Crafting a hybrid geospatial RAG application with Elastic and Amazon Bedrock


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
With Elasticsearch and its vector database, you can build configurable search and trusted generative AI (GenAI) experiences that scale from prototype to production fast. Key features include:
Built-in support for geospatial data, enabling fast queries of location-based information
Vector database capabilities for storing, managing, and querying vector embeddings
Integration of traditional lexical search with geospatial and vector search functionalities
Elastic stands out by combining these features in a single data platform — the Elastic Search AI Platform. This trifecta integration facilitates modern generative AI use cases and provides significant value to customers by simplifying data management for enterprises.
In this blog post, we'll explore how to build a powerful retrieval augmented generation (RAG) system that incorporates geospatial data using Elasticsearch, Amazon Bedrock, and LangChain. This hybrid approach combines lexical search, geospatial queries, and vector similarity search to create an intelligent real estate assistant capable of providing personalized property recommendations.
Technology overview
The integration of AI with geospatial data represents a significant advancement in information retrieval and decision support systems. Traditional search engines often struggle with location-based queries, but by combining the power of large language models (LLMs) with specialized geospatial databases, we can create more intelligent and context-aware applications.
Amazon Bedrock gives the power of choice to developers to choose any of the industry leading foundation models (FMs) from the leading AI providers with simplified, unified APIs so that developers can build and scale generative AI applications in an enterprise.
Elastic can store, run queries, and perform geospatial analysis at Elastic speed and scale. Elastic is also a production-ready billion scale vector database. This enables users to create, store, and search vector embeddings within Elastic.
This also brings up a unique feature of Elastic where you can combine traditional lexical search with geospatial querying capabilities and add on to those vector similarity searches to craft innovative generative AI applications.
In order to build an application from the ground up, let's look at RAG.
Retrieval augmented generation
RAG is a powerful technique that enhances LLMs by integrating external knowledge sources. It improves the accuracy, relevance, and trustworthiness of LLM outputs without requiring model retraining.
RAG also enhances text generation by incorporating information from private or proprietary data sources. This technique combines a retrieval model that searches large data sets or knowledge bases with a generation model like an LLM to produce readable text responses.
Application architecture
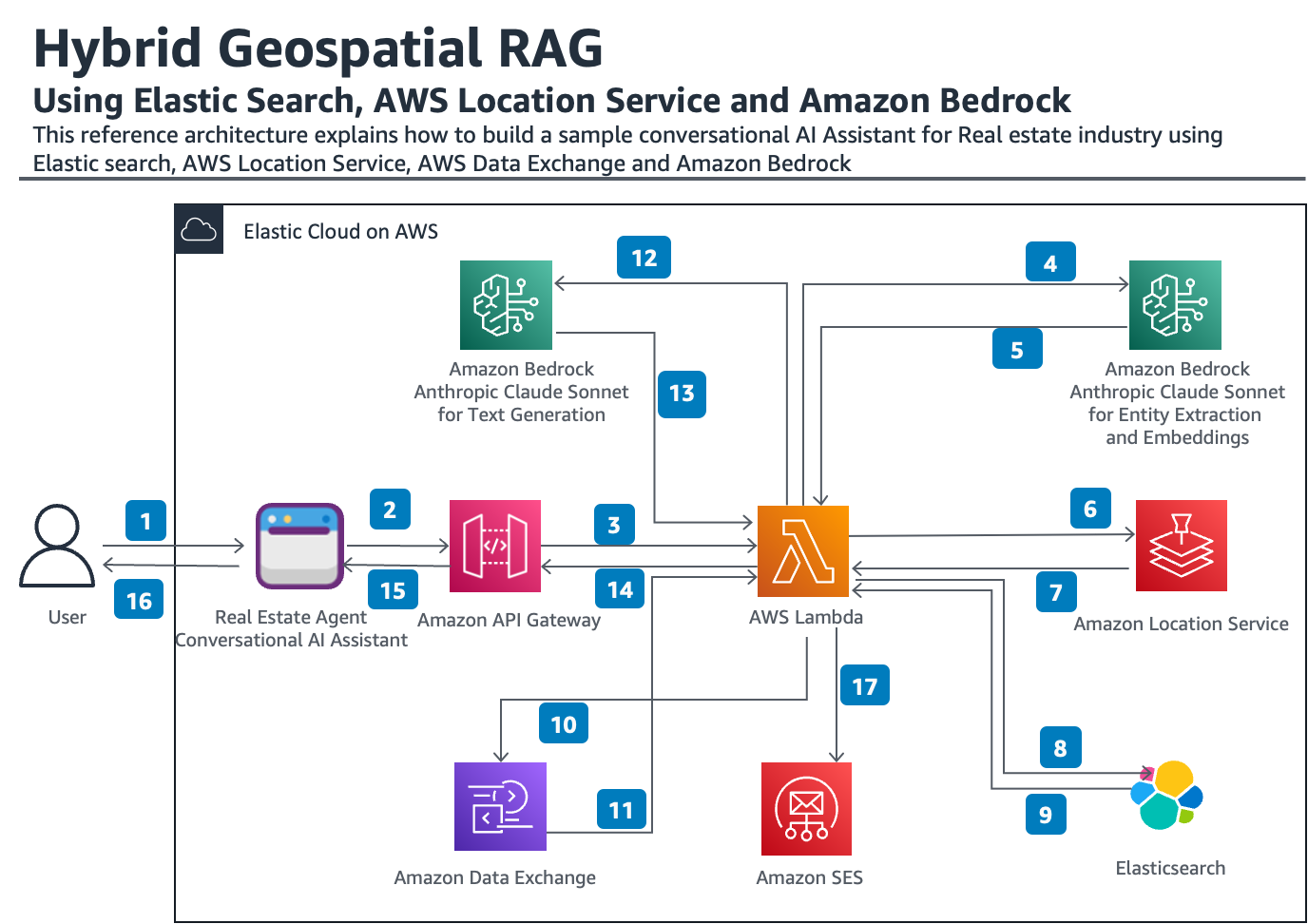
This reference architecture explains how to build a sample conversational AI assistant for the real estate industry using Elasticsearch, AWS Location Service, AWS Data Exchange, and Amazon Bedrock.
Step 1: The user submits a query about properties in an area — “Find me townhomes with a swimming pool within 2 miles of 33 Union Sq, Cupertino, CA.”
Step 2: The conversational AI assistant application calls the REST API through the Amazon API Gateway.
Step 3: The REST API makes a call to the AWS Lambda function forwarding the user prompt.
Step 4, 5: The AWS Lambda function calls Anthropic Claude 3 Sonnet through Amazon Bedrock for extracting entities like address, distance, and type of property. It also generates embeddings of the keywords.
Step 6, 7: The AWS Lambda function passes the address to AWS Location Service to get the corresponding geo-coordinates (geocoding).
Step 8, 9: The AWS Lambda function makes a hybrid geospatial call (keyword kNN + geo-distance) to Elasticsearch to retrieve relevant properties as context.
Step 10, 11: The retrieved data is augmented with other relevant attributes of the location from data sources hosted in AWS Data Exchange.
Step 12, 13: The retrieved and augmented data is passed as context to Anthropic Claude 3 Sonnet for generating a summary.
Step 14, 15, 16: The summary is passed back to the AI assistant and to the user.
Step 17: Optionally, the details are also emailed using Amazon SES to the user.
Implementation details
Use case
We will develop a generative AI application to enhance the user experience in real estate property searches. This application features a conversational AI assistant that answers questions about property listings in our database. Users can interact with the assistant using natural language.
For example, a user might ask: "Find a single family home near Frisco, TX within 5 miles with a backyard swimming pool."
Named entity recognition (NER)
NER, or entity extraction, is a natural language processing technique that identifies and classifies named entities within text. NER algorithms detect and extract specific entities, such as person names, organizations, locations, dates, and custom categories, from unstructured text.
In our case, we will extract the search property location (example: San Francisco) in which a user is looking for the property type, such as "Single family home" or a "Condominium"; the distance within which these properties can be found; and any additional property features, such as a swimming pool in the backyard.
We create a prompt template with a single-shot prompting technique giving an example for the LLM on how to extract entities from the user entered prompt. Here is an example code snippet for our real estate property listing use case.
Steps
Create a user prompt template and pass the end user prompt as an input variable.
Next, invoke Amazon Bedrock service and pass the above inference to a LLM of your choice. In this case, we are using Anthropic Claude Sonnet 3 as an example.
For a given end user prompt as input, the output from the named entity recognition would be like:
| Input user prompt |
| “Find me townhomes near Frisco, TX within 5 miles with a community swimming pool access” |
Output (extracted entities):
| Programming Language: JSON |
{ |
The streamlit app reflects this in the user interface as:
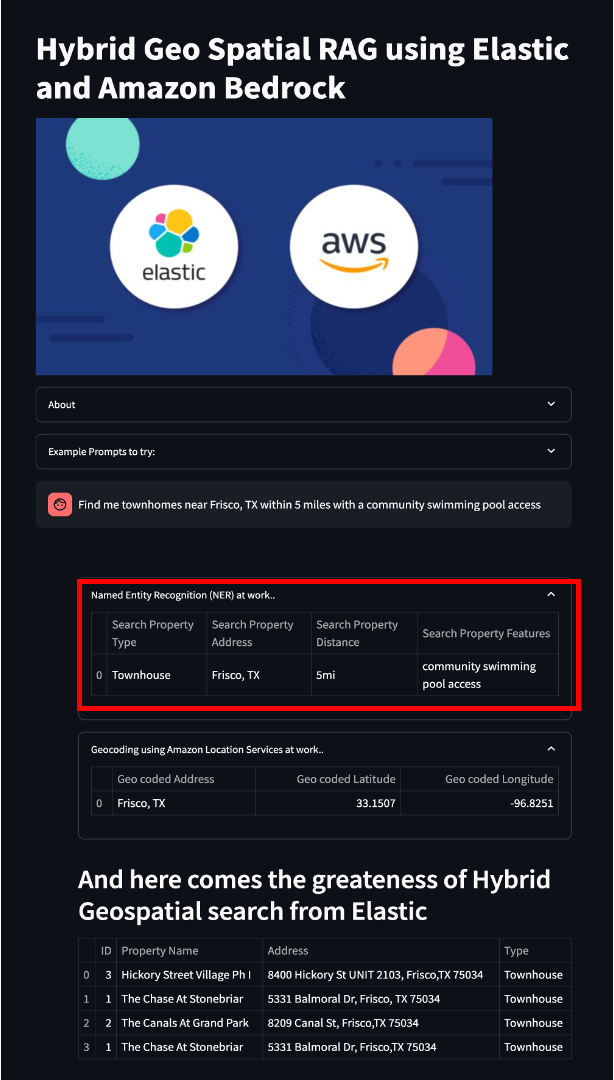
Geocoding using Amazon Location Service
Geocoding is the process of converting addresses like a street address into geographic coordinates (latitude and longitude), which can be used to place markers on a map or identify locations in spatial data. It helps map a physical location, such as "1600 Pennsylvania Ave NW, Washington, DC," into its corresponding geographic coordinates, enabling applications like GPS navigation or any location-based services.
The purpose of geocoding, in our case, is to convert the extracted geographical location from the user prompt into longitude and latitude so that these coordinates can be used to search for real estate property data in Elastic.
Amazon Location Service can be of help here in the geocoding process. Amazon Location Service is a mapping service that allows you to add geospatial data and location functionality to applications, including dynamic and static maps, places search and geocodes, route planning, and device tracking and geofencing capabilities.
Here is the sample code from the Streamlit git repo for geocoding using Amazon Location Service. The output generated from geocoding process will look like this in the Streamlit application:
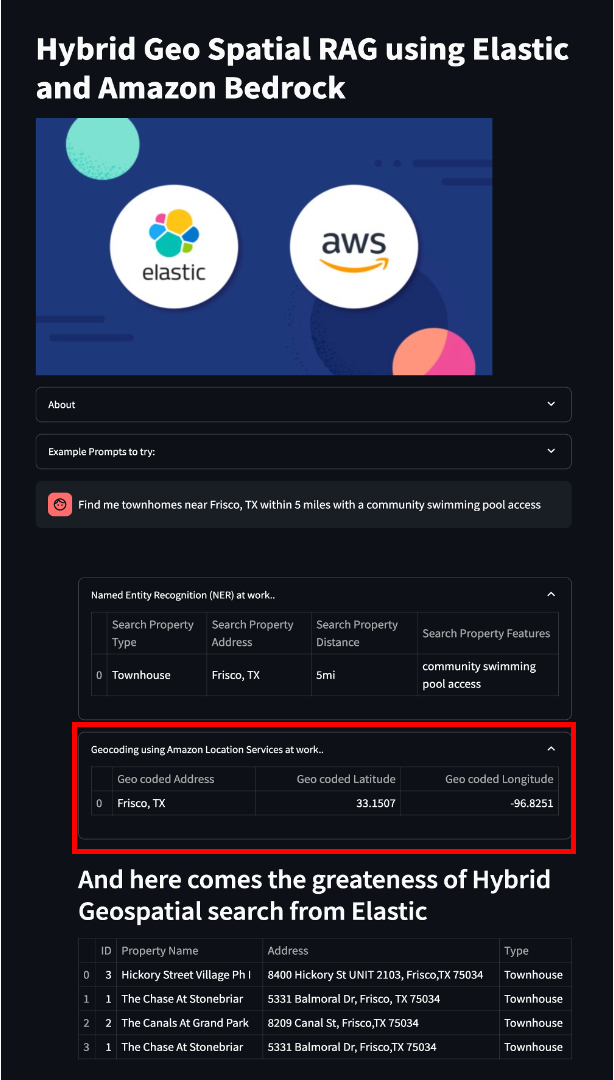
An important output detail that we get from the above geocoding process is the longitude and latitude coordinates, which can be used to perform a geospatial search for data in Elastic.
Hybrid geospatial query in Elastic
The key feature of this application is Elastic's ability to perform a hybrid geospatial search. This search combines:
Lexical search
Geospatial search
Vector similarity search
Elastic executes all of these search types in a single query, creating a powerful and efficient search capability. Here is the code snippet. You can also see this in the GitHub repository.

Notice in the above code:
In #1, We are doing a traditional keyword-based lexical search. For example, we want to search for all listings that have propertyType = “Townhome” properties in Elastic.
In #2, We are doing a semantic search on the field propertyFeatures_v which is a vector field that has the embeddings of the textual equivalent propertyFeatures.
In #3, We are filtering all of the data using the geospatial coordinates (geo_coded_lat and geo_coded_long). In other words, for our Frisco, TX location, find all the real estate property listings within five miles.
Here is how the streamlit app displays the output in the user interface.

Run geospatial RAG
The real estate properties data found from Elastic in the previous query is now passed as an additional context to the LLM via Amazon Bedrock to perform RAG, as shown here.
A couple of things to observe in the code:
Notice how we are passing the results we got from executing Elastic’s hybrid geospatial query as context to RAG.
Again, we are using a prompt template, and we will provide Elastic’s hybrid geospatial query results as the context.
Here, we are forcing the LLM to specifically answer only in the context of the data found in the Elastic’s query.
The output would be a precise recommendation by the LLM answering specifically in the context of knowledge provided as part of the RAG pipeline. Here is an example recommendation that the Streamlit application user interface shows to the end user as a completed response.
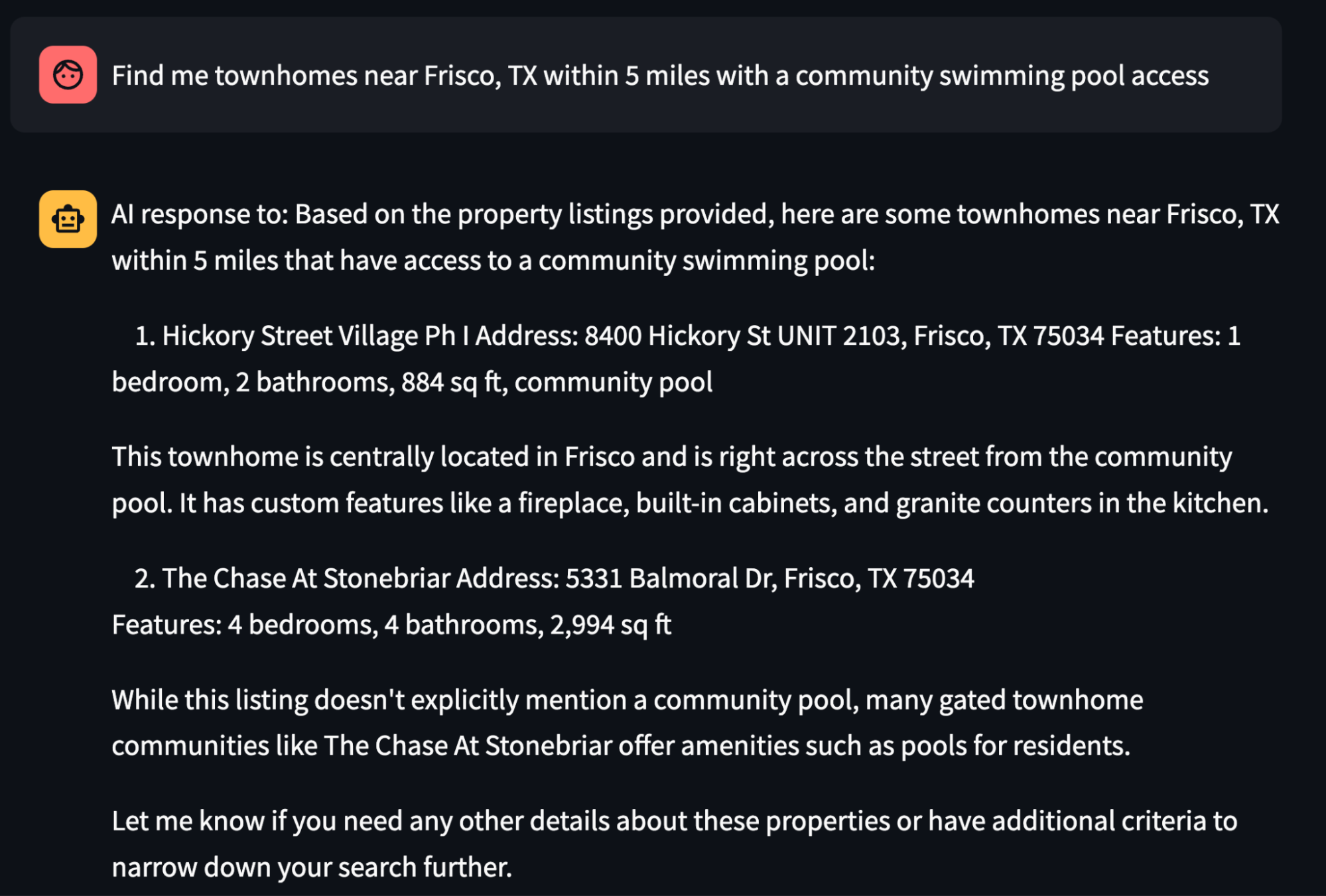
In addition, the streamlit app displays the geospatial results from Elastic plotted on a map, giving a pictorial understanding of where these real estate properties are located.
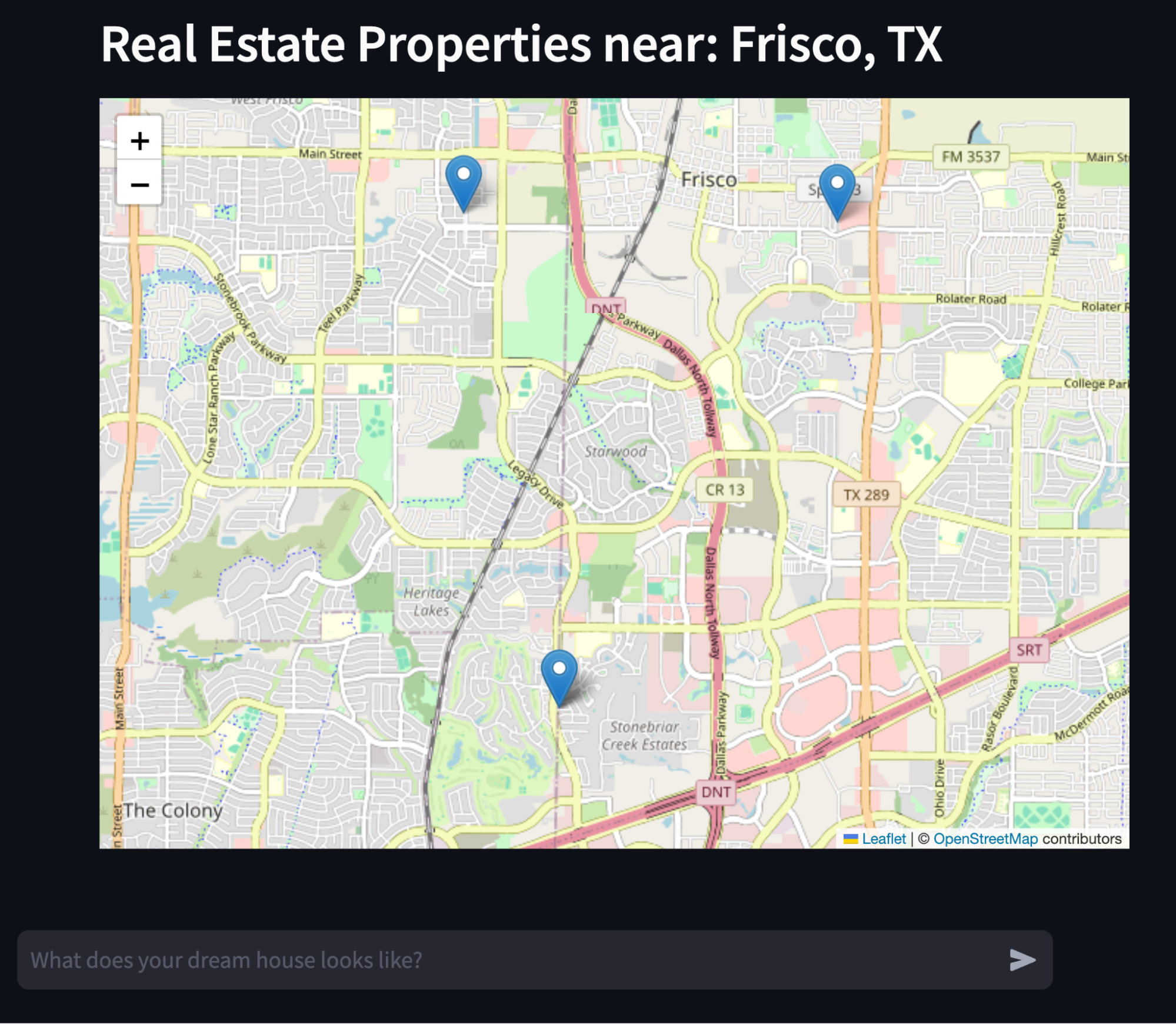
Streamlit app
All of these concepts come together in the form of a streamlit app that showcases how to use Elasticsearch, Amazon Bedrock, Anthropic Claude 3, and Langchain to build a hybrid geospatial RAG solution that uses the geospatial features of Elastic.
Learn more by checking out the GitHub repository and the setup instructions.
Data augmentation using AWS Data Exchange
AWS Data Exchange is a service provided by AWS that enables you to find, subscribe to, and use third-party data sets in the AWS Cloud. You can further augment and enrich your data sets with additional data from AWS Data Exchange. For example, if you want to further enrich your real estate properties geospatial data with other points of interest data, such as hospitals, malls, or nearest pharmacies, AWS Data Exchange can be used.
Explore and integrate resources
Elastic and Amazon Bedrock simplify the development of complex RAG solutions using enterprise data. This combination offers:
Elastic's hybrid geospatial semantic search capabilities
Access to various foundation models through Amazon Bedrock
Easy building and scaling of generative AI applications
In this post, we have:
Outlined the essential building blocks for a hybrid geospatial RAG solution
Provided code examples for implementation
Shared a GitHub repository for hands-on experimentation
We encourage you to explore these resources and integrate them into your own projects.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

