Get the most from Elastic Agent with Amazon S3 and SQS


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Every day, Elastic users move petabytes of data into Elasticsearch. Ingesting this data via cloud message queues and object storage is continuing to prove extremely popular. And Elastic Agent plays a key part in these architectures, with Elastic users deploying Elastic Agent to ingest data at petabyte scale.
In this post, we cover how the Performance Presets introduced in 8.12 enable new Elastic users to worry less about how the data gets into Elasticsearch and focus on the valuable insights available through our Observability and Security solutions. If you’re an existing user, we’ll show you how you can decrease the size and cost of your ingest architecture by reducing the complexity of your configurations and relying more on product defaults.
A new world of presets
Before the availability of Performance Presets, tuning Elastic Agent to a use case was often necessary to achieve their cost and performance goals, with many customers working to optimize their architecture to ensure maximum performance or lowest cost.
Performance Presets have now made optimization of cost and performance accessible out of the box, significantly enhancing ingest performance and stability while reducing costs.
These new presets come in four flavors that make it easy to get the most out of Elastic Agent:
1. Balanced: Default preset offering enhanced throughput and reduced memory usage
2. Optimized for Throughput: Achieves 4x higher data ingestion rates; great for cloud data sources
3. Optimized for Scale: Ideal for large Agent deployments, reducing open connections significantly
4. Optimized for Latency: Most suitable for low-latency, real-time applications
While this post focuses on Amazon Simple Queue Service (SQS) and Simple Storage Service (S3), these Performance Presets are applicable across various use cases.
Pub/sub object store performance information
With Elastic Agent and S3/SQS, even the smallest, burst-able* compute instances deliver excellent performance. This is great news as these instances are by far the cheapest compute instances available from cloud providers and, when deployed as recommended, they enable exceptional throughput while minimizing the impact of losing individual nodes.
While additional fine-tuning can be performed to utilize more CPU, memory, or network, we recommend leaving headroom such that regular usage of the Agent doesn’t consume CPU or I/O credits during baseline usage. For this reason, we recommend scaling throughput for message-queue-based data sources by deploying more instances rather than attempting to fine-tune for larger, more expensive instances.
The good news with all of this is that throughput increases linearly with the number of instances: 8x more instances mean 8x more throughput.
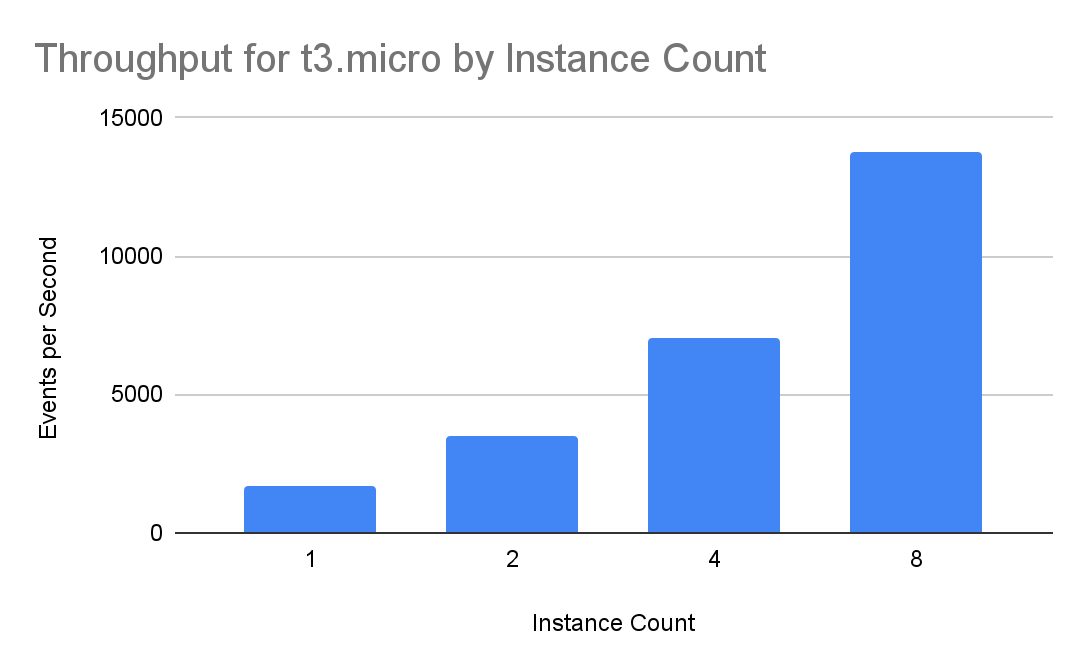
Switching from t3.xlarge instances to t3.micro instances can result in up to 94% compute cost savings or a 16x improvement in throughput for the same compute cost. While tuning was available to get the most out of instances of any size, there were limits to how much performance could be unlocked with a single instance. Rather than spending time tuning parameters to get the most of any particular instance size, tailoring instance size to workflow is easier, more efficient, and more cost-effective.
New S3/SQS recommendations
With the exceptional performance available out of the box with Elastic Agent 8.12, we no longer recommend manually tuning our SQS integrations for the majority of use-cases. Prior tuning guidance covering settings like max_number_of_messages, workers, or others are no longer recommended under most use cases.
Most tuning done previously can be safely replaced with the new, default “Balanced” mode included in 8.12.1. The “Balanced” mode delivers 3x the performance of what was previously available, and it does so out of the box with no tuning required. This remains true across all supported instance sizes:
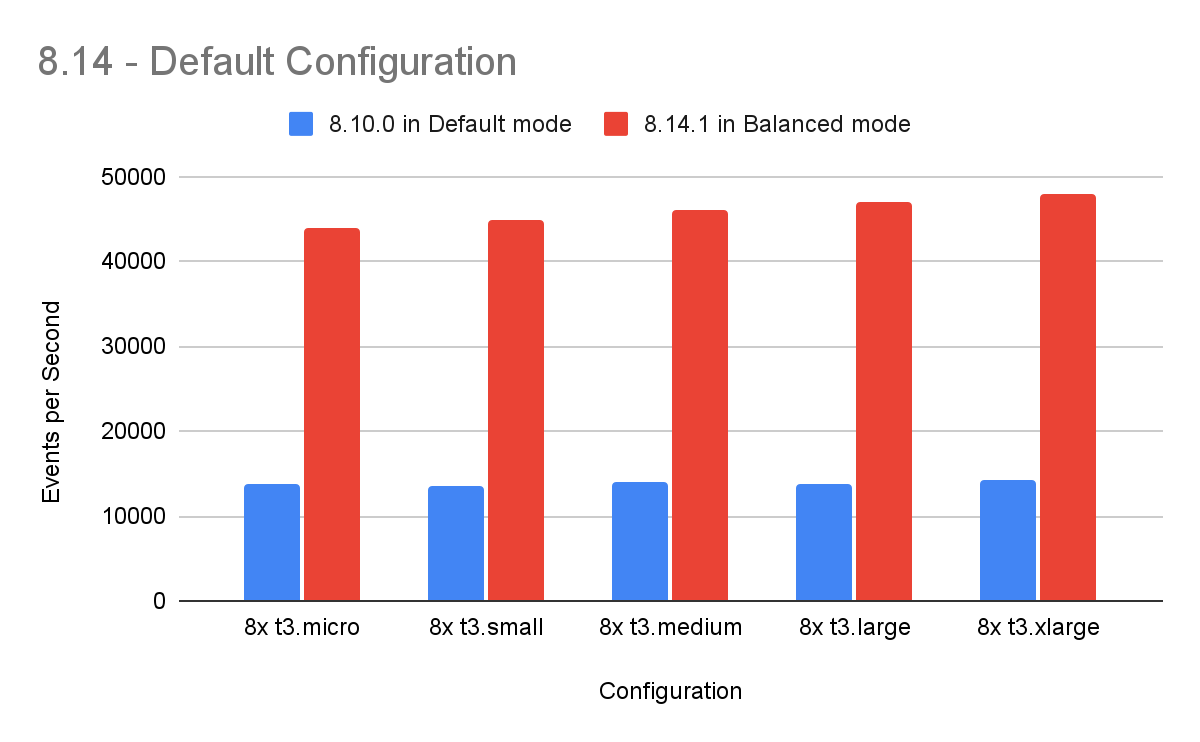
When additional throughput is desired, we recommend simply switching to the “Throughput” Agent performance preset to more fully utilize available resources and unlock an additional 4x performance boost.
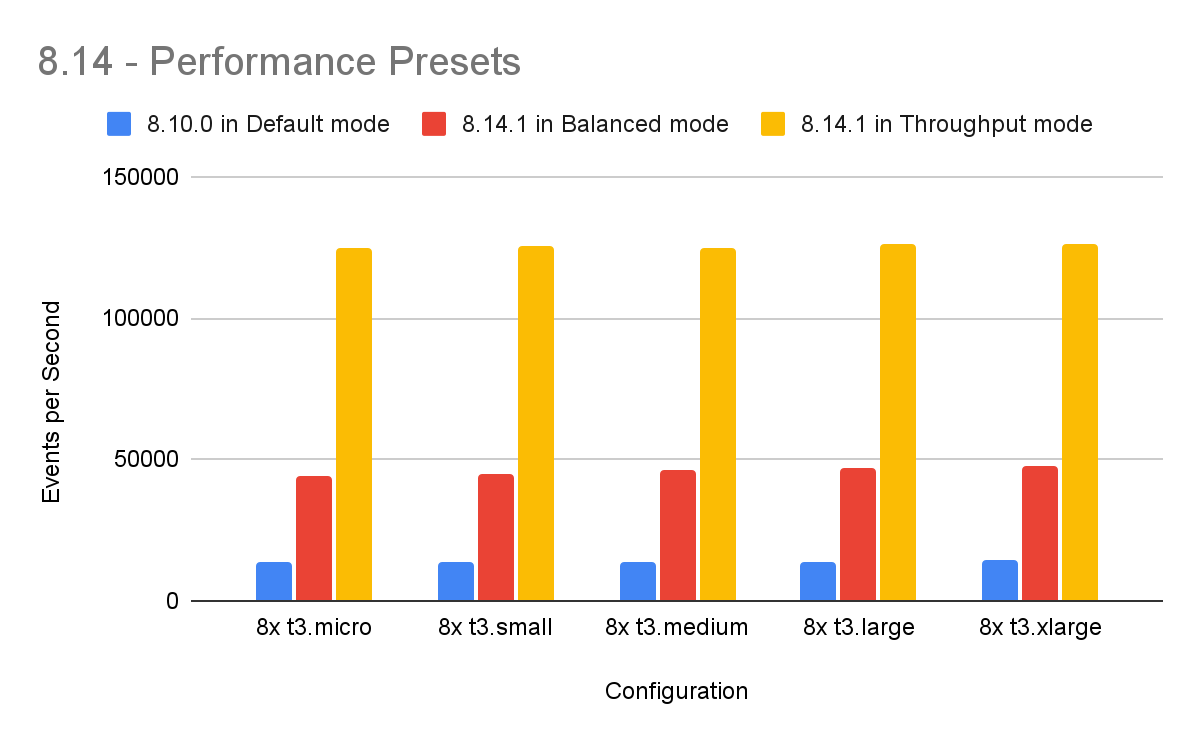
The Throughput preset is optimized for high throughput scenarios — in this mode, Agent performs more work concurrently, multiplexes requests across multiple connections, and better utilizes available system resources. In common use cases, a single 8.12 Agent using the Throughput performance preset can deliver 10x the events per second achievable under previous versions of Agent without tuning SQS settings!
When optimizing for high throughput and reliability, we recommend deploying a dedicated pool of Agents to handle your message-queue-based data ingest pipelines and, where possible, avoid mixing message-queue/object-store ingest with other kinds of ingest in an Agent policy.
Achieving optimized performance and cost
Starting with Elastic Agent 8.12 and S3/SQS cloud workloads, we recommend scaling ingest horizontally, incorporating additional nodes to scale ingest rather than making those nodes larger. With Agents deployed on a small number of low-cost, burstable instances, you can achieve exceptional baseline performance at a fraction of the cost while benefiting from enhanced reliability and buffer for handling peak ingest.
A customer ingesting 300TB per month from AWS S3 (150k events per second @ 1kb/event) could see a 99.5% reduction in infrastructure costs by right-sizing their instances and enabling the throughput preset. If the customer had chosen to deploy t3.xlarge instances in their initial architecture, this move would reduce the deployment from 100 on-demand t3.xlarge instances to just 10 on-demand t3.micro instances, reducing compute costs by $350k/yr.
We also recommend reviewing the size and scale of your cloud ingest nodes, incorporating performance presets where appropriate with an eye toward reducing the cost and complexity of your deployment.
Learn more about the possibilities with Performance Presets.
*A note on burstable instance types
A burstable instance type has a low baseline performance — for example, a t3.micro instance only has access to 20% of a CPU core as its baseline compute. When you use less than the 20%, you earn CPU “credits,” which will later allow you to burst above 20% of CPU for a short period of time (trading in your earned credits).
The benchmarks in this article do not rely on the ability to burst the CPU; instead, they represent the baseline ingest capability for these nodes.
A note on benchmarks
This article covers what we consider to be typical use-cases. We do our best to include a wide range of situations in our recommendations, but there will always be environmental restrictions, atypical flows, or other considerations when choosing the best ingest architecture.
For the data in this article, we utilized S3 objects of mixed sizes, with JSON logs, with objects containing between 1 and 100K events.
A note on recommendations
These recommendations are based on using the AWS S3/SQS integration to ingest logs, with instances deployed in the same cloud provider as the Elasticsearch Cluster and the instances running the Elastic Agent software are single-purpose instances. These recommendations assume a wide range of S3 object sizes.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print