapolis: Elasticsearch & GitLab's AI-Powered DevSecOps Platform — June 6
Workshop in Pennsylvania: Elastic & Federal Resources Corporation: Elastic Security Analyst Workshop — June 6
Meetup in Silicon Valley: Better Together: Elasticsearch and the Dremio Lakehouse — June 6
Europe, Middle East, and Africa
JCON Europe, Cologne — May 13–16
Meetup in Lisbon: Optimize Your Operations with PagerDuty Elastic Integration with Elastic and PagerDuty — May 14
Meetup in Zurich: Scaling Threat Detection for Migros with Efficient Network Flow Data Storage — May 15
Geecon 2024, Krakow — May 15–17
MLOps Community London: — May 16
PHPday 2024, Verona — May 16–17
Alpes JUG, Meylan — May 14
Geneva JUG — May 15
Lyon JUG — May 16
TADx: Elasticsearch Query Language: ES|QL, Tours (FR) — May 21
Codemotion Madrid — May 21–22
Voxxed Days Brussels — May 21–22
Infoshare 2024, Gdańsk — May 22–23
Meetup in Göteborg: Exploring Vector Search & AI Ops in Elastic Observability — May 23
Meetup in Amsterdam: Elastic & AWS — May 23
Meetup in Sofia: Vector Search & ES|QL @ FFW — May 28
JPrime, Sofia — May 28–29
Meetup in Helsinki: Elasticsearch Piped Query Language (ES|QL) with Elastic and Nordicmind — May 30
CoTeR numériqu, La Rochelle — June 4–5
AI and Elasticsearch: Entering a New Era with Elastic: Prague — June 5
Meetup in Brussels: GenAI with Elastic and Microsoft — June 6
DevFest Lille — June 6–7
Asia-Pacific
Meetup in Mumbai: Elastic Observability Day — May 18
Meetup in Shanghai: Elasticsearch new piped query language (ES|QL) — May 25
Join your local Elastic meetup group for the latest news on upcoming events. If you’re interested in presenting at a meetup, send an email to meetups@elastic.co.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

