ElasticGPT: Empowering our workforce with generative AI


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Like all organizations, Elastic deals with an ever-increasing volume of information and data, making it harder for our teams to keep information up to date and for employees to find answers from relevant resources.
As the Search AI Company, our approach to customer-first starts with customer zero — us. When our employees needed a better way to find the information necessary to do their jobs, we knew we could use our own technology to bring that vision to life.
Fast-forward to today, and we have launched our internal generative AI assistant, ElasticGPT, that helps employees quickly find relevant information and boost workforce productivity. It runs on Elastic's Search AI Platform and uses our vector database, Elastic Cloud deployment, Elasticsearch, Elastic Observability, and enterprise connectors. It also uses our proprietary data through retrieval augmented generation (RAG) to add context and relevance to answers.
The start of our AI journey
Elastic’s IT team plays a foundational role in accelerating technology initiatives. And over the past 18 months, the focus has been geared toward enabling generative AI technology across the organization to improve employee efficiency. This includes several homegrown generative AI tools and capabilities as well as new and emerging innovations added across our enterprise offering.
Throughout this journey, multiple business functions came together to identify the opportunity to use generative AI for employee experience, but several questions arose as we evolved in this space. These included:
How can Elasticsearch combine with generative AI to make it easier for employees to find information across our enterprise data sources and systems?
How do we bridge private company information with the power of large language models (LLMs) to generate relevant results while maintaining security and confidentiality?
Can we build a scalable solution that serves as a platform for multiple use cases while offering us the flexibility to use multiple LLMs? And how can we promote domain-specific innovation by providing this as a managed service across our organization?
How can we enable capabilities to address time-consuming and redundant requests by introducing self-service workflows that deliver capacity gains across teams?
How can we avoid technical debt by optimizing spend, managing risk, and mitigating tool sprawl?
Our core objective was simple: Build an internal, private, and secure generative AI tool using the Search AI Platform that can benefit all Elasticians for information retrieval and knowledge discovery.
Considering we are Elastic, we knew how Elasticsearch’s product capabilities would complement the AI capabilities we wanted to implement. That said, the immediate challenge was honing in on the most impactful use cases, defining our data strategy, and remaining laser-focused on our core vision.
Building our data strategy
With our goal to build a solution that would benefit all Elastic employees, we knew we needed to start by examining what data sources would make it into our minimum viable product (MVP). We narrowed it down to two criteria: 1) the data sources should have detailed information that would benefit all employees, and 2) the data needs to be up to date so that relevant, real-time information is retrieved in the outputs. We landed on two data sources for our MVP:
Confluence data: Our internal Confluence site, Elastic Wiki, is a comprehensive internal resource for all things related to Elastic, including detailed information on our products, teams, technology, processes, policies, and company culture.
ServiceNow data: We use ServiceNow knowledge articles to help address questions across various topics like policies, usage instructions, troubleshooting tips, and requesting support from teams like IT and HR.
Identifying the two data sources was simple, but governance was not as easy. Why? Like most organizations with petabytes of data, we had lots of information in various locations, and we weren’t confident about data accuracy. This multidimensional problem was critical to solve to make sure that the quality of response was not negatively impacted by “dirty” or “noisy” data.
To tackle our data challenges, we developed a step-by-step framework:
Step 1: Capture and organize data. This entailed taking inventory of our data sources, organizing our information, and defining how and where this data would be used.
- Step 2: Ensure data accuracy and relevancy. We had to define what information was reliable, so we built data criteria that classified information as “stale” (e.g., information that has not been updated for a defined period, artifacts without owners) and put forward a plan to archive this stale information or update it. This was critical to making sure that our RAG-based approach and architecture would be successful. RAG can manage conflicting information by actively retrieving the most up-to-date and relevant information across data sources to answer a query. Focusing on our data quality allowed us to ensure that answers to queries were reliable and trustworthy.
- Step 3: Set ourselves up for the future. While we planned to start with two data sources, we knew this would grow over time. Getting our data governance framework in place early would help us grow faster as we scale.
Tip: Investing in building the right data strategy and governance is crucial to ensure the quality and relevance of the data, leading to more accurate and reliable outputs. A well-defined data strategy can also aid in managing data privacy and compliance, which is essential for maintaining user trust and adhering to regulatory requirements. This is crucial as you scale your tool or generative AI program, as it provides a framework for the features and capabilities you will or will not incorporate.
Once we aligned across our core team and stakeholders, we started to build our proof of concept that would allow us to experiment, iterate, and move quickly in line with our source code tenet, “Progress, SIMPLE Perfection.”
Meet ElasticGPT
ElasticGPT — our generative AI employee assistant built on a RAG framework — is designed to help Elasticians retrieve relevant information from natural language queries and offers efficient ways to summarize information for day-to-day tasks. With the two main proprietary data sources and company-wide information from our internal tools — Confluence and ServiceNow — users can easily find answers instead of searching across multiple sources for information.
In the past, someone like John would spend their time (and often others’) trying to find information quickly.
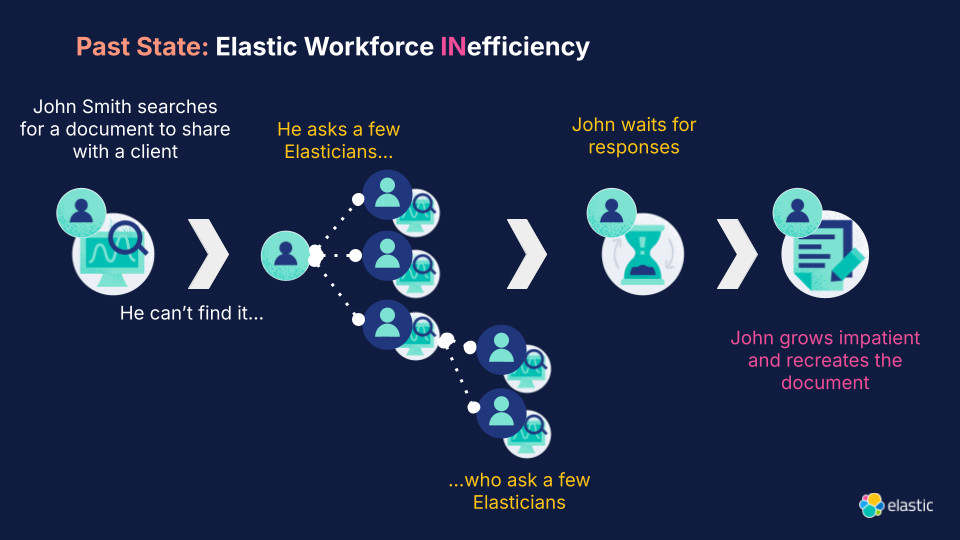
But now, John uses ElasticGPT to self-serve and find information.
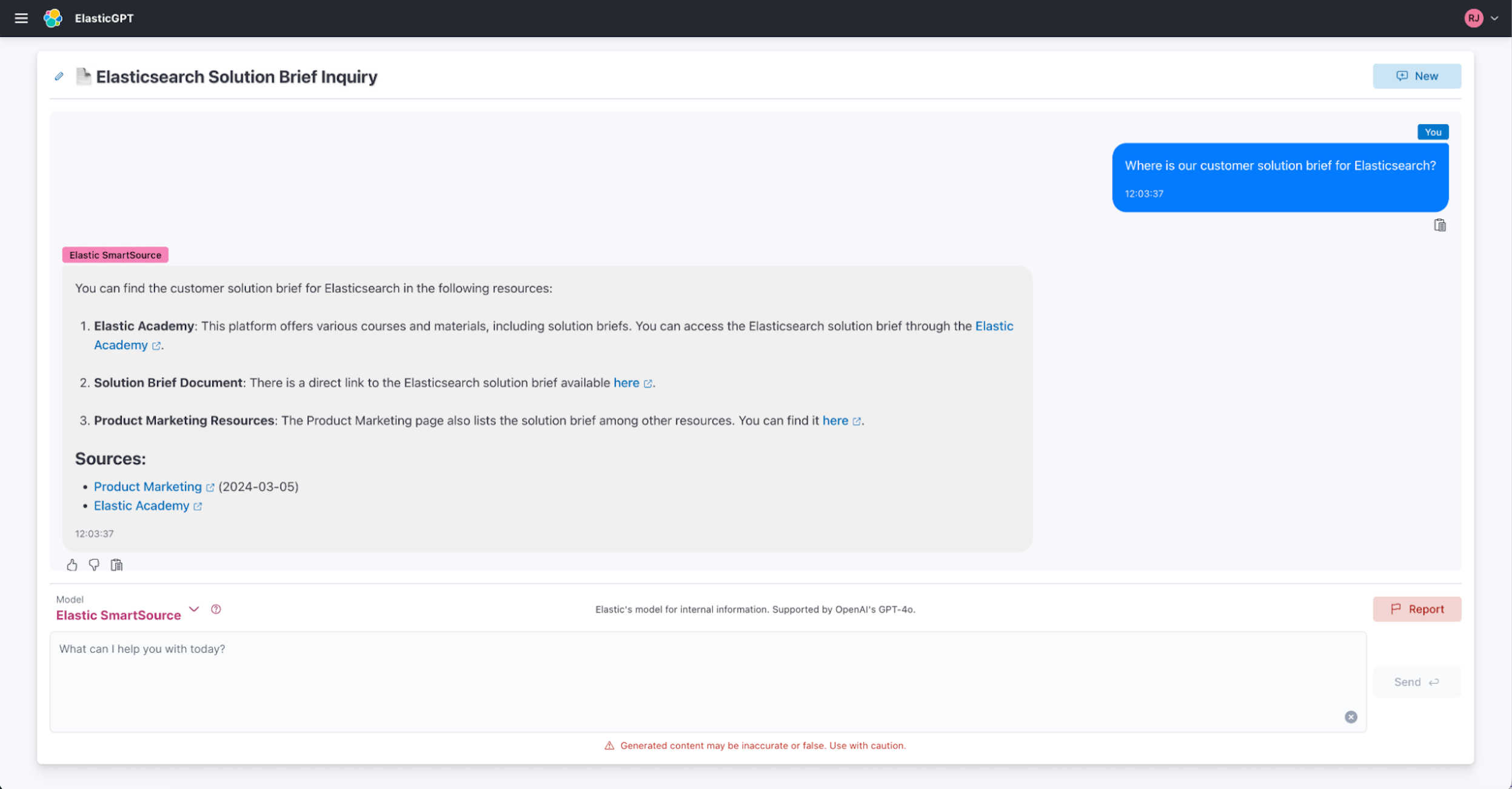
With ElasticGPT, someone like John can now quickly access information and answers without spending too much time looking for information or reaching out to multiple Elasticians, recouping his and others' time to focus on more strategic work.
The technology behind ElasticGPT
ElasticGPT is powered by multiple products and capabilities built on the Search AI Platform. This includes Elasticsearch, a vector database, semantic search, enterprise connectors, Elastic Observability, application performance monitoring (APM), and Kibana. Each of these capabilities plays a special role in developing and monitoring ElasticGPT and allows us to use a RAG technique to build a reliable and accurate solution that securely uses confidential and proprietary data. These capabilities on the Search AI Platform are now known as the Elastic AI Ecosystem.
Each of our Search AI Platform’s capabilities on our enterprise offering plays a crucial role in building out this solution:
Elastic Cloud: Our IT organization uses Google Cloud Platform (GCP) and Microsoft Azure Services for existing infrastructure. We used Elastic Cloud on GCP to build ElasticGPT.
Enterprise connectors: We used our managed connectors to ingest our data sources (Confluence and BigQuery for ServiceNow) into Elastic.
Elasticsearch: Using Elasticsearch as a vector database, we could easily break down data via a “chunking” process to help generative AI handle large volumes of data and deliver effective responses. With semantic search and vector search, we could efficiently retrieve the most relevant answers for conversation context. And with Elasticsearch’s storage capabilities, we could store all conversations and associated metadata like time stamps and user feedback in real time.
Elastic Observability: Using our Elastic Observability stack, we implemented APM to track the performance and health of ElasticGPT. This includes capturing response times, error rates, and resource utilization to help us identify and resolve bottlenecks impacting the user experience.
Information security: To keep our data secure and compliant with our security policies, we implemented robust security measures, including an SSO authentication for all Elasticians.
Kibana: With access to APM’s real user monitoring (RUM) data, we can collect metrics — such as user engagement, total conversations, failures, reported chats, model usage, and other key details — to track usage, performance, and other KPIs for ElasticGPT.
When building ElasticGPT, we used our Microsoft Azure OpenAI subscription to integrate LLMs, such as GPT-4o and GPT-4o-mini, into our solution. Elasticsearch retrieves the query context, which is then passed to these LLMs, enabling them to generate highly relevant and readable text answers. Elasticsearch also made it easy to store additional context with each interaction, including the specific LLM model used, conversation threads, source references, and user feedback.
By deploying on Kubernetes, we were able to ensure scalability and reliability by taking advantage of automated scaling based on demand, zero-downtime deployments, and comprehensive monitoring through Elastic Observability.
Transforming the way we work
In this first phase of ElasticGPT, Elasticians globally are using the generative AI experience to find relevant information. Since the first 90 days of launch, we successfully answered nearly 10K queries with ElasticGPT and saw a 99% satisfaction rate based on chat feedback. The business impact of ElasticGPT is often dependent on the particular case. However, across the organization, Elasticians are empowered with this self-service experience to boost efficiency. Not only does this help field redundant questions or requests across the organization, but it can also lead to reduced support tickets for shared service teams, such as HR and IT.
There are many use cases where employees use this tool as part of their daily workflows to summarize information, analyze data sets, generate drafts, and simply spark their creativity. Here are some specific use cases we’re seeing from early usage across the organization:
1. Product enablement: New hires use ElasticGPT to learn about our products and feature capabilities while existing employees catch up with Elastic’s innovation velocity, especially new releases and launches.
Working within the Marketing team, I’ve started using ElasticGPT to validate the technical capabilities of specific product features when writing content.
Product Marketing
2. HR, IT, Legal, and company information: Users can pose questions, such as, “How do I request access to specific tools?”; “Where can I find my benefits information?”; “What is our travel and expense policy?”; or, “When is our December holiday party?”
I had someone on my team who got married and needed to change her last name. I used ElasticGPT to find out how to update her Elastic benefits with her name change.
Legal operations
3. Sales operations: Users across our sales organization are using ElasticGPT to find and better understand our sales motions, processes, and key contacts. Users can find playbooks and make informed decisions on when to engage ancillary teams and what resources are available. Support sales teams, such as Deal Desk or Order Operations, also use ElasticGPT for following through internal processes.
I constantly see new sales motions in play for particular target segments. It’s so easy to use ElasticGPT to catch up on the latest and greatest material.
Account executive
4. Analysis: We’ve seen multiple ElasticGPT chats where teams use ElasticGPT to summarize large articles or data sets.
We’ve also observed a flywheel effect when enabling ElasticGPT. As employees come across outdated information in the responses, they are taking action to update or inform content owners. This organically improves our knowledge base, allowing us to use more updated information and making ElasticGPT more reliable.
What's next?
As we evaluate what’s next on our generative AI roadmap, specifically for ElasticGPT, we are thinking about it in the following dimensions:
Expanding our knowledge base: We’re looking to add incremental data sources to our knowledge base to provide access to a wider range of information.
Scaling with a managed API service: Building on our approach of a “central landing point,” we want to make it easier for our business groups to get started with generative AI. We’re developing a managed API service that teams can use to experiment in this space.
Building function-specific experiences: We plan to add specialized internal models to support function-specific use cases like in finance and legal with different models using our Elastic inference APIs. This allows access to fine-tuned models for specific functions and out-of-the-box options, ensuring flexibility and precision for diverse business needs.
Incorporating automation: We plan to see how we can incorporate agentic workflow automation for manual and routine tasks with predefined goals.
Embrace generative AI in your workflows
Thinking about building a generative AI tool for your workplace? A successful release requires planning and preparation. Before you begin your build, your organization should define a set of guidelines and frameworks around how and where it's safe to use generative AI tools. These guidelines outline important principles like ensuring the protection of sensitive data as well as considering aspects like the copyright of the created material.
Generative AI tools can be powerful assets, but they also bring a new set of risks that should be considered. Establishing your guidelines, data strategy, and frameworks upfront will help you navigate discussions around what you will be doing as well as what you will not be doing. In other words, you’ll be able to define what capabilities and data sources will be in the scope of your build(s) and how those outputs should be used.
Getting started with Elastic’s generative AI capabilities is easy using our AI Playground. You can unlock powerful generative AI capabilities using LLMs with a free 14-day trial. Test out ingesting your data, build a proof of concept, and kick the tires on Elastic's machine learning and RAG capabilities. Deploy any data in any cloud — or multiple clouds — in real time, at scale.
Dive deeper into how to operationalize generative AI at your organization or get started in the AI Playground.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print