Scaling the Elastic Stack in a Microservices Architecture @ Rightmove
Introduction
Rightmove is the UK's #1 Property Portal. In the process of helping people find the places they want to live, we serve 55 million requests a day and use Elasticsearch to power our searches and provide our teams with useful analytics to help support our applications.
Since 2014, we have been moving over to a microservices architecture. Microservices means more application instances — which in turn means a lot more logs. The old ways of SSHing onto a server and using grep, awk, and sed to diagnose failures was already a pain when we had 90 plus servers to handle, so it was obvious to us that we needed something to pull all our logs together in one place.
Fast forward to 2017 and we have over 50 microservices all sending their logs to our Elasticsearch cluster. In doing so, we needed a way to scale our configuration on both the hardware and application side of things. So how did we achieve this and what did we learn along the way?
Rightmove's Search for a Better Search
In 2014, we were faced with a problem when our existing search engine technology was having issues scaling to fit the needs of our ever growing user base. We decided at that point it was a good time to explore our options and we lined up the contenders to see which one would be the best fit in terms of scalability, performance and features. Elasticsearch quickly rose to the top as not only did it perform around 10 times faster than our old search engine on average, but it also seemed to be very easy to work with and easier for our developers to learn.
The chance to overhaul our search was also one of the things that led us to think about splitting out our old monolithic web applications into a microservices architecture. Since then, we've begun the journey of moving other search-based features (like our sold prices and property email alerts) as well as our customer based reporting and request anomaly detection to Elasticsearch. We have also been able to consider new property search features that would have been much harder to release in our old search technology.
Once we had these microservices and Elasticsearch in our estate, the success of an internal Hackathon led us to the Elastic Stack as a means of pulling in all our application metrics and logs — which has since greatly improved the productivity of our teams when measuring the success of feature releases and debugging and fixing application issues.
Our Elastic Stack Setup
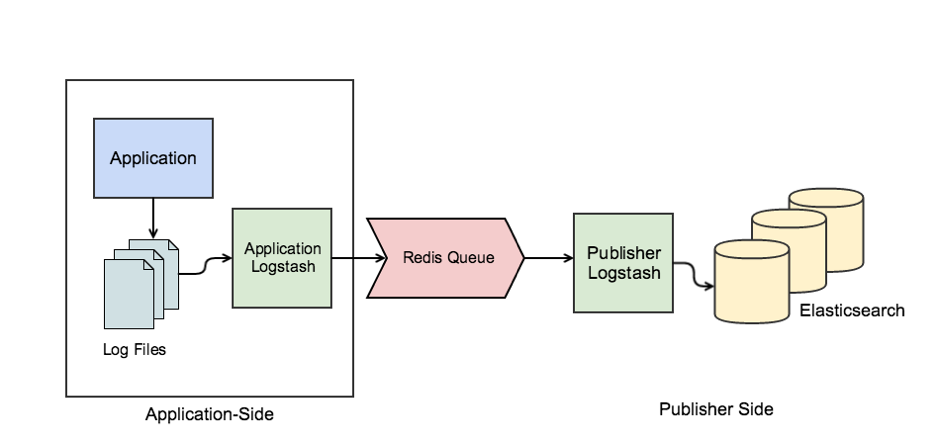
We split our configuration into 3 parts:
- Application side: this is the same for all applications and is repeated on each server that hosts an instance of our application. We also ensure any heavy Logstash parsing is done on this side as this utilizes the distributed power of our application servers rather than causing a processing bottleneck on the publisher Logstash instances.
- Redis cluster for queueing: any queue will do but we use Redis to allow us to buffer the load on Elasticsearch which prevents us losing data due to Bulk rejections.
- Publisher side: this section represents the configuration we use to marshal data from our queue into Elasticsearch. We try to keep Logstash processing to a minimum here.
Installing and Configuring the Elastic Stack
Here are a few things to consider when configuring the Elastic Stack:
- Choose a good configuration management tool. We use Puppet, but any configuration management tool like Chef, Ansible, Salt, etc., will help you scale your cluster deployment and configuration:
- Use Tribe nodes to query multiple clusters across data centres without incurring latency costs.
- https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-tribe.html
- If you are on ES 5.3+ have a look at cross-cluster search as a newer, more scalable alternative to Tribe nodes: https://www.elastic.co/guide/en/elasticsearch/reference/5.x/modules-cross-cluster-search.html
- Use a 'Hot/Warm' architecture to maximize your data retention and keep your indexing fast.
Configuring Logstash
When configuring Logstash to help scaling, we do the following:
- Keep logs consistent across applications by using common logging code. We use an in-house library that allows us to log in the same JSON format across all microservices that use it. This allows us to ingest logs in the same way regardless of the service and support custom key-value metadata and tags to enrich our data in the same way.
- Use correlation IDs in logs to help track log entries across service boundaries.
- Use templates to create Logstash configuration. We store templates for each log type in source-control then populate these with application and environment specific properties by finding and replacing escaped tokens e.g.
input {
file {
path => "${microservice_logs_path}app.log"
type => "${index_prefix}app_log"
codec => json {
charset => "ISO-8859-1"
}
}
- Use deployment pipelines. We use Jenkins to build our configuration as deployable tar files that are stored in Nexus and deployed to each environment by developers at the push of a button in their Jenkins pipelines. This allows us to roll out test configuration to staging and test it there before rolling it out to production.
- Provide a development environment for your developers that mirrors your deployed Elastic Stack. We use Docker compose to simulate our Elastic Stack setup. You can find out how you can set-up a similar setup here: https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
How we use our data
The data collected from our logs is used for various purposes. We use a combination of Kibana, monitoring features, and alerting features with our data as well as some custom UI tools we've built on top of the Elastic Stack in house to help monitor applications.
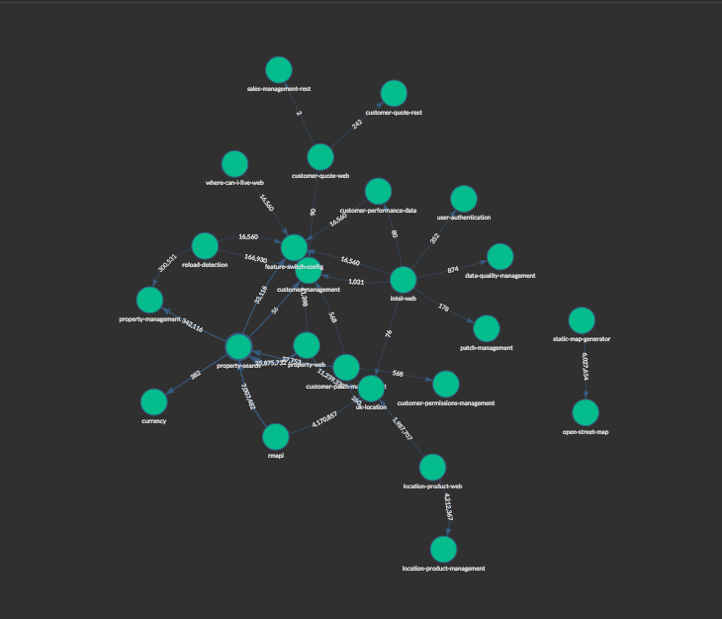
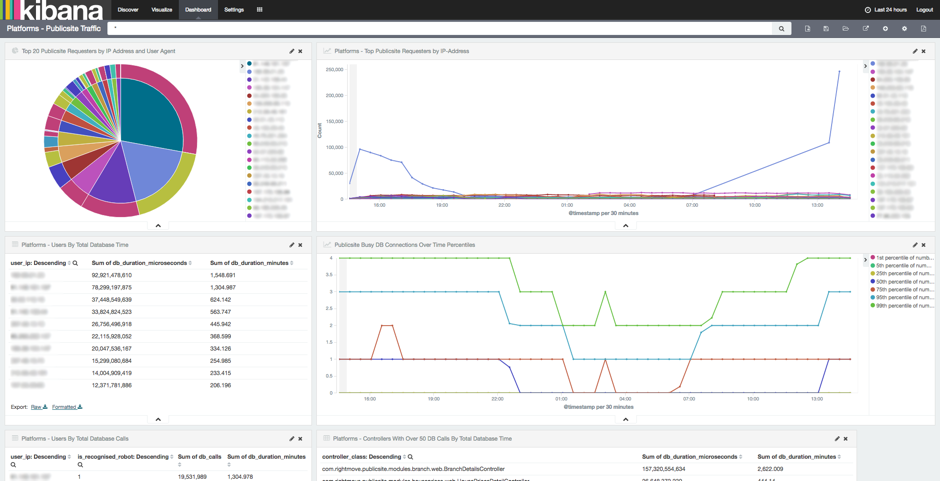 Figure 1 - Scraper and bot detection
Figure 1 - Scraper and bot detection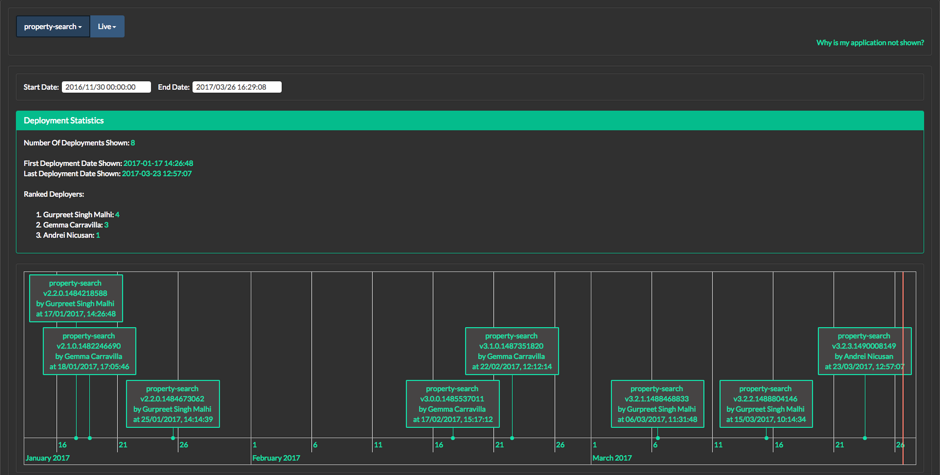
Knowledge Sharing & Internal Advocacy
We learned early on that it's not enough to build the tools for your teams; you also need to educate and sell your teams on why they should want to use them. We did this by hosting events like internal workshops where we taught developers and business folks alike how to use Kibana to create visualizations. Adopting an opt-in approach means that anyone who is interested can learn, and often this allowed business and support team members to get a better idea of how to ask for the data they wanted from the application developers. Attending the official Elastic training, the meetups organised in our area for Elasticsearch and Elastic{ON} events were a big part of what gave our devs confidence to spread the knowledge and help others use the Elastic Stack.
It may sound obvious, but it's also a good idea to be a good example for others. Think about supporting teams with semi-regular monitoring reviews to help them know where they can get data on things they care about and how they can use it. Share graphs and discover tab results from Kibana when production issues occur to help show others how you found a problem and how they could too! Evangelise as much as you can. You'll find that the effort will pay off and you will have an Elastic Stack that people will want to use.
Business outcomes
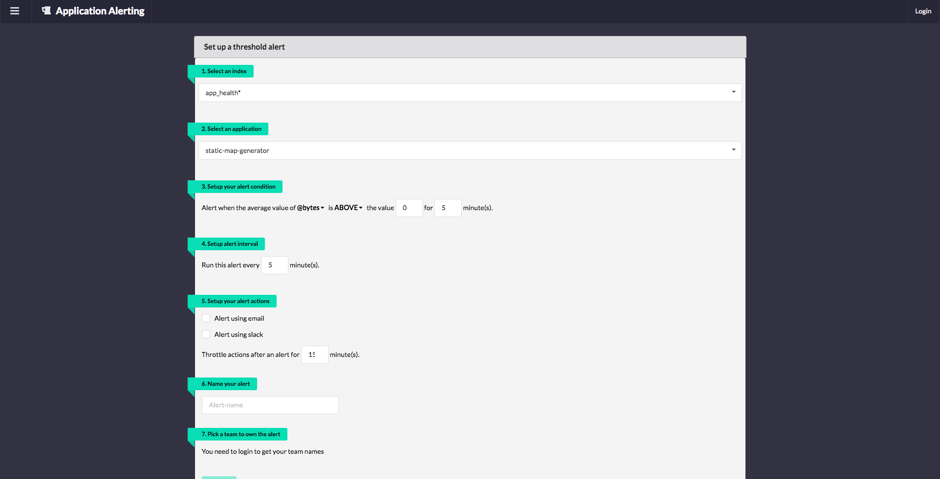
Overall the introduction of the Elastic Stack to our development teams has been transformative. Problems that would have taken developers days to investigate manually are now simple queries in Kibana. Determining correlations between systems that misbehave is easier to check and investigate. Through recording deployments in Elasticsearch and combining with data from our source control systems we are able to show teams what they have released to date and what they would release if they sent out their microservice to production today. Through monitoring traffic and load on our systems we can more accurately predict the need to scale our services. The X-Pack alerting feature will provide us with a self-service platform for our application alerts that allow teams to set up simple threshold based alerts more easily.
Also it's not just our developers that benefit, our support teams can now look up errors and anomalies in systems behaviour via Kibana. This helps spread the load and empowers them to make informed requests of the development teams to allow them to have the right support conversations with some of our customers. Overall the Elastic Stack saves us time and is helping us grow our systems whilst still allowing us to see to their health and, ultimately, address the needs of our users.
Adrian McMichael is an Application Architect and Platforms team member who has spent the last 7 years at Rightmove.co.uk. He enjoys helping build tools for development teams, aiding the design of applications, helping others with monitoring and collecting too many Lego mini-figures.