Distributed alerting with the Elastic Stack


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Modern computing environments and distributed workforces have produced new challenges to traditional information security approaches. Many traditional threat detection and response strategies rely on homogeneous environments, system baselines, and consistent control implementations. These strategies have been built on traditional environment assumptions that may no longer be true in your environment with the evolution of cloud computing, remote work, and modern culture.
Elastic is distributed by design, from our technology to our workforce. Elasticians are empowered to work where they want, when they want, how they want. This includes what technologies they utilize, what configurations they need, and what software they prefer. Enabling this modern culture of productivity produces a new challenge to information security.
How can we secure an environment that allows for high risk activities such as creating new users, configuring network proxies, and installing new software without IT involvement? How can we apply detections to an environment without baselines of activities? How do we scale our detection and response practice across a modern enterprise operating in many different locations or even countries? How do we do this without a traditional security operation center (SOC)?
It’s simple. We send the alert to those in the best position to confirm or deny the activity via our distributed alerting framework.
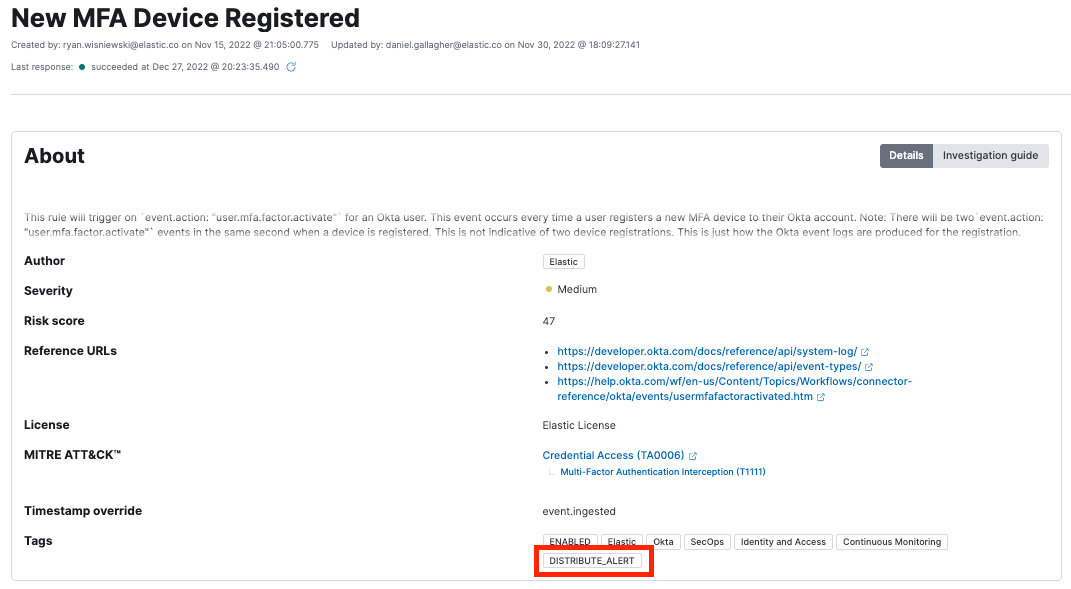
Distributed alerting allows our Threat Detection and Response team to automatically identify risky activities, send a message to our employees in natural language, and ask for a confirmation of the activity. If the Elastician does not recognize the activity, the alert can be immediately escalated to our Incident Response team for remediation. Below is an example of a distributed alert sent to our employees for a new MFA device being registered to their account:
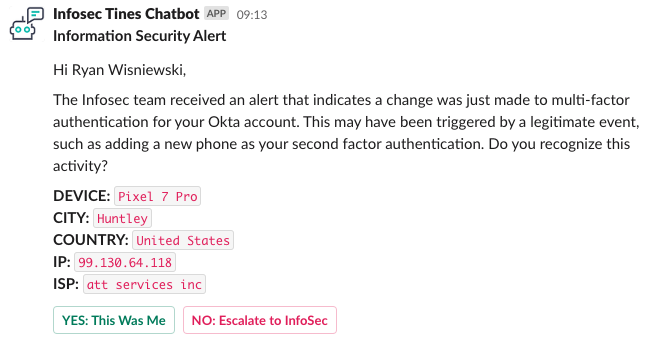
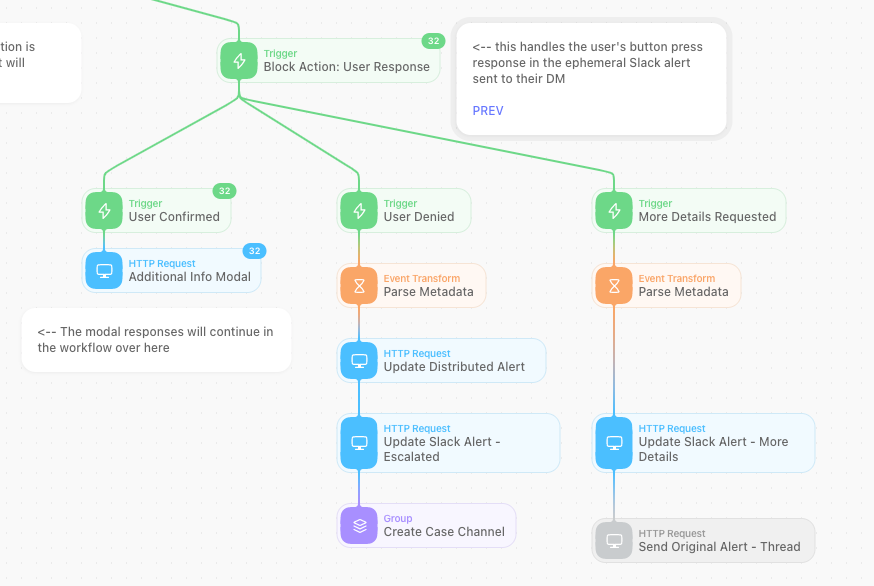
If they recognize the activity, they click the YES: This Was Me button. They are displayed a prompt to provide any additional information that would be useful in explaining the activity or tuning opportunities.
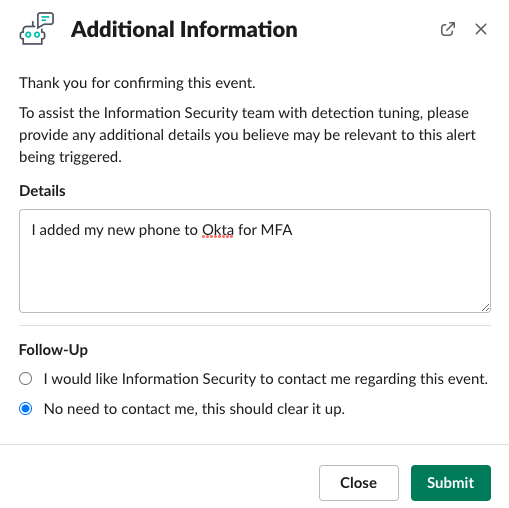
On the backend, a new security case is created, alerts are associated with the case, the details are recorded, and the case is closed as “No Impact” with a summary for the daily report.
If they do not recognize the activity, they click the NO: Escalate to InfoSec. This will generate a new security case, create a new Slack channel, invite the Incident Response team and the reporter to the channel, and provide any additional information to the team.
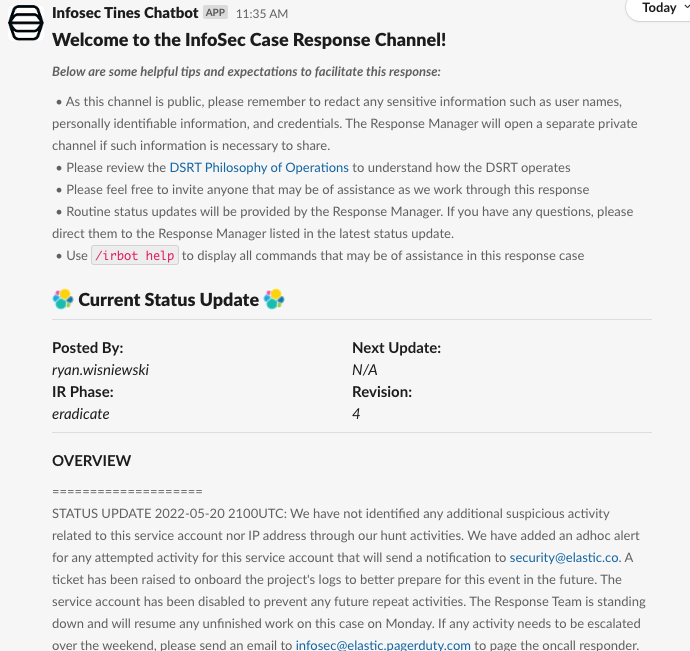
By sending these activities directly to those who can best confirm this activity, we are able to both maintain our true positive/false positive ratios of our detections and reduce our time to remediate for all of these “difficult” detections for activities that pose a high risk if they are threat actors, but occur regularly in our environment.
What makes a good distributed alert candidate?
Good candidates for distributed alerts are activities that present a high risk to your security posture but do not have any context or indication of malicious activity. For example, a single alert triggering for “New MFA Device Registered” for a user does not provide any context on the intent of the activity. Users routinely add new MFA devices to their accounts. However, if this was a threat actor’s device, the account would be considered compromised as all subsequent authentications would be successfully authenticated with a valid multi-factor device. This scenario presents a difficult situation for Threat Detection and Response teams. How can we validate these activities with no context without investigating every detail from these events? We distribute these alerts.
For some additional background, here is our threat detection strategy. We have a few different ideas that provide for a complete coverage of system activities.
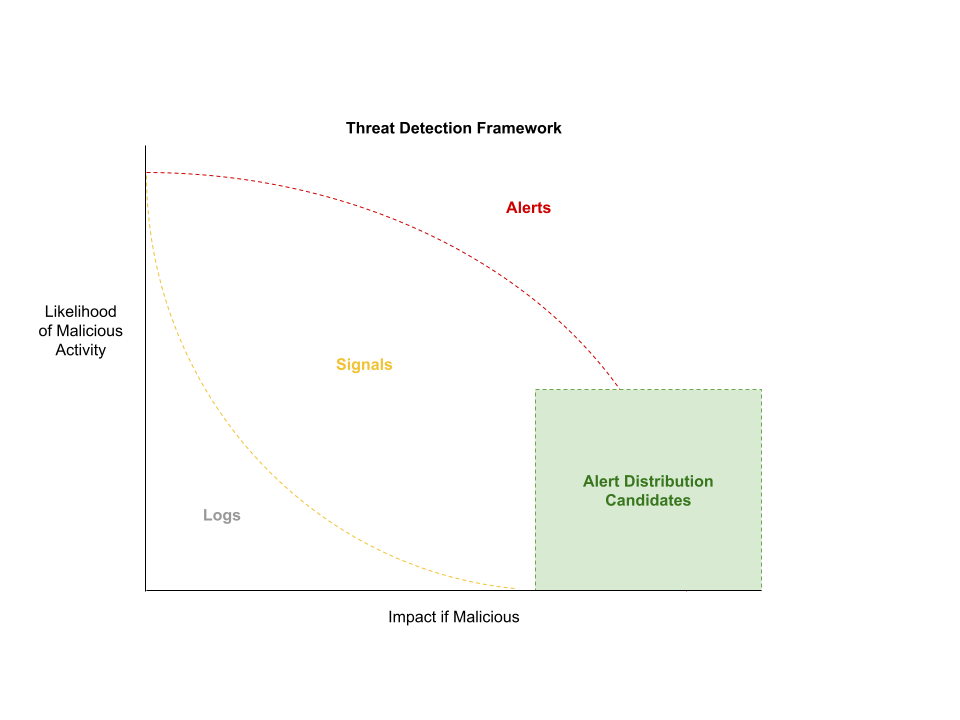
We break down our events into three different categories:
- Logs: All events that occur on a system. Logs are often included in investigations to understand what occurred. A log event is not indicative of any suspicious activity. It is merely a record of what happened.
- Signals: We utilize the Elastic Security application to generate signals. Detection rules are written to identify activity that may indicate suspicious activity; however, the activity may also be benign. The context of these events is difficult to ascertain from a single event, so it is not an immediate alert. Threat hunts are designed around signals to identify related activity that could be utilized to identify malicious or benign content to tune the detection rule from a signal to an alert.
- Alerts: We promote signals to alerts when we have high confidence in the signal indicating malicious activity (i.e., Likelihood of Malicious Activity) or when an activity carries such a high impact, all events must be validated to reduce the likelihood of the impact (i.e., Impact if Malicious).
Alerts with a high impact but low probability of malicious intent create a great opportunity for alert distribution. This allows us to validate administrative activities, new activity, anomalous user activity, and all other activities at enterprise scale without requiring a traditional SOC.
How do we distribute alerts?
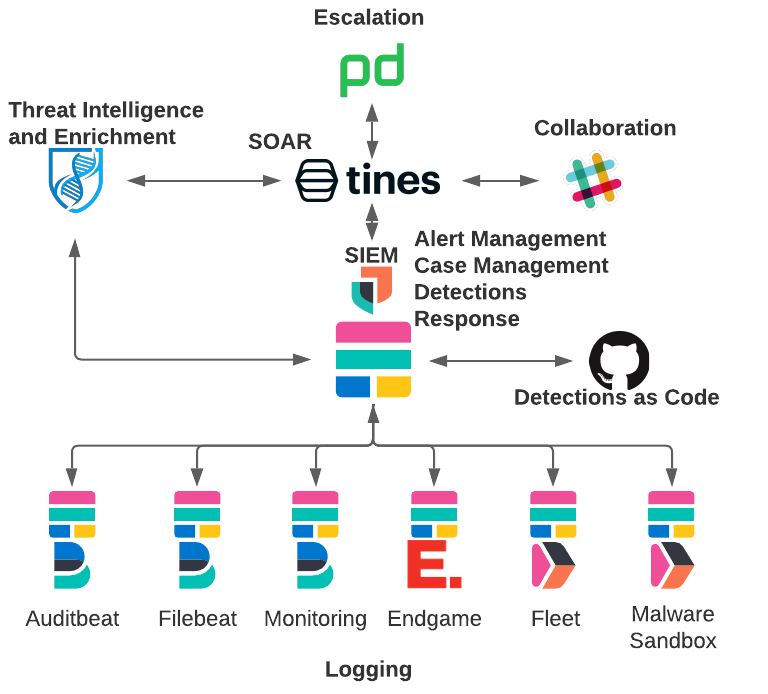
As Customer Zero of Elastic products, we have our Elastic Stack at the center of our SIEM and SOAR architecture. For details on how all of our data is ingested into the Elastic Stack, see our blog post Elastic on Elastic: Data Collected to the InfoSec SIEM.
We have made a few updates to our architecture to allow for this new capability of distributed alerting.
We have introduced an automation platform to centralize our workflows into the Tines no-code automation platform. Utilizing workflows built in Tines, the alerts from the Elastic Stack are triaged and distributed based on predefined logic in the Tines stories.
When a detection rule is tagged for distribution DISTRIBUTE_ALERT, Tines will redirect the alert from the alert triage queue and into the distributed alerting workflow.
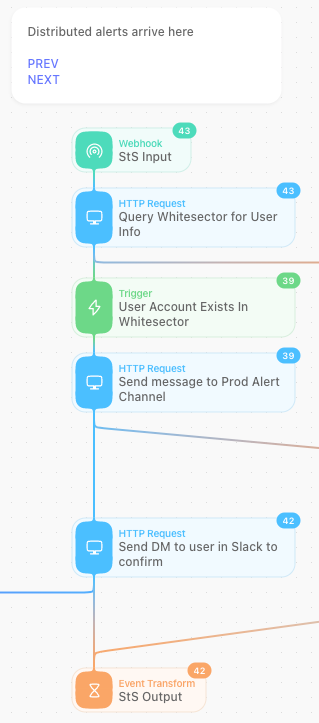
All alerts containing the DISTRIBUTE_ALERT tag will run through our distributed alerting workflow. The Tines workflow identifies the user in the asset database and then sends the alert to the user via Slack for confirmation.
When the user clicks the button in the alert, it will enter the following workflow to either request additional information or escalate the alert to Incident Response.
These alerts automatically open a new case in Elastic Cases with all of the relevant information. We utilize additional automations to provide analysts with enrichments such as GreyNoise and related Elastic Security alerts. The last 30 days of activity for the IP address is also provided in an Elastic Timeline for the analyst to review.
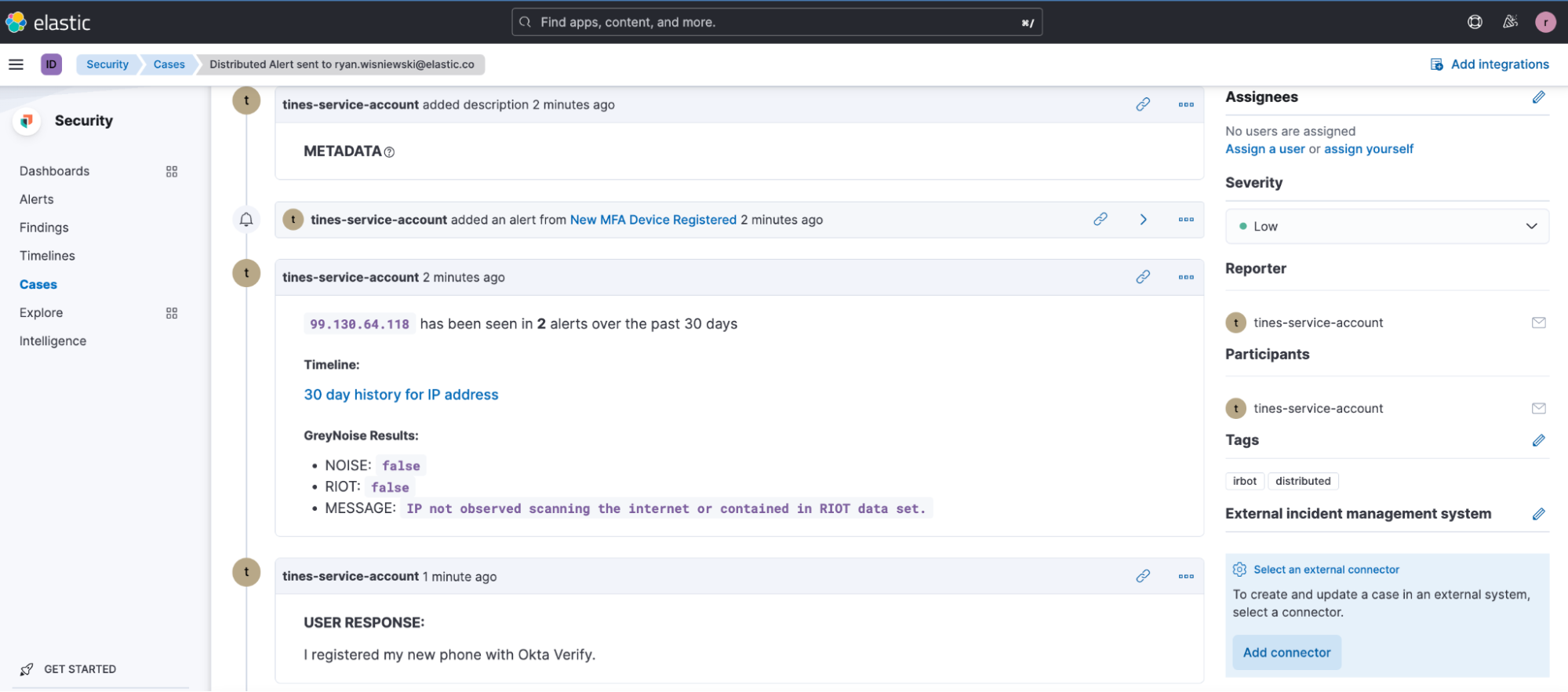
When the user provides their feedback and confirms the activity, their feedback is recorded in the case and the case is closed.
How do I get started?
You can get started with a free 14-day trial of Elastic Cloud and utilize the example Tines story Triage Elastic Security alerts and block malicious IPs to begin ingesting Elastic Security alerts into your automation workflows. You will then need to integrate with your messaging client of choice. Tines offers example stories in its library for Microsoft Teams and Slack.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print