Enriching Your Postal Addresses With the Elastic Stack - Part 3
This blog post is part 3 of a series of 3:
- Importing BANO dataset with Logstash
- Using Logstash to lookup for addresses in BANO index
- Using Logstash to enrich an existing dataset with BANO
In the previous post, we described how we can transform a postal address to a normalized one with the geolocation point, or transform a geolocation point to a postal address.
Now, let's say we have an existing dataset we want to enrich. Here’s how we’ll do it.
Enriching a CSV File
Anytime I have to read a file from Logstash, I actually like to use Filebeat. So, I changed the input part of Logstash and instead of using an http-input plugin, I'm now using a beat-input plugin:
input {
beats {
port => 5044
}
}
In filebeat.yml file, I configured this:
filebeat.prospectors:
- type: log
paths:
- /path/to/data/*.csv
close_eof: true
output.logstash:
hosts: ["localhost:5044"]
I also added X-pack monitoring to get some insights about the pipeline execution:
xpack.monitoring.enabled: true xpack.monitoring.elasticsearch: hosts: ["localhost:9200"]
In addition, I create a naive load test where I'm doing 10 iterations for processing the data:
cd filebeat* time for i in `seq 1 10`; do echo Launch $i rm data/registry ; ./filebeat --once done cd -
Here is the dataset I have as an input:
$ wc -l data/person_dataset.csv
2499 data/person_dataset.csv
So, around 2500 lines.
The data looks like this:
3,Joe Smith,2000-11-15 23:00:00.000000,male,3,Paris,France,FR,47.26917867489252,-1.5316220472168889,44000 24,Nail Louisa,1980-05-02 22:00:00.000000,male,3,Nantes,France,FR,47.18584787904486,-1.6181576666034811,44000M 36,Lison Nola,1985-09-23 22:00:00.000000,female,3,Nantes,France,FR,47.168657958748916,-1.5826229006751034,44000 45,Selena Sidonie,1964-10-18 23:00:00.000000,female,0,Paris,France,FR,48.82788569687699,2.2706737741614242,75000
We need to parse the data with a CSV filter:
csv {
columns => ["id","name","dateOfBirth","gender","children","[address][city]","[address][country]","[address][countrycode]","[location][lat]","[location][lon]","[address][zipcode]"]
convert => {
"children" => "integer"
"[location][lat]" => "float"
"[location][lon]" => "float"
}
remove_field => ["host", "@version", "@timestamp","beat","source","tags","offset","prospector","message"]
}
Because we have the geolocation points as an input, we will use the slowest strategy that we saw in the previous post: sorting by geo distance.
To make sure I'm not slowing down the pipeline, I replaced the stdout codec with dots:
output {
stdout { codec => dots }
}
It took 3m3.842s to do the 10 runs.
Which means around 18 seconds to enrich 2500 documents, so around 140 documents per second.
Not that bad.
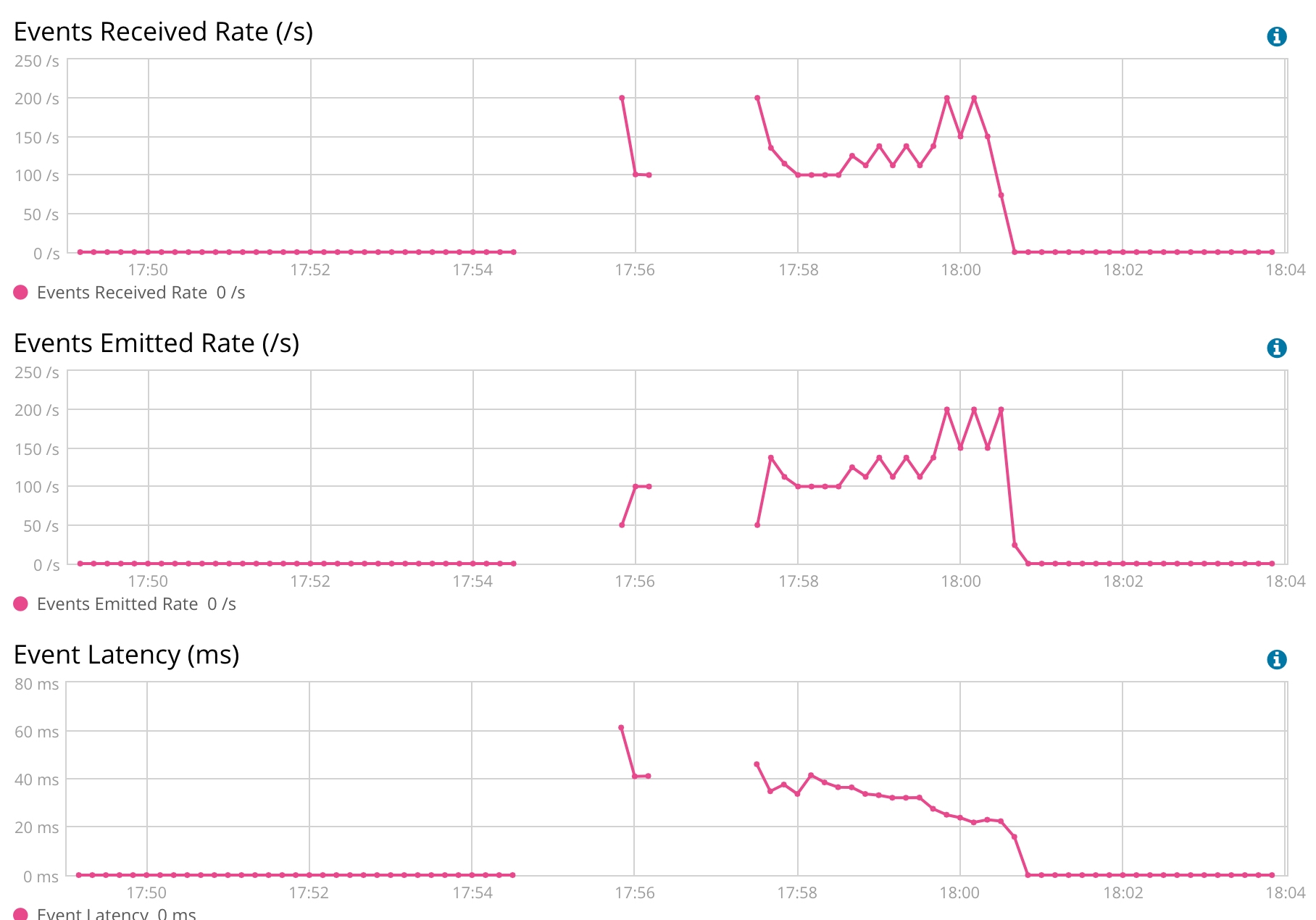
If we look at the Logstash monitoring, we can see that the event latency is around 20-40ms.
Logstash Monitoring
Logstash Pipeline
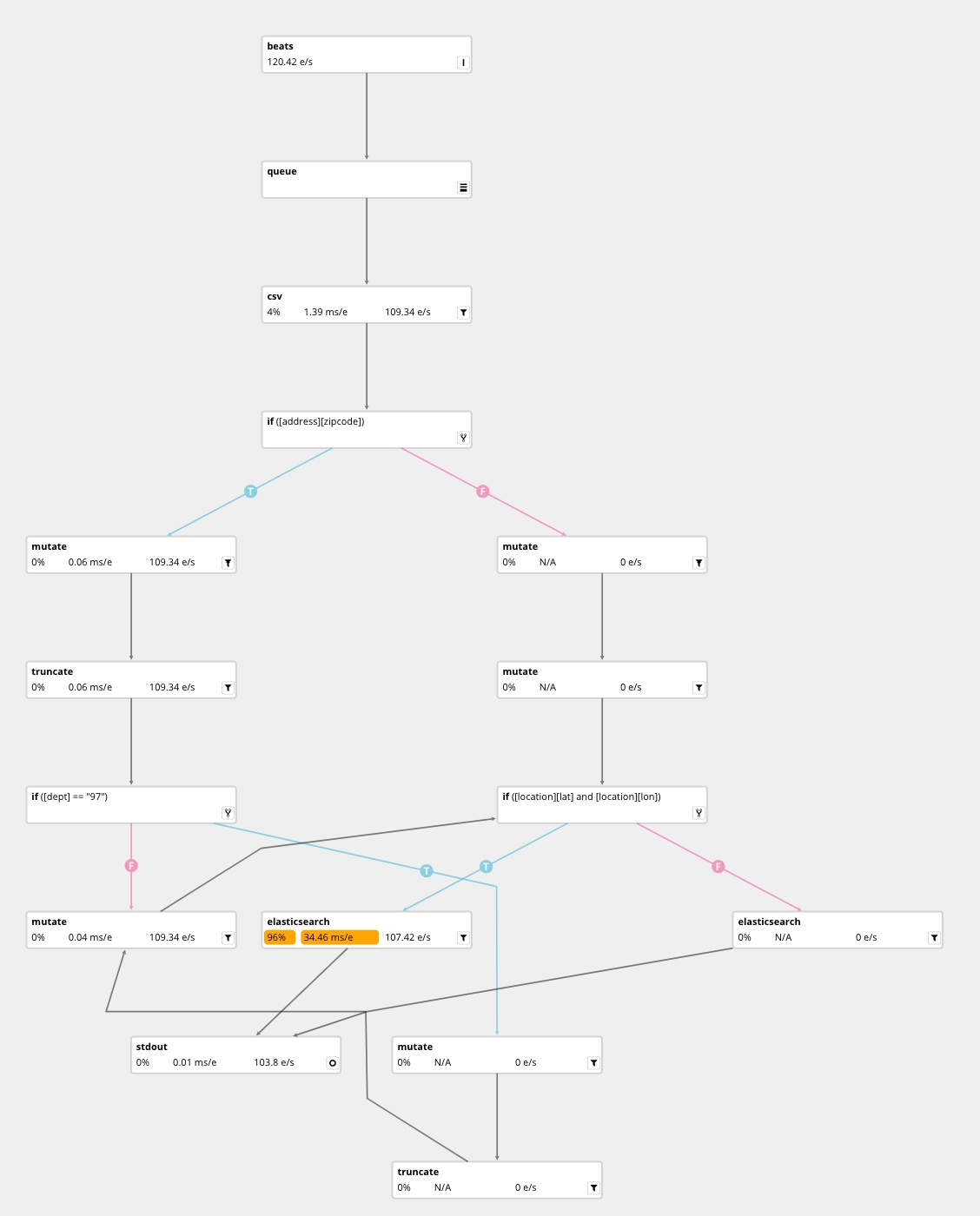
We can easily spot the bottleneck.
Elasticsearch Filter Plugin
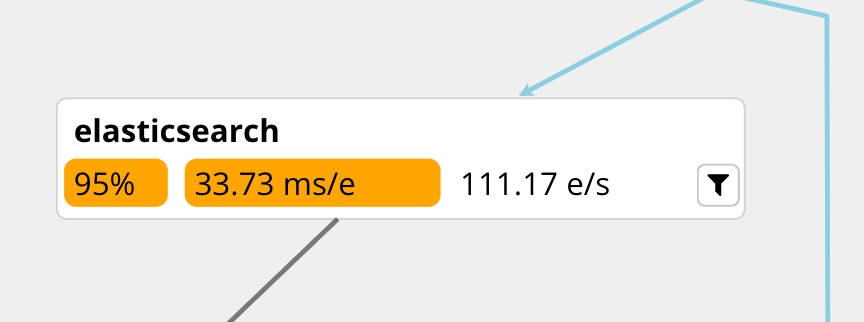
Doing lookups in Elasticsearch is indeed slowing down our process here, but not by much. I would say 34ms per event at average.
Pretty much acceptable for an ETL operation. That's one of the reason doing slow operations in Logstash is much better than using Elasticsearch as an ingest pipeline: the ingest pipeline is called on during the indexing operation and having long running index operation fills up the Elasticsearch indexing queue.
Connecting Other Data Sources
You can also imagine reading from another source than a CSV with Filebeat, such as directly reading existing data sitting in a SQL database using a jdbc-input plugin.
That would look like something like this:
jdbc {
jdbc_driver_library => "mysql-connector-java-6.0.6.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/person?useSSL=false"
jdbc_user => "root"
jdbc_password => ""
schedule => "* * * * *"
parameters => { "country" => "France" }
statement => "SELECT p.id, p.name, p.dateOfBirth, p.gender, p.children, a.city, a.country, a.countrycode, a.lat, a.lon, a.zipcode FROM Person p, Address a WHERE a.id = p.address_id AND a.country = :country AND p.id > :sql_last_value"
use_column_value => true
tracking_column => "id"
}
If this doesn’t work for you, you can also connect and enrich existing data in Elasticsearch, which is available in one index using the elasticsearch-input plugin.
You now have all the tools to do similar address conversion/enrichment. Note that you can use any dataset available.
My plan is to index some other open data sources in Elasticsearch and try to cover other countries beyond France.
Stay tuned!