Elastic Agent: Flexibility to send and process any data, anywhere


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Agent is a powerful and versatile tool for collecting logs and metrics from various data sources, including custom user applications. Now, Elastic Agent offers unmatched flexibility to deliver data precisely where it’s needed, enabling security and observability use cases from a single agent. This blog covers the capabilities available in the latest version of Elastic Agent and how they can be tailored to fit your specific use cases.
Many destinations
Starting from Elastic Agent 8.16, with “output per integration,” users can send data from any supported data source to any supported destination. Whether it's directly to regional or business line-specific Elasticsearch clusters or through intermediaries like Logstash and Kafka, the process seamlessly scales to the largest enterprises. Deploying a single agent to collect observability and security data has never been easier.
Optional processing with Logstash
With the fine-grained control of outputs per integration, including Logstash in your ingest architecture is no longer an all-or-nothing decision. You can now include Logstash as needed for specific data sources to implement redaction, enrichment, and other capabilities unique to Logstash.
For example, if you’re using the new Logstash integration filter with your Elastic integrations, you can now send only the data that you want Logstash to process while sending the rest of your data sources straight to Elasticsearch. Reducing the workload on Logstash enables a smaller ingest footprint, less time managing nodes, and higher reliability.
Dynamic forwarding with Kafka
Kafka — a distributed, highly resilient, and scalable streaming platform — is a very popular tool for processing real-time streaming data. Kafka’s producer and consumer model allows operators to set up different pipelines for logs and metrics or security and observability or sensitive and confidential information. Elastic Agents fit right into this model with the ability to write to a specific Kafka topic, and with the release of 8.16, Elastic Agents can dynamically choose Kafka topics.
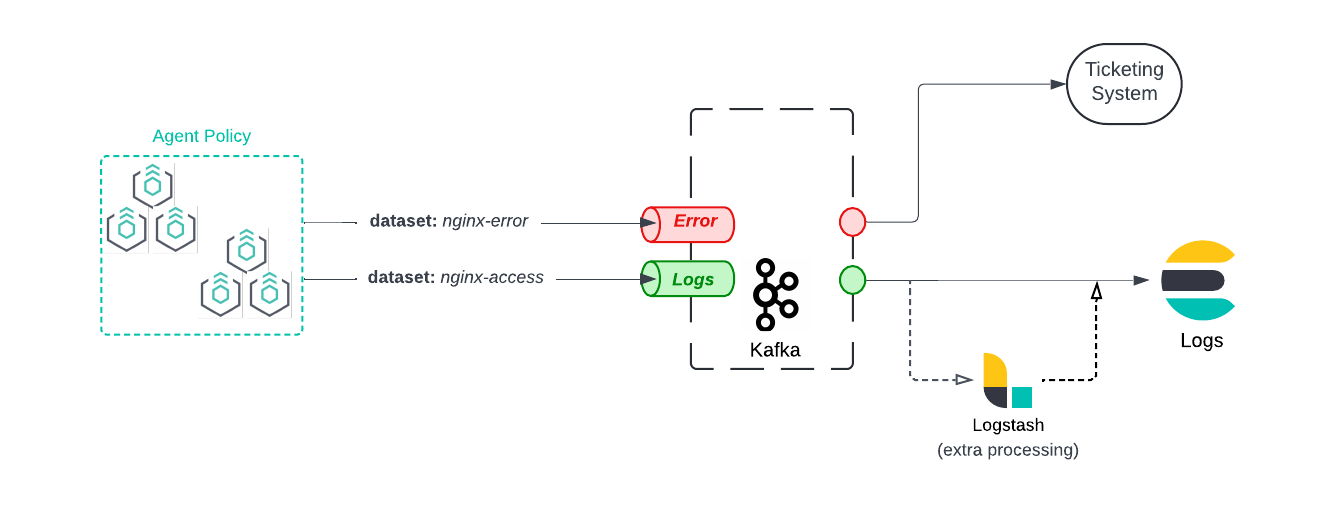
Enterprise policy management
Enterprise users rely on Elastic Agent as a centrally defined data ingestion platform. With Fleet policy management, users can manage the agent’s settings across thousands of agents at once through agent policies. Whether you organize hosts based on attributes, such as geography, data governance laws, platform type, or even departmental lines, agent policies enable simple and scalable management.
Starting in 8.16, output per integration is now available in agent policies, enabling administrators to operate a global Elastic Agent control plane while delivering critical observability and security data exactly where it belongs.
Example: Reducing cloud egress fees
Consider a multicloud enterprise with applications deployed across redundant regions and cloud providers. Managing ingest configuration per region adds administrative overhead, but managing ingest globally means costly cloud egress fees as data traverses zones and providers.
With output per integration, you can maintain global or cloud-specific Elastic Agent control planes while keeping data local to the zone or region, saving hundreds of thousands of dollars in cloud networking costs.
Example: Data sovereignty and GDPR
Consider an enterprise that needs to ensure data collected in a region stays within that region (data sovereignty). Fleet simplifies the process by allowing operators to quickly assign an output to a group of Elastic Agents through agent policies.
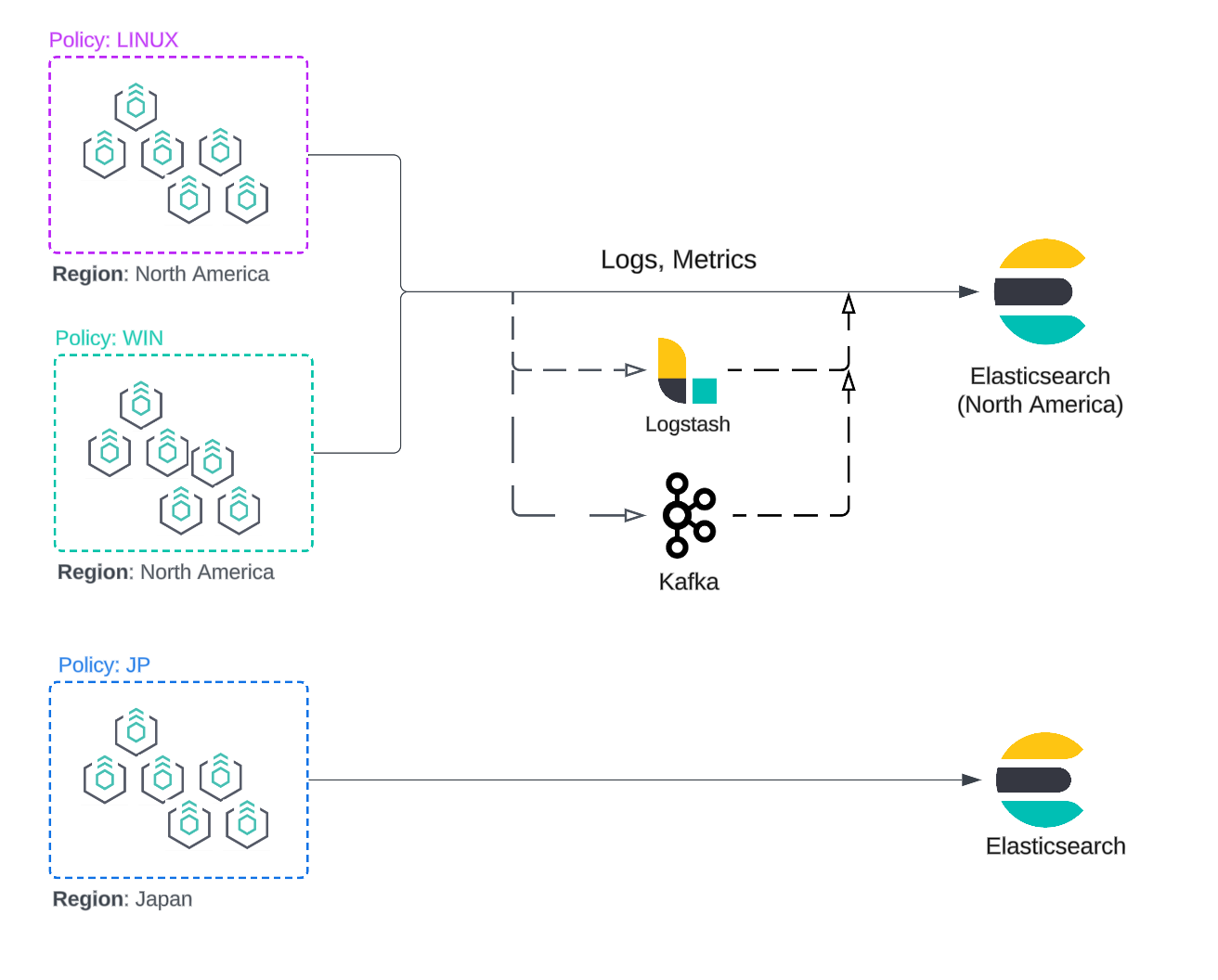
Elastic Agents also collect host logs and metrics from the platforms they are deployed on, providing valuable insights into host health. Most operators prefer to store monitoring data separately from user data, which enhances resilience and facilitates troubleshooting from a single cluster. Fleet makes this possible by enabling operators to assign a specific monitoring cluster for this data in their agent policy.
Inserting context into data
In many deployments, users need to add local context to the data ingested into their platform. This embedded context helps operators uniquely identify data for further processing, routing, and even creating context-specific dashboards, such as those for a specific tenant.
With the release of version 8.15, Elastic Agent users can now add custom [field:value] pairs at the policy level. These custom fields are embedded into all data collected by agents under that policy. As logs and events move through the pipeline, the added fields can be used to enhance or route data effectively. You can find more information about this feature in our documentation.
Additional flexibility
In summary, Elastic Agent 8.16 offers unparalleled flexibility in data collection and output management, allowing users to send data precisely where it's needed. With features like output per integration, optional Logstash processing, dynamic Kafka forwarding, and enhanced enterprise policy management, Elastic Agent streamlines complex data workflows while optimizing resource use. Whether it's reducing cloud egress fees or ensuring compliance with data sovereignty regulations, Elastic Agent empowers developers and operators to build scalable, resilient, and efficient data pipelines, making it an invaluable tool for modern enterprises.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print