Significant Terms Aggregation
Strap on your goggles...
In the movie Predator, the alien has a sophisticated thermal imaging system that allows him to single out his human prey by observing the heat differences between their bodies and the environment in which they are hiding.
The new significant terms aggregation behaves like the Predator's vision, identifying interesting things that stand out from the background (not by observing heat differentials but by observing term frequency differentials). Terms of interest in a result set stand out clearly like the heat signal of a monosyllabic Austrian bodybuilder sweating behind a fern.
Revealing the uncommonly common
The trick behind the significant terms aggregation is in spotting terms that are significantly more common in a result set than they are in the general background of data from which they are drawn. These are what you might call uncommonly common terms and examples of the real insights these can give include:
- The words "coil spring" are revealed as a significant cause of the reported failures on a particular car model (the most popular word in the car's fault reports is "the" but that is hardly significant)
- People who liked the movie "Talladega Nights" also liked the movie "Blades of Glory" (their most commonly-liked movie is "Shawshank redemption" but that is irrelevant as this is generally popular)
- Credit cards reporting losses are shown to share a historical payment to an obscure website (the most common payee in their transactions is typically not significant - big merchants such as iTunes are equally popular with non-compromised credit cards)
In the following sections we present worked examples of just some of the useful applications of this new feature:
- Detecting geographic anomalies
- Root cause analysis in fault reports
- Training classifiers
- Revealing badly categorised content
- Detecting credit card fraud
- Making product recommendations
Use case: Geographic anomalies
This XKCD cartoon neatly summarises the issue with the typical forms of mapping analysis:
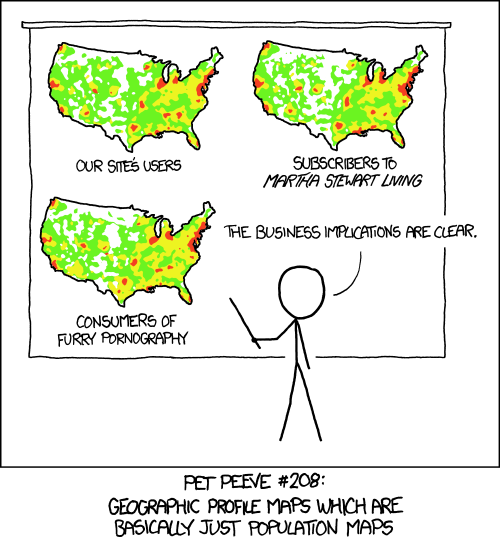
The significant terms aggregation can help overcome this problem.
Let's first take all of the UK crime data for last year and break the reports down into geographic areas using the geohash_grid aggregation and with a simple terms aggregation like this:
curl -XGET "http://localhost:9200/ukcrimes/_search" -d'
{
"query": {
"aggregations" : {
"map" : {
"geohash_grid" : {
"field":"location",
"precision":5,
},
"aggregations":{
"most_popular_crime_type":{"terms":{ "field" : "crime_type", "size" : 1}}
}
}
}
}'
We end up with an XKCD-style map effectively showing us a population distribution and the less-than useful insight that anti-social behaviour is the most popular crime type everywhere:
However, if we use the significant_terms aggregation we can get a more interesting insight into the data and reveal the unusual occurrences of crime in each location:
curl -XGET "http://localhost:9200/ukcrimes/_search" -d'
{
"query": {
"aggregations" : {
"map" : {
"geohash_grid" : {
"field":"location",
"precision":5,
},
"aggregations":{
"weirdCrimes":{"significant_terms":{"field" : "crime_type", "size":1}}
}
}
}
}'
If we show only the top scoring areas, we move away from focusing purely on the most populated areas and the most common crime and begin to find the anomalies in our data:
Here, we see a relatively remote area with a disproportionately large number of Possession of Weapon crimes. If we zoom in, we can see from the sky why this is the case - this is the location of Stansted airport where passengers are routinely searched as they transit through the airport. Other spots around the country have their own curiosities - the fields where drug-related crimes peak as part of annual music festivals, the year-round bicycle thefts from university towns like Cambridge, and the prisons where it would seem a crime conducted against a fellow criminal is not really a crime so is registered with the type Other.
Use case: Root cause analysis
The National Highway Traffic Safety Association maintains a database of car fault reports and, like many systems for fault reports, there is a product ID and a free-text description with each report. Using the significant_terms aggregation you can identify the common reasons for product failures by examining the free-text descriptions of each product.
Example query
curl -XGET "http://localhost:9200/nhtsa/_search" -d'
{
"aggregations" : {
"car_model":{
"terms":{"field" : "car_model", "size" : 20},
"aggregations":{
"reasons_for_failure" : {
"significant_terms":{"field" : "fault_description", "size" : 20}
}
}
}
}
}'
Example results
"aggregations": {
"car_model": {
"buckets": [
{
"key": "Taurus",
"doc_count": 3967,
"reasons_for_failure": {
"doc_count": 3967,
"buckets": [
{
"key": "coil",
"doc_count": 250,
"score": 0.544,
"bg_count": 1115
},
{
"key": "mounts",
"doc_count": 178,
"score": 0.3969,
"bg_count": 777
},
{
"key": "spring",
"doc_count": 261,
"score": 0.3668,
"bg_count": 1706
},
...
To make these keywords a more readable explanation of failures, a useful technique is to display the keywords in context (a technique commonly known by the acronym KWIC). This involves taking the keywords from the results shown above and constructing a terms query with highlighting. Here is an example javascript function to do just this:
Fetching "keywords in context" examples
function getKWIC(car_model,buckets){
var shouldClauses=[];
for(var i=0;i < buckets.length; i++)
{
//Get at least the top 5 significant keywords
if((shouldClauses.length > 5) || (buckets[i].score < 2)) {
shouldClauses.push( {"term" : { "fault_description" : {
"value" : buckets[i].key,
"boost" : buckets[i].score
} }});
}
}
var kwicQuery={
"query" :
{
"bool" : {
"should":shouldClauses,
"must":[{"terms":{"car_model":[car_model]}}]
}
},
"size":30,
"highlight": {
"pre_tags" : ["<span style="background-color: #f7f7a7;">"],
"post_tags" : ["</span>"],
"fields": {"fault_description":{"matched_fields": ["fault_description"] }}
}
};
dataForServer=JSON.stringify(kwicQuery);
var kwResultHtml="";
$.ajax({
type: "POST",
url: '/nhtsa/_search',
dataType: 'json',
async: false,
data: dataForServer,
success: function (data) {
var hits=data.hits.hits;
for (h in hits){
//format results as html table rows
var snippets=hits[h].highlight.fault_description;
kwResultHtml+="<tr><td>";
for(snippet in snippets){
kwResultHtml+="<span>"+snippets[snippet]+"...</span>";
}
kwResultHtml+="</td></tr>";
}
}
});
return kwResultHtml;
}
The results of our root-cause analysis might then appear as follows:
. AS A RESULT OF THE SITUATION, I INCURRED EXPENSE TO REPLACE THE COIL SPRINGS, STRUTS AND UPPER MOUNTS; PLUS...AS I WAS BACKING UP THE FRONT DRIVERS SIDE COIL SPRING BROKE, PUNCTURING THE TIRE. IT IS THE SAME... 2001 FORD TAURUS (48302 ODOMETER) REAR COIL SPRING BROKE REPLACED SPRINGS WITH REAR STRUTS. *NM... WAS BROKE. FORD HAS HAD A HISTORY OF COIL SPRING FAILURES AND SHOULD ISSUE A RECALL ON ALL SPRINGS. *TR...WHILE GETTING A SCHEDULED OIL CHANGE, THE DEALER NOTICED MY COIL SPRING ON THE REAR PASSENGER SIDE... TRECALL CAMPAIGN 04V332000 CONCERNING COIL SPRINGS. THE COIL SPRING BROKE IN THREE PLACES. IT BLEW...
Use case: Training a classifier
Many systems classify documents by assigning tag or category fields. Classifying documents can be a tedious manual process and so in this example we will train a classifier to automatically spot keywords in new documents that suggest a suitable category.
By using The Movie Database (TMDB) data we can search for movies that contain the term vampire in their description:
Example query
curl -XGET "http://localhost:9200/tmdb/_search" -d'
{
"query" : {
"match" : {"overview":"vampire" }
},
"aggregations" : {
"keywords" : {"significant_terms" : {"field" : "overview"}}
}
}'
Example results
"aggregations": {
"keywords": {
"doc_count": 437,
"buckets": [
{
"key": "vampire",
"doc_count": 437,
"score": 3790.9405,
"bg_count": 437
},
{
"key": "helsing",
"doc_count": 17,
"score": 113.9480,
"bg_count": 22
},
{
"key": "dracula",
"doc_count": 33,
"score": 98.3565,
"bg_count": 96
},
{
"key": "harker",
"doc_count": 7,
"score": 42.5023,
"bg_count": 10
},
{
"key": "undead",
"doc_count": 15,
"score": 31.9717,
"bg_count": 61
},
{
"key": "buffy",
"doc_count": 4,
"score": 23.130071721937412,
"bg_count": 6
},
{
"key": "bloodsucking",
"doc_count": 4,
"score": 19.8244,
"bg_count": 7
},
{
"key": "fangs",
"doc_count": 5,
"score": 19.7094,
"bg_count": 11
}
These keywords could then be cherry-picked and added to a new terms query that is registered using the Percolate API to help identify new movies that should potentially be tagged as vampire movies. Note that much of the guesswork in selecting useful keywords is avoided.
Use case: Finding mis-categorized content using the Like this but not this pattern
For systems that have a lot of pre-categorized content it can be useful to identify where the database maintainers have failed to categorize existing content properly. In this example we will start by looking at Reuters news articles tagged with the topic "acquisitions" and use significant_terms aggregation to learn some relevant keywords e.g.:
curl -XGET "http://localhost:9200/reuters/_search" -d'
{
"query" : {
"match" : {"topics":"acq" }
},
"aggregations" : {
"keywords":{"significant_terms" : {"field" : "body", "size" : 20}},
}
}'
The keywords that are revealed as relevant to the "acquisition" news category are as follows:
{
"aggregations": {
"keywords": {
"doc_count": 2340,
"buckets": [
{
"key": "acquisition",
"doc_count": 469,
"score": 0.973,
"bg_count": 704
},
{
"key": "acquire",
"doc_count": 395,
"score": 0.927,
"bg_count": 535
},
{
"key": "shares",
"doc_count": 842,
"score": 0.820,
"bg_count": 2258
},
{
"key": "stake",
"doc_count": 363,
"score": 0.780,
"bg_count": 529
},
{
"key": "inc",
"doc_count": 1220,
"score": 0.752,
"bg_count": 4390
},
{
"key": "merger",
"doc_count": 298,
"score": 0.674,
"bg_count": 416
},
{
"key": "acquired",
"doc_count": 327,
"score": 0.643,
"bg_count": 513
},
...
The next step is to construct a like this but not this query by:
- adding the significant category keywords to a should terms query and
- adding the original category field criteria to a mustNot clause
as follows:
curl -XGET "http://localhost:9200/reuters/_search" -d'
{
"query" : {
"bool": {
"mustNot":[ {"match" : {"topics" : "acq" } }],
"should":[
{ "terms":{"body":["acquisition", "acquire","shares","stake","inc","merger"...]}}
]
}
}
}'
The results of this query are a relevance-ranked list of news articles that should have been tagged as articles about acquisitions but have somehow slipped through the net. Below is an example match which failed to record the "acq" topic tag:
Salomon Brothers Inc said it has acquired 21,978 convertible subordinated debentures of Harcourt... Brace Jovanovich Inc, which it says could be converted into 21,978,000 common shares. In a filing... them into stock. Salomon said it would have a 35.8 pct stake in Harcourt, based on 39.4 mln shares.... Harcourt has said that Salomon and Mutual Shares Corp, a New York investment firm, hold a combined... some or all of their current stake in the market or in negotiated deals,
Use case: detecting credit card fraud
When a bank's customers phone the bank and complain that they have noticed unusual transactions on their account, the bank undertakes a common point of compromise analysis. The unusual transactions that were spotted might be payment for a hotel in a country the customer has not visited but this payment is the symptom of the root problem and not the cause. Somewhere in a customer's credit card history of payments a merchant has deliberately stolen their details (perhaps a card-skimmer installed in a petrol station) or accidentally lost their details (perhaps a website had its database hacked). Either way, this merchant represents a common point of compromise where potentially many card details were obtained and sold on the black market. For the bank, the objective is to identify the problem merchant (or merchants) and identify their customers who may be about to experience fraudulent payments.
The starting query would be to take a selection of compromised cards and look at all of their transactions in the last few months and summarise who they've been paying:
curl -XGET "http://localhost:9200/transactions/_search" -d'
{
"query": {
"terms": {"payer" : [59492167, 203701197, 365610456,....]}
},
"aggregations" : {
"payees":{
"significant_terms":{"field":"payee"},
"aggregations":{ "payers":{"terms":{"field":"payer"}}}
}
}
}'
The set of payers in the query represent our unhappy customers and so the set of transactions that it matches will include a mix of happy payments but crucially the unhappy payments that led to their predicament. By using the significant_terms aggregation on the payee field, we can focus in on the merchants that appear in this fishy set of transactions disproportionately more than they would in a random sampling of predominantly happy customers. This helps tune out the popular merchants that are likely to be common with any random sample of customers and focus in on the likely points of compromise. For the selected fishy merchants, we have a child aggregation of payers so we can see just how many of our unhappy customers traded with this merchant and can visualize this as a social network diagram.
If we only use the simpler terms aggregation we tend to focus on the popular merchants in our set and the culprit is not clear as it is hidden among the commonly common payees:
However when we use the significant_terms aggregation our focus shifts to the uncommonly common connector and the extra stats in the results mean we can report on what percentage of that merchant's transactions lie in this fishy set of transactions:
Now the culprit is much clearer. The fishiest merchant here has 13 of his total of 72 transactions in the problem set, making him our strongest suggestion. The merchant with 3 out of his 19 transactions present in this set may appear simply because the bad merchant's customers are also likely to shop at this neighbouring store. Overlaying geographic and temporal information helps these sorts of investigations and is easy to do by adding extra child aggregations into our queries.
Use case: product recommendation
Product recommendations are often driven by a "people who liked this also like.." type analysis of purchase data. The most powerful recommendation engines use complex algorithms and examine many features of the data but here we will use the significant_terms aggregation to provide reasonable results quickly using a simple set of data. In this example, we will use the publicly available "MovieLens" data. The first task is to index the user ratings data so that there is a single JSON document for each user listing all of the movie IDs they have liked (ratings of 4 stars or over):
{
"user": 6785,
"movie": [12, 3245, 4657, 7567, 55276, 56367...]
}
Now for any given movie we can query for all the people who liked that movie and summarise what other movies they like:
{
"query": { "terms": { "movie": [46970]} },
"aggs": {
"significantMovies": { "significant_terms": { "field": "movie" }},
"popularMovies": { "terms": { "field": "movie" }}
}
}
The above query first selects all fans of the movie with the ID 46970 (Talladega Nights) and then summarises their favourite movies using the terms aggregation to identify the most popular movies and the <code>significant_terms aggregation to find the more insightful "uncommonly common" movies.
The results are as follows:
|
| |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
The terms aggregation looks to focus on movies that are universally popular (and arguably irrelevant) while the <code>significant_terms aggregation has focused in on movies that are particularly more popular with the fans of "Talladega Nights". The top 3 suggestions shown here all feature the star of Talladega Nights, Will Ferrell.
Conclusion
This post illustrates a sample of what can be done with significant_terms. I am excited to see what new insights people will gain from exploring their data using this new perspective. Let us know how you are using it and help us improve the analytic capabilities. Happy hunting!