Introducing Filestream fingerprint mode


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In Filebeat 8.10.0 and 7.17.12, we introduced a new fingerprint mode that gives our users an option to use hashing of the files’ content for identifying them instead of relying on file system metadata. This change is available in Filestream inputs.
What is Filestream?
Filestream is an input type in Filebeat that is used for ingesting files from the given paths.
Filestream architecture
To explain what fingerprint mode is and where exactly we introduced it in Filestream, let’s start by explaining the basic architecture of a Filestream input:
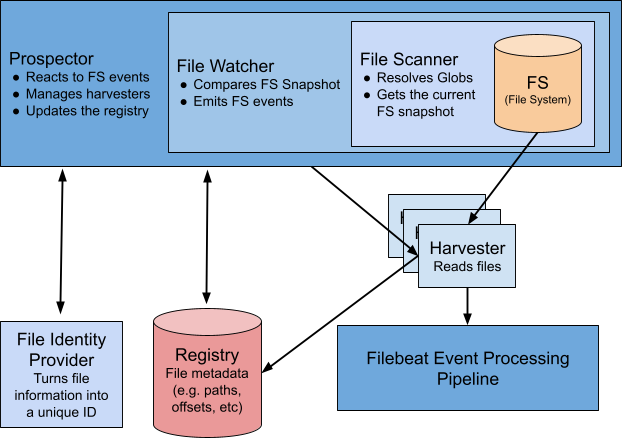
Peeling the onion of the top components:
- File Scanner collects information about all files that match paths of the input.
- File Watcher scans the file system every few seconds, as specified in the prospector.scanner.check_interval setting, and then compares the file system states between checks. If something changes, it emits an event describing the change.
- Prospector makes decisions on what to make out of these file system events: start/stop harvesting a file, add/update/remove the file’s state, etc.
- In order to start working on a file and to manage its state in the registry, the Prospector needs a unique ID for this file, which it gets from the File Identity Provider configured by the file_identity parameter of the input.
- All file states (like offsets) are stored in the Registry — in-memory storage that is flushed to disk every registry.flush interval configured in Filebeat. It’s stored on disk as an operation log.
- Harvesters perform the actual file ingestion and send lines they read to the event processing pipeline that does some enrichment, transformation, queueing, batching, and eventually delivers the events to the output.
When the default approach isn't enough
By default, File Scanner is using file system metadata to compare files when searching for renames/moves such as: <inode>-<device_id> string on Unix systems (more about inode can be found here) and <idxhi>-<idxlo>-<vol> string on Windows (nFileIndexHigh, nFileIndexLow and dwVolumeSerialNumber respectively — read more in the official documentation from Microsoft). The same string is used as a unique file identifier returned by File Identity Provider, and this value is used as a key for each file in Registry to look up the file’s current state.
The whole point of the unique file identifier returned by the File Identity Provider is that it must be stable, meaning it won’t change during the time the file is being ingested by Filestream. It must be stable because Filestream uses this identifier to track file metadata, including the current offset of the file, so it knows where to continue the ingestion.
What if the identifier is not stable? It leads to data loss or data duplication.
Example of the data loss:
- A file ID now matches a different file (not ingested before).
- Instead of reading this file from offset 0, as Filestream is supposed to, the wrong offset information is applied to this file.
- Filestream continues reading the log lines too far forward in the file, skipping log lines. These lines will never make it to the output.
Example of the data duplication:
- A file ID has changed for an existing file.
- It now appears as a new file to Filestream.
- Filestream starts reading it from offset 0 (re-ingestion).
Unfortunately, not all file systems can produce stable device_id and inode values.
File systems cache inodes and reuse them
If you try to run this script on different file systems, you might see different results:
#!/bin/bash
FILENAME=inode-test
touch $FILENAME
INODE=$(ls -i "$FILENAME")
echo "$FILENAME created with inode '$INODE'"
COPY_FILENAME="$FILENAME-copy"
cp -a $FILENAME $COPY_FILENAME
COPY_INODE=$(ls -i "$COPY_FILENAME")
echo "Copied $FILENAME->$COPY_FILENAME, the new inode for the copy '$COPY_INODE'"
rm $FILENAME
echo "$FILENAME has been deleted"
ls $FILENAME
cp -a $COPY_FILENAME $FILENAME
NEW_INODE=$(ls -i "$FILENAME")
echo "After copying $COPY_FILENAME back to $FILENAME the inode is '$NEW_INODE'"
rm $FILENAME $COPY_FILENAMEFor instance, on Mac (APFS) you’ll see:
inode-test created with inode '112076744 inode-test'
Copied inode-test->inode-test-copy, the new inode for the copy '112076745 inode-test-copy'
inode-test has been deleted
After copying inode-test-copy back to inode-test the inode is '112076746 inode-test'As you can see, on APFS all three files have different inode values: 112076744, 112076745, and 112076746. So, this works as expected.
However, if you run the same script in an Ubuntu Docker container:
inode-test created with inode '1715023 inode-test'
Copied inode-test->inode-test-copy, the new inode for the copy '1715026 inode-test-copy'
inode-test has been deleted
ls: cannot access 'inode-test': No such file or directory
After copying inode-test-copy back to inode-test the inode is '1715023 inode-test'You can see that the file system cached the inode value from the first file, which we deleted, and reused it for the second copy with the same filename: 1715023, 1715026, and 1715023.
It does not even have to be the same filename; a different file can reuse the same inode:
# touch x
# ls -i x
1715023 x # <-
# rm x
# touch y
# ls -i y
1715023 y # <-We’ve observed these issues mainly on container/virtualized environments, but it’s up to a file system implementation whether to cache and reuse inodes or not. Theoretically, it can happen anywhere.
inode values might change on non-Ext file systems
Ext file systems (e.g., ext4) store the inode number in the i_ino file, inside struct inode, which is written to disk. In this case, if the file is the same (not another file with the same name) then the inode number is guaranteed to be the same.
If the file system is other than Ext, the inode number is generated by the inode operations defined by the filesystem driver. As they don't have the concept of what an inode is, they have to mimic all inode's internal fields to comply with VFS, so this number will probably be different after reboot — in theory, even after closing and opening the file again.
Sources:
Some file processing tools change inode values
- We’ve seen our customers experiencing problems with using rsync and changed inodes.
- Also, not everyone knows that sed -i creates a temporary file and then moves it to the place of the original file changing the inode value (it’s basically a new file). For example, some users might use sed -i for masking credentials in logs.
Device ID can change
In addition to problems with inode, depending on how disk drives are mounted, it’s possible that the device_id can change after a reboot. However, we’ve already introduced a solution for this problem some time ago: file_identity: inodemarker.
What is fingerprint mode?
The new fingerprint mode is implemented in the File Scanner component to avoid the above-mentioned problems.
The new fingerprint mode switches the default File Scanner behavior from using file system metadata to using SHA256 hash for a given byte range of the file. By default this range is from 0 to 1024 but it’s configurable by offset and length config parameters.
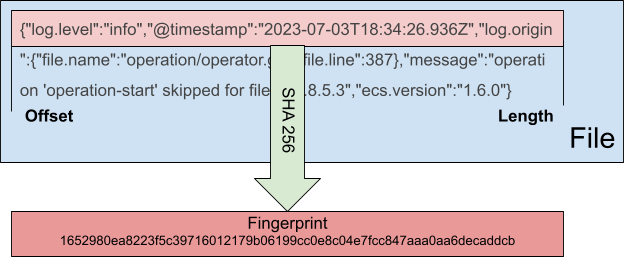
Now that we have this fingerprint information in File Scanner, it’s also propagated with each file system event and it becomes possible to use this fingerprint hash as a unique file identifier in the File Identity Provider. So, there is also a new file_identity: fingerprint option now that allows the use of the fingerprint value as the main file identifier in Registry as well.
What to keep in mind when using fingerprint mode + fingerprint file identity
There are some points one must consider before starting to use this new feature:
- All your logs files must be unique in the configured byte range. Most of the log files are, due to timestamps and just the pure nature of logs, but one must inspect the logs and decide on the offset and length of the fingerprint.
- Once you start using file_identity: fingerprint, you cannot change the offset and length of the fingerprint anymore; it would lead to a total reingestion of all the files that match the paths of the input.
- There is a performance hit — the performance aspect of this feature deserves a separate section in this article:
Performance
From the very early stage of working on this feature, there was a concern regarding the performance hit it would cause in File Scanner. In the end, we would need to open a file, read the amount of bytes set by the prospector.scanner.fingerprint.length config option, and compute a SHA256 out of it. And we would need to do that for every single file that matches the globs in paths.
A slight side note here: in order to implement this new feature, File Scanner had to be changed a lot. So, when I worked on the code, I took this opportunity to refactor some parts of File Scanner and make some optimizations while doing so, mainly reducing the amount of syscalls. I also added a lot of tests to verify the expected behavior. So, there was a suspicion that the new File Scanner (fingerprint mode disabled) is faster since it does not make as many syscalls anymore.
After the fingerprint mode was finally delivered to main, I ran some benchmarks, and the results were interesting to say the least:
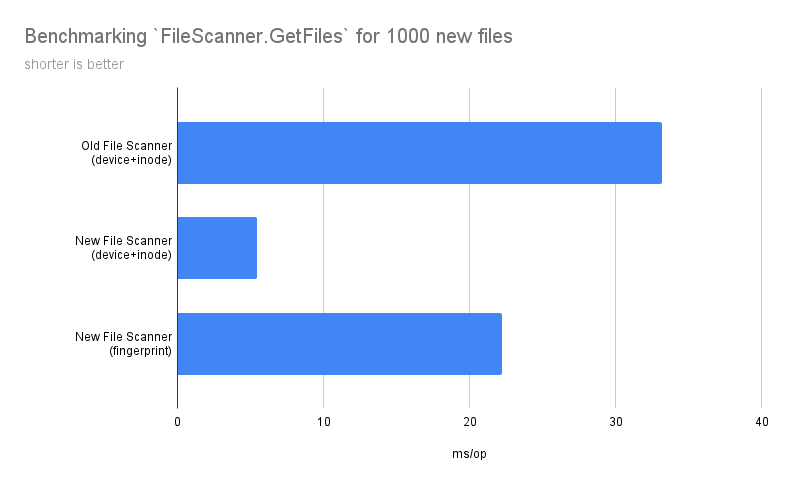
There are several conclusions to draw here:
- By making the above-mentioned optimizations in File Scanner, it got an 84% boost in performance.
- The new fingerprint mode is 76% slower than the default device_id+inode mode in the NEW scanner, which makes it 8% faster than the default mode in the OLD File Scanner. So, our customers will experience a faster Filestream even with the fingerprint mode enabled.
- Neither the hashing algorithm nor the fingerprint length contribute that much to the overall performance — most of the time is spent on opening and closing files for reading. So, the defaults for fingerprint mode seem to be alright.
Conclusion
This new fingerprint mode solves a lot of issues with unstable metadata on file systems and, compared to the previous version of Filebeat, it’s even faster than the default mode.
Also, the default mode got much faster in the new Filebeat release, so it seems very beneficial to refactor some old code from time to time and run benchmarks/profiling to see how the performance changed.
We’ll continue to focus on the performance of Filebeat. Stay tuned.
What else is new in Elastic 8.10? Check out the 8.10 announcement post to learn more.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print