A FAIR perspective on generative AI risks and frameworks


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Since the release of ChatGPT in November 2022, companies have either banned or rushed to adopt generative artificial intelligence (GenAI), which is rapidly expanding in use and capabilities. Its powerful yet unpredictable nature poses significant cybersecurity risks, transforming it into a double-edged sword.
However, whether generative AI poses more opportunity or risk is not necessarily the right question to ask. As with everything, the truth lies somewhere in the middle, or as we like to say at Elastic, “IT, depends.” But one thing is certain: as we integrate AI into more aspects of our lives and work, understanding the GenAI cybersecurity risks and how to manage them can no longer be avoided.
Within our InfoSec objective of keeping Elastic secure, we need to make sure we address the risks we are facing. To manage these risks, we first need to understand them as well as the space that they operate in. So, we took it upon ourselves to go through a long list of articles, studies, and frameworks and share what we’ve learned here.
This blog explores existing GenAI management frameworks, identifying common themes and unique perspectives. We then delve into the threats and risks associated with generative AI, categorizing them based on their impact and potential consequences. A simplified example of a FAIR™ risk analysis of a GenAI risk illustrates the approach. Finally, we contextualize these risks within broader security and operational contexts, differentiating between genuinely new concerns and those that represent an evolution of existing cybersecurity challenges.
A survey of existing frameworks
Here is a summary comparison of the frameworks reviewed, highlighting their core strengths and focus areas.
| Framework | Core strength | Focus area |
| NIST AI Risk Management Framework | Broad, overarching risk management | Integrates with organizational policies |
| NIST’s Taxonomy and Terminology of Attacks and Mitigations | Standardized terminology and secure deployments | Categorizes AI threats and mitigations |
| Databricks AI Security Framework | Technical focus across the AI lifecycle | Identifies and mitigates risks across AI components |
| FAIR-AIR approach | Strategic, financial risk perspective | Quantifies generative AI risks and integrates financial estimates |
| AWS Generative AI Security Scoping Matrix | Flexible framework with structured categorization | Navigates generative AI deployment security challenges |
| OWASP Top 10 for LLM | Specificity to LLM security | Addresses LLM vulnerabilities and prevention strategies |
| Berryville Institute’s Architectural Risk Analysis of LLM | Focus on transparency and detailed risk identification | Advocates security engineering from the design phase |
| Gartner’s AI TRiSM | Comprehensive lifecycle approach | Manages trust, risk, and security in AI deployments |
NIST AI Risk Management Framework
The NIST AI Risk Management Framework offers a holistic AI risk management approach, focusing on governance, risk mapping, measurement, and management. The main strength of the framework is a broad, overarching perspective on risk management that integrates with organizational policies. NIST is also preparing A Plan for Global Engagement on AI Standards (NIST AI 100-5) and the Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (NIST AI 600-1). Collectively, these frameworks provide a comprehensive approach to AI risk management, focusing on standardization, terminology, and practical guidance for secure AI deployment.
NIST’s Taxonomy and Terminology of Attacks and Mitigations
NIST’s Taxonomy and Terminology of Attacks and Mitigations outlines a framework for understanding adversarial attacks on AI, categorizing these threats and their mitigations within a structured taxonomy. It covers both predictive and generative AI, addressing the security and privacy challenges unique to machine learning. The aim is to standardize terminology and guide the secure deployment and management of AI systems, enhancing the understanding of adversarial machine learning risks and defenses.
Databricks AI Security Framework
The Databricks AI Security Framework proposes a holistic strategy for securing AI systems, identifying risks across AI system components and offering mitigation controls. The main strength of the framework is that it provides a comprehensive and technical focus across the AI system's lifecycle, promoting inter-team collaboration with actionable controls.
FAIR-AIR approach
The FAIR-AIR approach focuses on quantifying generative AI risks through a detailed methodology, including AI risk posture management and the integration of FAIR for financial risk estimates. It covers five vectors of GenAI risks, emphasizing the importance of understanding and managing Shadow AI, foundational large language model (LLM) development, hosting, third-party management, and adversarial threats. The strength of the framework comes from its strategic, financial perspective on risk, aligning with broader organizational and cybersecurity risk management practices.
AWS Generative AI Security Scoping Matrix
The AWS Generative AI Security Scoping Matrix is designed to help teams navigate GenAI deployment security with a flexible categorization of use cases. It distinguishes generative AI applications across five scopes with specific security disciplines, aiding in focused security effort prioritization, from a customer perspective. The main strength of the approach is its structured yet flexible framework, applicable across a wide range of GenAI applications and industries, focusing on tailored security considerations.
OWASP Top 10 for LLM
OWASP Top 10 for LLM outlines major security vulnerabilities specific to LLMs, offering practical prevention strategies. It addresses threats that are unique to LLMs like prompt injection and training data poisoning, emphasizing robust and new security practices. Its strength comes from its specificity to LLM security, providing actionable recommendations.
Berryville Institute’s Architectural Risk Analysis of LLM
The Architectural Risk Analysis of Large Language Models from the Berryville Institute for Machine Learning delves into LLM-specific risks, advocating for security engineering from the design phase and suggesting regulatory measures. The research identifies 81 LLM-specific risks and emphasizes the top 10, focusing on attacker actions and design flaws. The strength of the research comes from its focus on transparency and detailed risk identification for LLMs and emphasis on better management and regulatory compliance.
Gartner’s AI TRiSM
Gartner's AI TRiSM framework focuses on trust, risk, and security management for AI implementations. It aims to ensure AI systems are reliable, safe, and compliant with ethical and regulatory standards. The framework advocates for a comprehensive approach across the AI lifecycle, addressing transparency, security, and ethical challenges. By prioritizing these pillars, TRiSM guides organizations in responsibly deploying and managing AI technologies.
A FAIR view of generative AI risks
The balance between strategic oversight and technical detail is delicate. While all the frameworks have their strengths, they also look at the problem from their own perspective or specific scope — each framework's strengths cater to different aspects of AI risk management and security.
Elastic InfoSec's risk management program is built around the FAIR quantitative risk analysis model. The FAIR philosophy is about conceiving risk as an uncertain event, the probability and consequences of which need to be measured. Risk is defined as the probability of a loss relative to an asset. Threats enter this definition as factors influencing the probability of a loss.
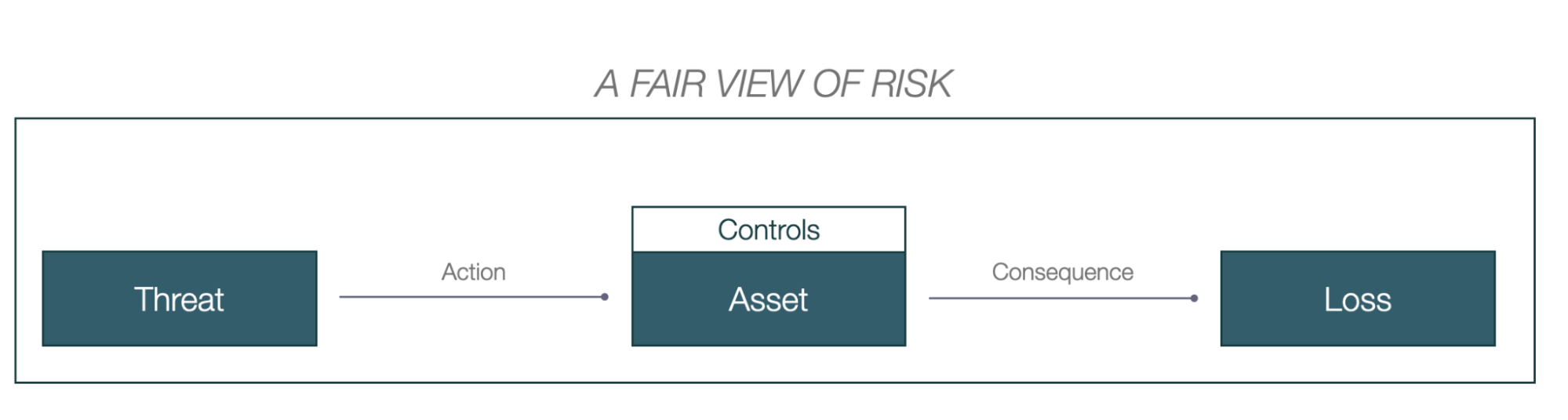
We make an explicit distinction between threats or initial exploits — which serve as entry points or methods for threat actors to potentially compromise the system — and risk scenarios, which include the business impacts and losses caused by such exploits. This distinction helps in understanding the relationship between the methods threat actors might use and the types of harm or compromise they can lead to.
Examples of the threat landscape
Elastic’s 2024 LLM Safety Assessment highlighted common LLM threat techniques, applications, and mitigations. Here is a summary of the threats we identified:
Prompt injection and jailbreaking are distinct attacks on AI models with different targets and implications. Prompt injection manipulates applications built on generative AI by combining untrusted user input with a developer's trusted prompt, exploiting the model to produce prohibited or unexpected responses. Jailbreaking, on the other hand, bypasses the model's built-in safety filters, aiming to unlock restricted capabilities and generate unsafe or unethical content.
Model poisoning occurs when adversaries intentionally tamper with the learning process of a model, often by injecting malicious data into its training set, compromising its performance or causing incorrect predictions or decisions. A specialized form of poisoning attacks is backdoor attacks, where a model is trained to produce incorrect outputs only when presented with inputs containing a specific trigger that would otherwise function normally.
Training data poisoning involves introducing harmful or misleading information into the data set that trains a model. The goal is to corrupt the model's learning process, leading to biased, inaccurate, or malicious behavior.
Model overloading attacks, including sponge attacks and input manipulation, degrade a model's performance or availability by overwhelming it with complex or recursive inputs. This strain on the system's resources can cause slowdowns or failures.
Model inversion attacks involve reconstructing sensitive information about a model’s training data. By carefully analyzing the model's outputs, an attacker can infer details about the input data or the data used to train the model.
Membership inference attacks aim to determine if a specific data point was part of a model's training data set. Unlike model inversion attacks, which reconstruct information about the training data as a whole, membership inference specifically targets the presence of individual data points in the training set.
Evasion attacks involve deliberately crafting inputs to mislead models into generating incorrect outputs. These inputs appear normal to humans but exploit the model's weaknesses to induce errors.
Each of these exploits represents a different approach to interacting with or manipulating AI models — either the model directly or its training or testing data — at different stages throughout their lifecycle, potentially leading to various risks.
Risk scenarios
The threats posited above are just a few of the techniques that adversaries can use to achieve their goals. There are many different reasons why an adversary would attack an organization via an AI model, but a few could include:
Sensitive data exfiltration: The potential consequence of initial exploits like prompt injection, where sensitive data is deliberately or inadvertently revealed or extracted through the model's interactions or outputs.
Threat: Prompt injection, model inversion attacks, membership inference attacks
Asset: Data
Example loss event (quantifiable risk statement): The risk associated with an impact to the confidentiality of sensitive information as a result of unauthorized access and extraction of information due to prompt injection
Unintentional data leakage: The inadvertent exposure of confidential information, which can be a consequence of processed inputs or how the model was trained, such as incorporating too much identifiable information in training data.
Threat: Issues more inherently tied to the model's development and operational processes, such as insufficient data anonymization, inadvertent model responses, model overfitting, feature leakage, and improper data segmentation
Asset: Data
Example loss event (quantifiable risk statement): The risk associated with an impact to data privacy as a result of accidental exposure of sensitive information due to oversight or failure in securely handling data inputs/outputs
Biased data/outputs: These can stem from initial exploits like model poisoning, but more often, they would arise from inherent biases in the data collection process itself.
Threat: Training data poisoning, inherent data bias
Asset: Data, model outputs
Example Loss Event (quantifiable risk statement): The risk associated with an impact to fairness and decision accuracy as a result of the model generating biased or unfair outcomes due to skewed training data or malicious tampering
Harmful/unlawful outputs: Outputs that are inappropriate, harmful, or illegal, which could be directly elicited through exploits like prompt injection
Threat: Prompt injection, adversarial attacks
Asset: Model outputs, user trust
Example loss event (quantifiable risk statement): The risk associated with an impact to user trust and compliance as a result of the model producing outputs that are harmful, offensive, unlawful, or violate policies due to manipulation or failure to adequately filter responses
Hallucinations: These occur when GenAI generates false, misleading, or fabricated information that does not align with factual accuracy or the input data provided. Hallucinations typically result from the inherent limitations or flaws in the model's design, training data, or operational logic rather than from external manipulation or attacks.
Threat: Insufficient training data, complex queries
Asset: Model outputs, user trust
Example loss event (quantifiable risk statement): The risk associated with an impact to the quality of the product relying on the model outputs as a result of the model hallucinating and producing inaccurate, misleading, or false outputs
AI supply chain compromise: This refers to a broad umbrella of risk scenarios and vulnerabilities in the AI software supply chain, which can lead to unauthorized alterations, the introduction of malicious code, or data theft affecting AI models and their supporting environments. Much like traditional software supply chains, AI supply chains inherit many of its most common vulnerabilities. AI-specific threats include deliberate tampering with a model's training process (model poisoning) or the data it uses (data poisoning) — both of which can degrade performance or introduce biases, model theft, or model manipulation or abuse. The model manipulation or abuse of functionality, for example, occurs through misuse of the model's intended functionalities for malicious purposes.
Threat: Prompt injection, adversarial attacks
Asset: Model outputs, system integrity
Example loss event (quantifiable risk statement): The risk associated with an impact to system integrity and functionality as a result of attackers exploiting the model for malicious purposes, such as generating deceptive content or overloading the system
By defining risk scenarios, we can clarify the cause-and-effect relationship between the methods of compromise and their impacts. Potential threats represent the vectors through which the AI system's security can be challenged, while risk scenarios encompass the outcomes or losses that result from successful exploits. Next, we’ll take a look at a fictitious example based on one of the potential GenAI risk scenarios identified here.
FAIR risk example scenario: FAIR loss chain for data exfiltration via prompt injection
The FAIR model breaks down risk into factors that can be quantified (in counts, percentages, or dollar figures) to estimate the probable frequency and probable magnitude of loss. From that we can generate a range of probable outcomes in financial terms to understand the loss exposure.
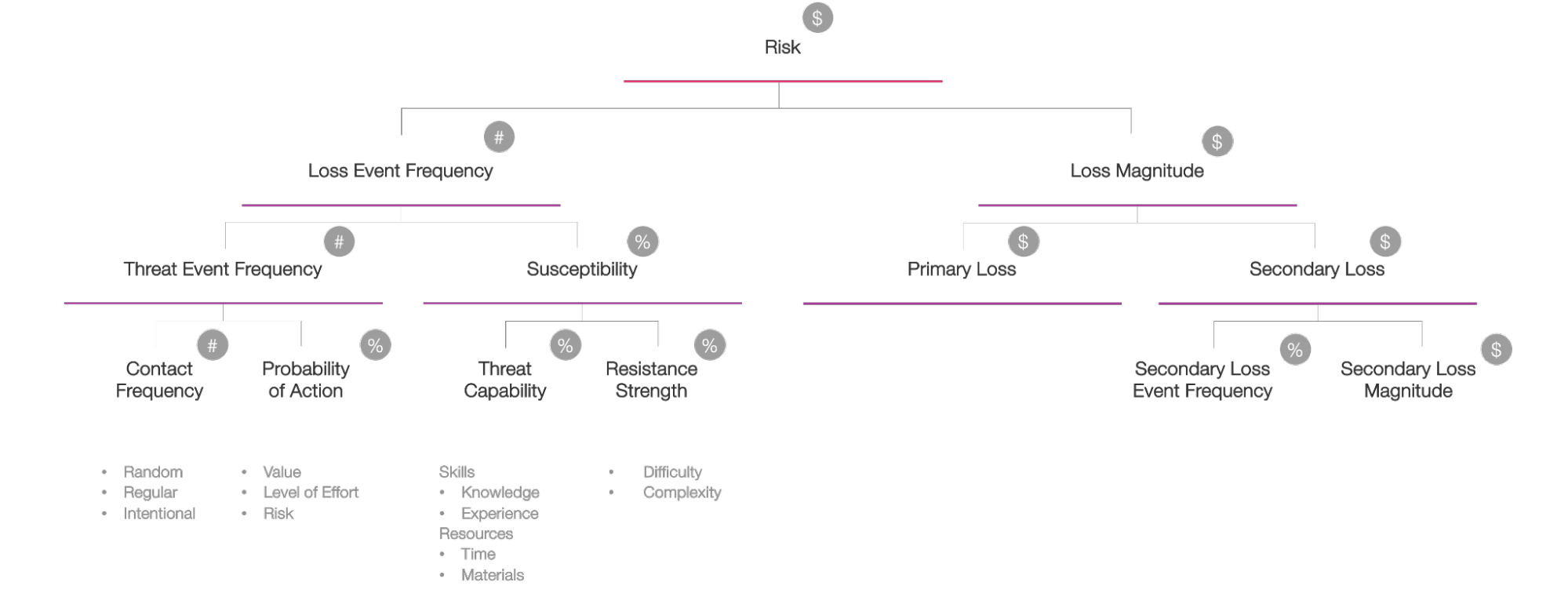
Before diving into the numbers for the FAIR factors, we need to clearly define — or “scope” — the loss event we want to analyze.
Scoping an analysis means figuring out the business decision we’re trying to support. This involves identifying the asset we need to protect, focusing on the most likely threats, and understanding the type of loss we’re worried about and how that loss could happen — essentially, shaping it into a specific loss event or risk scenario.
In our fictitious example, we’re concerned with a prompt injection attack that successfully pulls sensitive data through a GenAI model used by a customer service chatbot. To scope this out, we need to pinpoint the asset (what do we want to protect?), the threat (who or what are we protecting it from?), and the loss event or impact (what are we concerned will happen if we do not properly protect it?):
Threat: Prompt injection. Malicious actors leverage prompt injection attacks to exploit the model’s processing capabilities and biases, causing it to generate prohibited information or perform unauthorized actions. The likelihood of such threat events occurring is driven by the high interaction volume and the attractiveness of the proprietary data.
Asset: Data. The primary asset at risk is the proprietary and sensitive data handled by the company's AI model. This may include customer data, internal business data, and other confidential information processed by the chatbot, which interacts frequently with users, generating a substantial volume of outputs daily.
Loss event (quantifiable risk statement): Sensitive data exfiltration. The risk associated with an impact to the confidentiality of sensitive information as a result of prompt injection, where sensitive data is deliberately or inadvertently revealed or extracted through the model's interactions or outputs.
Analyzing this scenario from a risk perspective will involve several steps in the loss event chain — from the initial threat event to the realization of losses. We do this by detailing the loss chain in a simplified FAIR analysis and break down each step from the initial contact to the final realization of loss.
With our loss event scenario clearly defined, the next step is to gather the necessary data for analysis. When internal systems or model logs can't provide estimates, industry sources can be incredibly helpful in filling those gaps. However, since generative AI is still an emerging field and industry data may be scarce, consulting in-house subject matter experts is crucial for informed analysis. In cases where no concrete data is available, it’s important to remember that the range of possible outcomes can be broad — anywhere from 0% to 100% with 50% often used as the most likely estimate, assuming all outcomes are equally likely.
When estimating risk, we should always consider factors that can help narrow down the range. For example:
Nature of data: Sensitive, confidential data is more attractive to attackers and potentially more complex, leading to higher vulnerability. Public or internal data is less sensitive, reducing the overall vulnerability.
- Model complexity and/or customization: Customized proprietary models may introduce unique vulnerabilities that are not as well-tested. Standardized open source models benefit from extensive community testing and improvements, leading to lower vulnerability.

Contextualizing generative AI security concerns
As we delve deeper into the security implications of generative AI, it's important to contextualize each identified threat and risk, differentiating between what's genuinely new and what represents an evolution of existing cybersecurity challenges. GenAI is not inherently high-risk; rather, it is the context and manner in which AI is developed, deployed, and used that determines its risk profile. AI in and of itself is just another technology, presenting a new attack surface like many innovations before it. Its potential dangers are not unique but are contingent upon the specific applications and environments in which it is integrated.
The way organizations choose to develop and utilize AI systems plays a crucial role in defining their safety and security. Consequently, the types and magnitudes of AI-related risks will vary significantly across different companies, influenced by factors such as industry, scale of deployment, and the robustness of implemented safeguards. Below we explore how the GenAI risks fit into broader security and operational contexts.
Risks stemming from prompt injection: A novel concern
Truly unique to generative AI, prompt injection leverages the model's own processing to generate specific responses. This threat is novel because it directly exploits the non-deterministic nature and interactive, generative capabilities of AI models, which do not have a direct analog in traditional IT security. This represents a significant security concern as it introduces entirely new vectors for attack that traditional security measures may not address.
Biased data and/or outputs, model inversion/membership inference, and DoS attacks: Evolution of existing concerns
Model/data poisoning: While the manipulation of training data or model behavior is a concern in the context of GenAI, it parallels challenges in machine learning operations (MLOps) and data quality management. These are not entirely new concerns but rather adaptations of existing issues in data management and system integrity.
DoS attacks: The concept of overloading a system to degrade performance or availability is well-understood in cybersecurity. For GenAI, the mechanisms might vary like complex queries, but the fundamental challenge remains consistent with traditional DoS mitigation strategies.
Model inversion/membership inference: Data privacy and potential leakage concerns are not unique to GenAI and often arise from the ability to extract sensitive details from aggregated or anonymized data outputs. Whether through statistical analysis, pattern recognition, or other data inference techniques, the underlying information can sometimes be deduced, posing privacy concerns. This issue is akin to what is observed with model inversion and membership inference attacks in the context of GenAI, where the goal is to infer sensitive training data information from model outputs.
Bias, hallucinations, and harmful or unlawful outputs: Ethical and legal considerations
These risks primarily raise ethical, legal, and privacy concerns rather than traditional security threats. They relate to the consequences of the outputs generated by AI models rather than unauthorized access or system compromise. While these are not security risks in the conventional sense, they necessitate a comprehensive governance framework that addresses legal, ethical, and privacy considerations in generative AI deployment and use. Mitigation strategies require a multidisciplinary approach involving legal compliance, ethical guidelines, and robust content moderation and filtering mechanisms.
Supply chain compromise: Consistent with traditional concerns
The threat of supply chain compromise involving unauthorized alterations or the introduction of malicious code remains consistent with existing cybersecurity challenges that now extend into the AI domain. While the components at risk, such as training data sets and AI models, are specific to generative AI, the nature of the threat aligns with traditional supply chain security concerns. Traditional supply chain compromise strategies focus on securing the build chain and CI/CD pipelines that now incorporate AI components. This includes practices like securing code repositories, validating third-party components, and continuous monitoring for anomalies.
Our journey is ongoing
Managing the risks associated with GenAI is not just about addressing the immediate threats but also about understanding the broader context in which these technologies operate. As we’ve explored, the risks are multifaceted, ranging from novel challenges like prompt injection attacks to the evolution of familiar concerns, such as data privacy and supply chain vulnerabilities.
The most important questions we need to ask ourselves regarding AI security concerns, which are similar to those for any other product or service, revolve around three critical areas:
Building AI products and systems: How are we building AI products? This involves scrutinizing the development processes, ensuring robust security measures are integrated from the outset and adhering to best practices in software engineering.
Deploying and integrating AI into the existing landscape: How are we deploying AI products? Deployment strategies must include secure implementation, regular updates, and monitoring to safeguard against vulnerabilities.
Using AI-based third-party services: How are we using AI third-party services? It is essential to evaluate the security protocols of external vendors, ensuring they align with regulatory and compliance requirements as well as our own standards.
On Elastic’s InfoSec team, our approach to generative AI risk management is rooted in the FAIR quantitative risk analysis model, which provides a structured way to assess and mitigate these risks. By breaking down complex threats into quantifiable components, we can better understand the potential impacts on our organization and develop targeted mitigation strategies. The frameworks we reviewed offer valuable insights, but it’s clear that no single framework can address all aspects of AI risk. Instead, a comprehensive approach that combines strategic oversight with technical detail is essential.
As generative AI continues to integrate into our workflows and products, the key to managing its risks lies in continuous learning and adaptation. Our journey is ongoing, but you can see how we’re using generative AI for the better.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print