Leveling up your observability practice — Part 1
Moving to observability maturity

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
What separates the observability experts from the novices? It's a question that's been on my mind lately, especially after diving into our recent 2024 State of Observability Survey of over 500 practitioners. In my past roles as a DevOps engineer and a site reliability engineer (SRE), I've seen firsthand how a mature observability practice can be the difference between sleepless nights and smooth sailing.
In the first part of this blog, let’s look at insights into how the industry is doing in terms of observability maturity and the possible payoffs you might expect. In part two, we will deal with the challenges preventing teams from getting to observability maturity, practical advice on how to get there, and finally, the role of leadership in supporting team efforts to reach maturity and higher performance.
Let's unpack what the data tells us and explore how to level up observability maturity.
The observability maturity spectrum
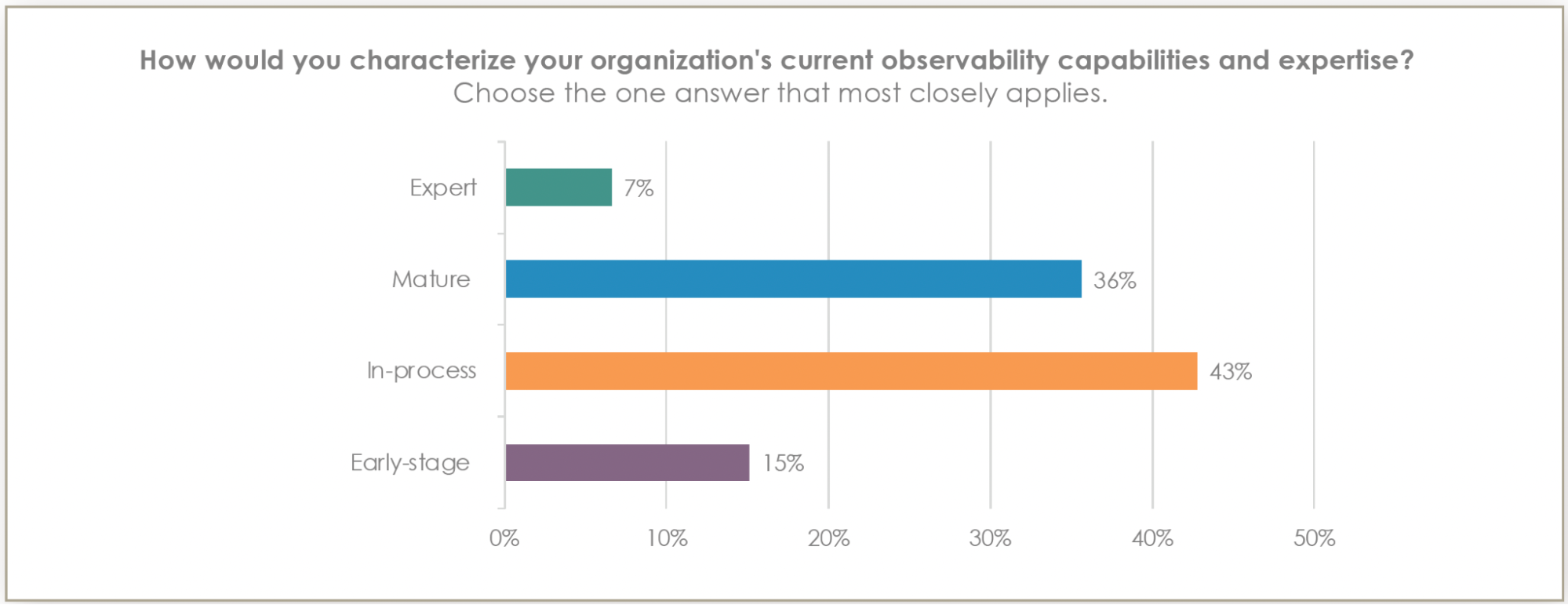
First, let's look at the 2024 State of Observability survey and see where the industry stands in terms of maturity:
Only 7% classify themselves as experts
36% consider their practice mature
43% are in the process of improving
15% are in the early stages
Expert teams make data-driven decisions
The vast majority of teams find themselves still climbing the maturity ladder with a mere 7% of organizations considering themselves experts in the field. These pioneers have mastered not only the technical aspects of observability but also successfully embedding it into their organizational culture — making data-driven decisions a default rather than an aspiration.
What's particularly interesting is that just over a third of organizations — specifically 36% — consider their practice mature. These teams have established solid foundations but recognize there's still room for growth. They've typically mastered the basics of collecting telemetry data across their systems, implemented robust alerting mechanisms, and established clear incident response procedures. The next step for these organizations often involves deepening their analysis capabilities and automating more of their observability workflows.
The largest segment — representing 43% of organizations — finds themselves in the midst of their observability journey. These teams are actively working to enhance their capabilities, and this is where some of the most exciting transformations occur. Success at this stage often comes from focusing on key fundamentals: establishing consistent logging practices across services, implementing distributed tracing to understand service dependencies, and developing clear metrics that align with business objectives. A crucial step for these teams is often the implementation of service level objectives (SLOs) that bridge the gap between technical metrics and business impact.
For those just starting out — representing 15% of organizations — the path ahead offers unique opportunities. While it might feel overwhelming, starting fresh allows you to build on modern best practices from day one. Begin with the basics: identify your most critical services, implement comprehensive logging, and establish baseline metrics for performance and reliability. Focus on building a culture that values observability by involving developers early in the process and making observability a key part of your definition of what’s done for new features. Of particular interest to this group would be starting out with a solid data collection strategy using OpenTelemetry and open standards — a place where more mature organizations would no doubt love to be.
Evolve, learn, and adapt
The beauty of this maturity spectrum lies in its dynamic nature. Organizations aren't static in their position — they're constantly evolving, learning, and adapting. A key strategy for advancement is to focus on incremental improvements: start with one critical service, perfect your observability practices there, and then expand to others. Build a clear taxonomy for your telemetry data early on — consistent naming conventions and metadata tagging will pay dividends as your systems grow more complex.
What's particularly encouraging is the tangible impact that progressing along this spectrum can have on an organization's operational efficiency and reliability. Teams that successfully advance their observability maturity often report dramatic improvements in their ability to detect and resolve issues before they impact users. They're able to make data-driven decisions about capacity planning, performance optimizations, and architectural changes.
The path to higher maturity often involves breaking down silos between development and operations teams. Shared dashboards, collaborative incident post-mortems involving AI, and joint ownership of observability tools can help create a unified approach to system reliability. Consider implementing regular "observability days" where teams can focus on improving their monitoring and alerting configurations or establish "reliability champions" who can help spread best practices across different teams. Good observability is as much about your people as it is about your technology.
The ongoing journey to observability maturity
The key takeaway? No matter where you currently stand on this spectrum, you're part of a larger community working toward the same goal: better, more observable systems that enable us to deliver reliable, performant services to our users. Start where you are; focus on steady progress rather than perfection; try to get the most out of the tools you have; and remember that every improvement in your observability practice brings you closer to more reliable and manageable systems. The journey to observability maturity is exactly that — a journey, not a destination.
So, if you're in that 15% or 43%, don't worry — you're in good company. The journey to observability maturity is ongoing for most of us. But here's the kicker: the benefits of moving up the maturity ladder are substantial.
The payoff of observability maturity
The survey revealed some eye-opening statistics:
78% of mature/expert organizations can typically identify root causes of issues compared to only 35% of early-stage organizations.
Mature practices are half as likely to hear about issues from users first (24% versus 34% for early-stage organizations).
50% of mature/expert teams find cloud technologies easier to manage versus only 17% of early-stage teams.
The numbers around observability maturity paint a compelling picture that many SREs will find both validating and motivating. Our observability maturity data has revealed some fascinating insights into how organizational maturity in observability translates to tangible operational benefits.
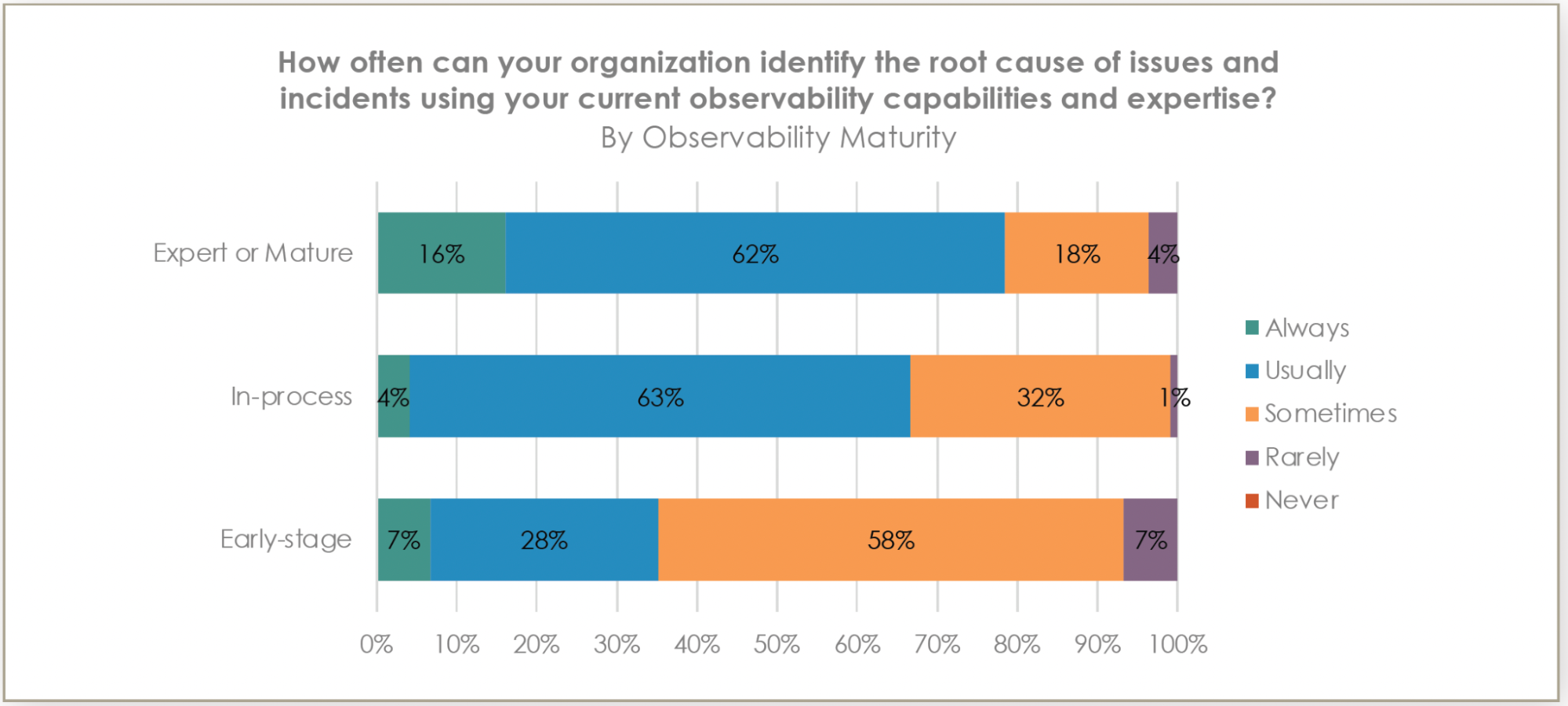
One of the most striking findings is around the ability to identify root causes during incidents. Organizations with mature or expert-level observability practices are significantly more effective at pinpointing issues with 78% reporting successful root cause identification. In contrast, only 35% of early-stage organizations can say the same. This dramatic difference represents countless hours of reduced downtime and streamlined incident response.
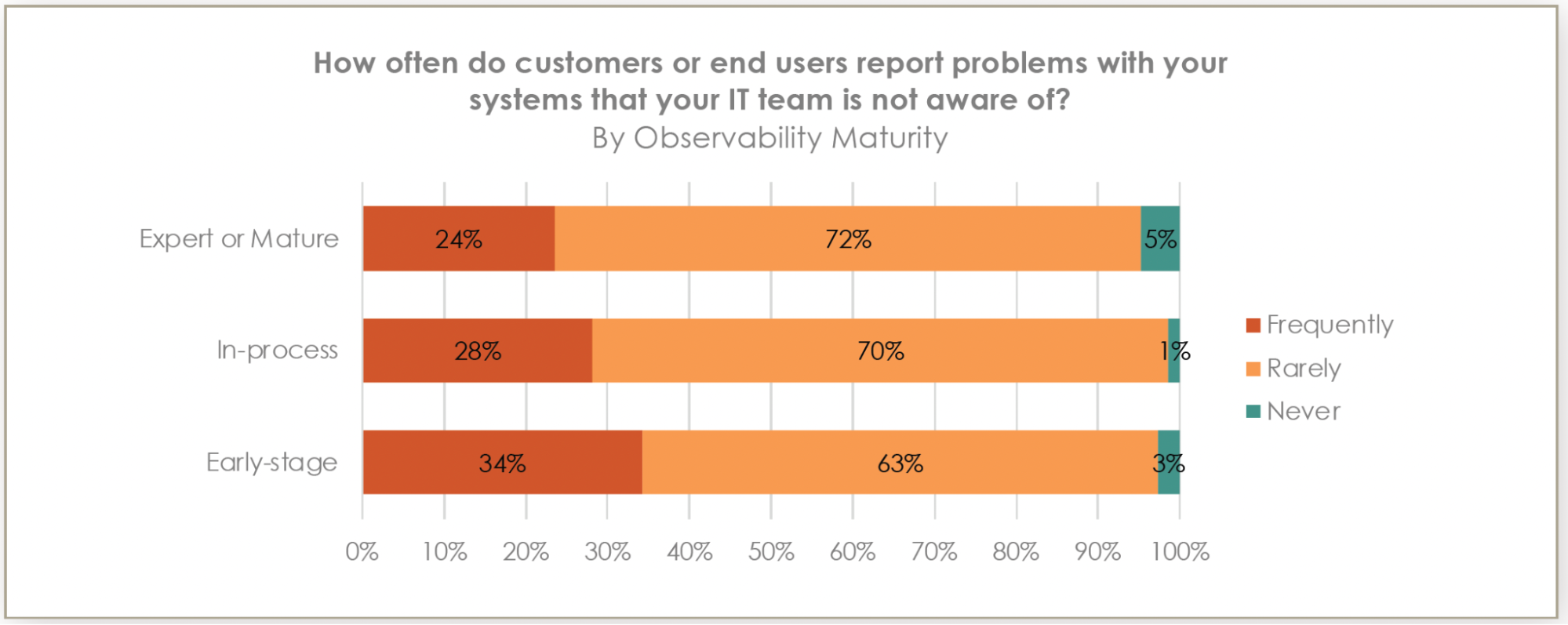
Perhaps equally telling is the shift from reactive to proactive operations that comes with maturity. Mature organizations are substantially less likely to hear about problems from their users first — only 24% compared to 34% for those in early stages. This reduction in user-reported incidents suggests that mature organizations are catching and addressing issues before they impact the end-user experience.
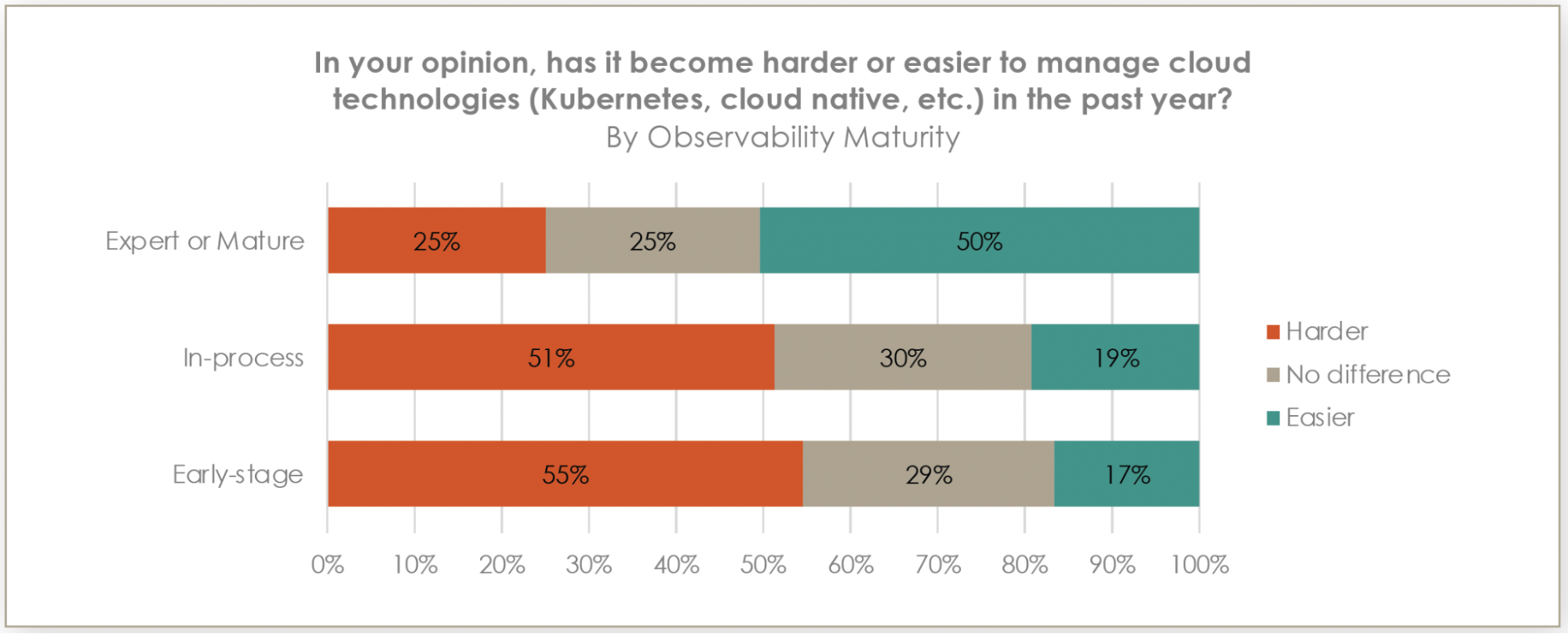
The data becomes even more interesting when we look at cloud infrastructure management. In today's increasingly complex cloud-native landscape, 50% of mature and expert teams report finding cloud technologies easier to manage — while only 17% of early-stage teams share this experience. This stark contrast highlights how robust observability practices can help tame the inherent complexity of modern cloud architectures.
Observability maturity results in operational excellence
The statistics tell a clear story: investing in observability maturity translates directly into operational excellence. Organizations are better positioned to maintain reliable services and respond quickly to emerging issues when they can effectively instrument their systems, correlate telemetry data, and establish meaningful alerting thresholds.
These improvements in observability capability tend to create positive ripple effects throughout an organization. As teams get better at detecting and diagnosing issues, they can spend more time on proactive performance improvements rather than reactive firefighting. This shift often leads to more stable systems, more confident deployments, and better alignment between technical capabilities and business objectives.
While the journey to observability maturity requires significant investment in tools, processes, and cultural changes, the data suggests that these investments pay clear dividends in operational efficiency and service reliability. Each step forward in maturity brings organizations closer to the goal of truly observable systems that can be effectively monitored, debugged, and improved.
The benefits to observability maturity are clear
The observability maturity spectrum reveals a clear picture: while only 7% of organizations have reached expert status, every team is somewhere along this transformative journey. Whether you're among the 15% that are just beginning or the 43% that are actively improving, you're part of a community working toward better and more observable systems. And you’re already likely seeing the benefits and results.
In part two of this blog series, we'll explore the roadblocks and solutions at each stage of maturity, offering practical steps to level up your observability maturity. We'll also examine the crucial role leadership plays in driving observability success. Whether you're struggling with tool sprawl, data silos, or cultural resistance, you'll discover battle-tested strategies to overcome these challenges and advance your organization's observability journey. Check out part two in this blog series.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print